

Will we have AGI by 2030?
In recent months, the CEOs of leading AI companies have grown increasingly confident about rapid progress:
- OpenAI’s Sam Altman: Shifted from saying in November “the rate of progress continues” to declaring in January “we are now confident we know how to build AGI”1
- Anthropic’s Dario Amodei: Stated in January “I’m more confident than I’ve ever been that we’re close to powerful capabilities… in the next 2-3 years”
- Google DeepMind’s Demis Hassabis: Changed from “as soon as 10 years” in autumn to “probably three to five years away” by January.
Is it just hype? What explains the shift? And could we really have Artificial General Intelligence (AGI)2 by 2028?
In this article, I interrogate these claims. I’ll examine what’s driven recent progress, estimate how far those drivers can continue, and explain why they’re likely to continue for at least four more years.
In particular, while in 2024 progress in LLM chatbots seemed to slow, a new approach started to work: teaching the models to reason using reinforcement learning.
In just a year, this let them surpass human PhDs at answering difficult scientific reasoning questions, and achieve expert-level performance on one-hour coding tasks.
We don’t know how capable AI will become, but extrapolating the recent rate of progress suggests that, by 2028, we could reach AI models with beyond-human reasoning abilities, expert-level knowledge in every domain, and that can autonomously complete multi-week projects, and progress would likely continue from there.
No longer mere chatbots, these ‘agent’ models might soon satisfy many people’s definitions of AGI — roughly, AI systems that match human performance at most knowledge work (see full def in footnotes).2
This means that, while the company leaders are probably overoptimistic, there’s enough evidence to take their position very seriously.
Where we draw the ‘AGI’ line is ultimately arbitrary. What matters is these models could start to accelerate AI research itself, unlocking vastly greater numbers of more capable ‘AI workers’. In turn, sufficient automation could trigger explosive growth and 100 years of scientific progress in 10 — a transition society isn’t prepared for.
While this might sound outlandish, it’s within the range of possibilities many experts think is possible. This article aims to give you a primer on what you need to know to understand why, and also the best arguments against.
I’ve been writing about AGI since 2014. Back then, AGI arriving within five years seemed very unlikely. Today, the situation seems dramatically different. We can see the outlines of how it could work and who will build it.
In fact, the next five years seem unusually crucial. The basic drivers of AI progress — investments in computational power and algorithmic research — cannot continue increasing at current rates much beyond 2030. That means we either reach AI systems capable of triggering an acceleration soon, or progress will most likely slow significantly.
Either way, the next five years are when we’ll find out. Let’s see why.
In a nutshell
- Four key factors are driving AI progress: larger base models, teaching models to reason, increasing models’ thinking time, and building agent scaffolding for multi-step tasks. These are underpinned by increasing computational power to run and train AI systems, as well as increasing human capital going into algorithmic research.
- All of these drivers are set to continue until 2028 and perhaps until 2032.
- This means we should expect major further gains in AI performance. We don’t know how large they’ll be, but extrapolating recent trends on benchmarks suggests we’ll reach systems with beyond-human performance in coding and scientific reasoning, and that can autonomously complete multi-week projects.
- Whether we call these systems ‘AGI’ or not, they could be sufficient to enable AI research itself, robotics, the technology industry, and scientific research to accelerate, leading to transformative impacts.
- Alternatively, AI might fail to overcome issues with ill-defined, high-context work over long time horizons and remain a tool (even if much improved compared to today).
- Increasing AI performance requires exponential growth in investment and the research workforce. At current rates, we will likely start to reach bottlenecks around 2030. Simplifying a bit, that means we’ll likely either reach AGI by around 2030 or see progress slow significantly. Hybrid scenarios are also possible, but the next five years seem especially crucial.
Table of Contents
Get notified of new articles in this guide
This article is part of our new AGI careers guide. Join over 500,000 people on our newsletter to get notified about new articles, as well as jobs and training opportunities in the field.
I. What’s driven recent AI progress? And will it continue?
The deep learning era
In 2022, Yann LeCun, the chief AI scientist at Meta and a Turing Award winner, said:
“I take an object, I put it on the table, and I push the table. It’s completely obvious to you that the object will be pushed with the table…There’s no text in the world I believe that explains this. If you train a machine as powerful as could be…your GPT-5000, it’s never gonna learn about this.”
And, of course, if you plug this question into GPT-4 it has no idea how to answer:
Just kidding. Within a year of LeCun’s statement, here’s GPT-4.
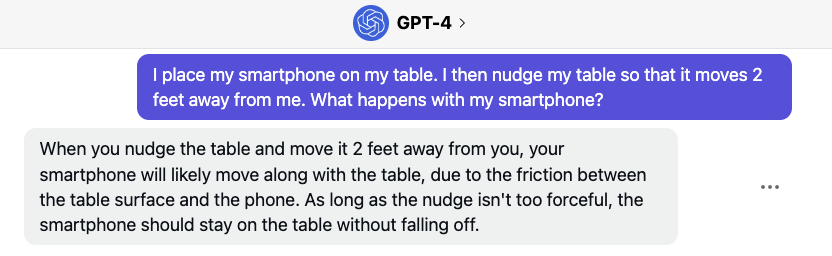
And this isn’t the only example of experts being wrongfooted.
Before 2011, AI was famously dead.
But that totally changed when conceptual insights from the 1970s and 1980s combined with massive amounts of data and computing power to produce the deep learning paradigm.
Since then, we’ve repeatedly seen AI systems going from total incompetence to greater-than-human performance in many tasks within a couple of years.
For example, in 2022, if you asked Midjourney to draw “an otter on a plane using wifi,” this was the result:

Two years later, you could get this with Veo 2:
In 2019, GPT-2 could just about stay on topic for a couple of paragraphs. And that was considered remarkable progress.
Critics like LeCun were quick to point out that GPT-2 couldn’t reason, show common sense, exhibit understanding of the physical world, and so on. But many of these limitations were overcome within a couple of years.
Over and over again, it’s been dangerous to bet against deep learning. Today, even LeCun says he expects AGI in “several years.”3
The limitations of current systems aren’t what to focus on anyway. The more interesting question is: where this might be heading? What explains the leap from GPT-2 to GPT-4, and will we see another?
What’s coming up
At the broadest level, AI progress has been driven by:
- More computational power
- Better algorithms
Both are improving rapidly.
More specifically, we can break recent progress down into four key drivers:
- Scaling pretraining to create a base model with basic intelligence
- Using reinforcement learning to teach the base model to reason
- Increasing test-time compute to increase how long the model thinks about each question
- Building agent scaffolding so the model can complete complex tasks
In the rest of this section, I’ll explain how each of these works and try to project them forward. As chatGPT would say, delve in and you’ll understand the basics of how AI is being improved.
In section two I’ll use this to forecast future AI progress, and finally explain why the next five years are especially crucial.
1. Scaling pretraining to create base models with basic intelligence
Pretraining compute
People often imagine that AI progress requires huge intellectual breakthroughs, but a lot of it is more like engineering. Just do (a lot) more of the same, and the models get better.
In the leap from GPT-2 to GPT-4, the biggest driver of progress was just applying dramatically more computational power to the same techniques, especially to ‘pretraining.’
Modern AI works by using artificial neural nets, involving billions of interconnected parameters organised into layers. During pretraining (a misleading name, which simply indicates it’s the first type of training), here’s what happens:
- Data is fed into the network (such as an image of a cat).
- The values of the parameters convert that data into a predicted output (like a description: ‘this is a cat’).
- The accuracy of those outputs is graded vs. reference data.
- The model parameters are adjusted in a way that’s expected to increase accuracy.
- This is repeated over and over, with trillions of pieces of data.
This method has been used to train all kinds of AI, but it’s been most useful when used to predict language. The data is text on the internet, and LLMs are trained to predict gaps in the text.
More computational power for training (i.e. ‘training compute’) means you can use more parameters, which lets the models learn more sophisticated and abstract patterns in the data. It also means you can use more data.
Since we entered the deep learning era, the number of calculations used to train AI models has been growing at a staggering rate — more than 4x per year.
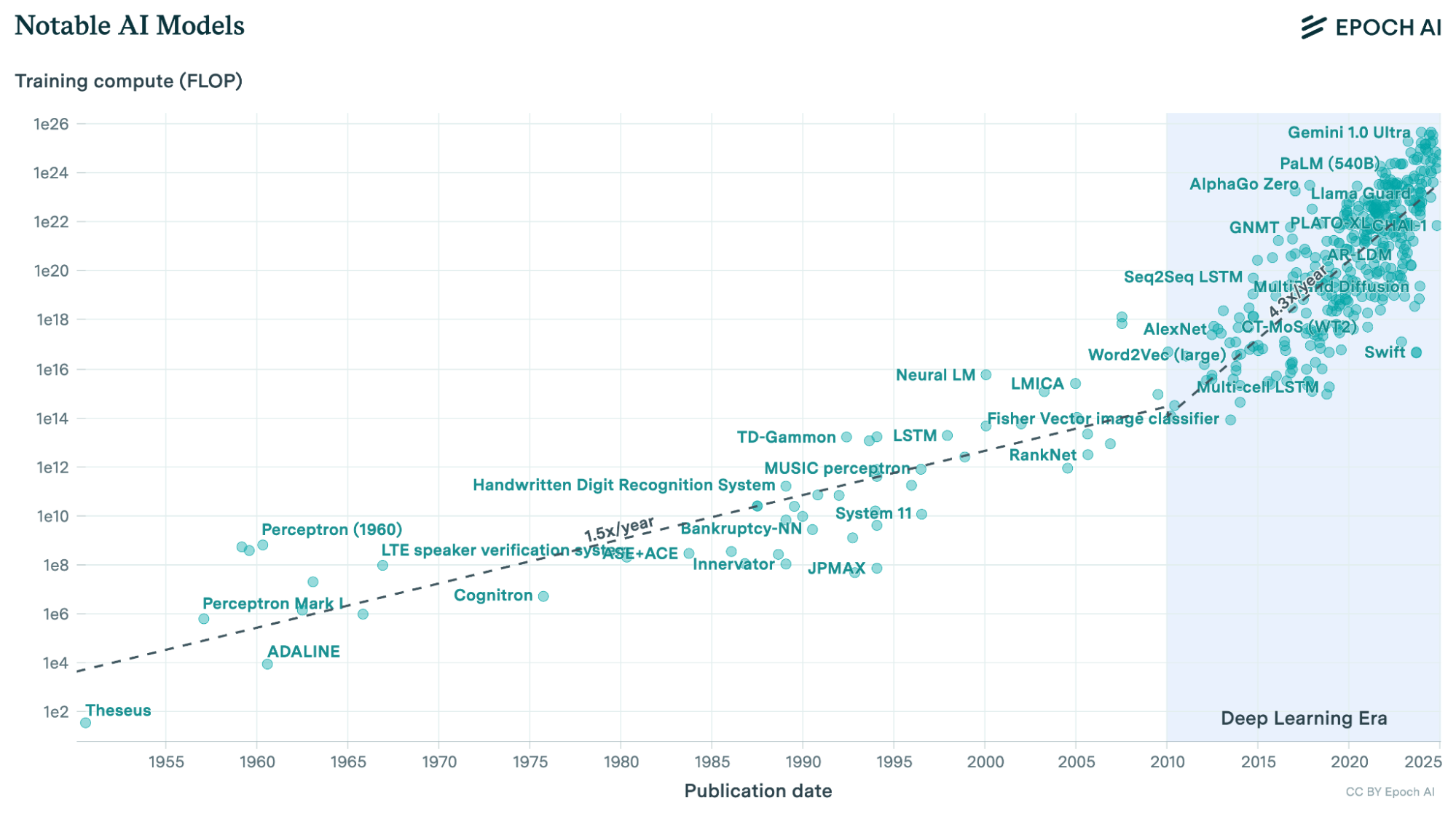
This was driven by spending more money and using more efficient chips.4
Historically, each time training compute has increased 10x, there’s been a steady gain in performance across many tasks and benchmarks.
For example, as training compute has grown a thousandfold, AI models have steadily improved at answering diverse questions—from commonsense reasoning to understanding social situations and physics. This is demonstrated on the ‘BIG-Bench Hard’ benchmark, which features diverse questions specifically chosen to challenge LLMs:

Likewise, OpenAI created a coding model that could solve simple problems, then used 100,000 times more compute to train an improved version. As compute increased, the model correctly answered progressively more difficult questions.5
These test problems weren’t in the original training data, so this wasn’t merely better search through memorised problems.
This relationship between training compute and performance is called a ‘scaling law.’6
Papers about these laws had been published by 2020. To those following this research, GPT-4 wasn’t a surprise — it was just a continuation of a trend.

Algorithmic efficiency
Training compute has not only increased, but researchers have found far more efficient ways to use it.
Every two years, the compute needed to get the same performance across a wide range of models has decreased tenfold.
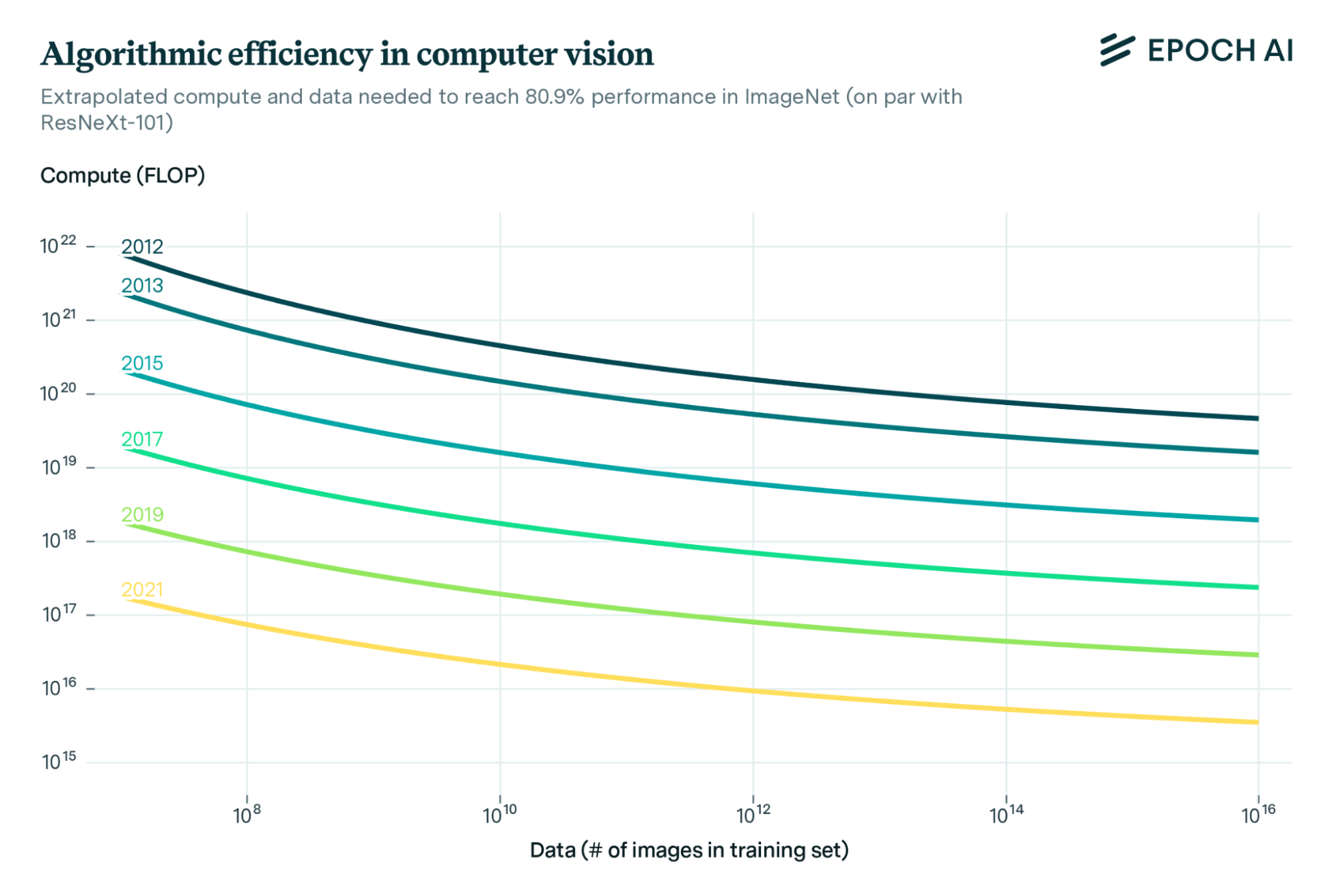
These gains also usually make the models cheaper to run. DeepSeek-V3 was promoted as a revolutionary efficiency breakthrough, but it was roughly on trend: released two years after GPT-4, it’s about 10 times more efficient.7
Algorithmic efficiency means that, not only is four times as much compute used on training each year, but that compute also goes three times further. The two multiply together to produce a 12 times increase in ‘effective’ compute each year.
That means the chips that were used to train GPT-4 in three months could have been used to train a model with the performance of GPT-2 about 300,000 times over.8
This increase in effective compute took us from a model that could just about string some paragraphs together to GPT-4 being able to do things like:
- Beat most high schoolers at college entrance exams
- Converse in natural language — in the long-forgotten past this was considered a mark of true intelligence, a la the Turing test
- Solve the Winograd schemas — a test of commonsense reasoning that in the 2010s was regarded as requiring true understanding9
- Create art that most people can’t distinguish from the human-produced stuff10
How much further can pretraining scale?
If current trends continue, then by around 2028, someone will have trained a model with 300,000 times more effective compute than GPT-4.11
That’s the same increase we saw from from GPT-2 to GPT-4, so if spent on pretraining, we could call that hypothetical model ‘GPT-6.’12
After a pause in 2024, GPT-4.5-sized models appear to be on trend, and companies are already close to GPT-5-sized models, which forecasters expect to be released in 2025.
But can this trend continue all the way to GPT-6?
The CEO of Anthropic, Dario Amodei, projects GPT-6-sized models will cost about $10bn to train.13 That’s still affordable for companies like Google, Microsoft, or Meta, which earn $50–100bn in profits annually.14
In fact, these companies are already building data centres big enough for such training runs15 — and that was before the $100bn+ Stargate project was announced.
Frontier AI models are also already generating over $10bn of revenue,16 and revenue has been more than quadrupling each year, so AI revenue alone will soon be enough to pay for a $10bn training run.
I’ll discuss the bottlenecks more later but the most plausible one is training data. However, the best analysis I’ve found suggests that there will be enough data to carry out a GPT-6 scale training run by 2028.
And even if this isn’t the case, it’s no longer crucial — the AI companies have discovered ways to circumvent the data bottleneck.
2. Post training of reasoning models with reinforcement learning
People often say “ChatGPT is just predicting the next word.” But that’s never been quite true.
Raw prediction of words from the internet produces outputs that are regularly crazy (as you might expect, given that it’s the internet).
GPT only became truly useful with the addition of reinforcement learning from human feedback (RLHF):
- Outputs from the ‘base model’ are shown to human raters.
- The raters are asked to judge which are most useful.
- The model is adjusted to produce more outputs like the helpful ones (‘reinforcement’).
A model that has undergone RLHF isn’t just ‘predicting the next token,’ it’s been trained to predict what human raters find most helpful.
You can think of the initial LLM as providing a foundation of conceptual structure. RLHF is essential for directing that structure towards a particular useful end.
RHLF is one form of ‘post training,’ named because it happens after pretraining (though both are simply types of training).
There are many other kinds of post training enhancements, including things as simple as letting the model access a calculator or the internet. But there’s one that’s especially crucial right now: reinforcement learning to train the models to reason.
This idea is that instead of training the model to do what humans find helpful, it’s trained to correctly answer problems. Here’s the process:
- Show the model a problem with a verifiable answer, like a math puzzle.
- Ask it to produce a chain of reasoning to solve the problem (‘chain of thought’).17
- If the answer is correct, adjust the model to be more like that (‘reinforcement’).18
- Repeat.
This process teaches the LLM to construct long chains of (correct) reasoning about logical problems.
Before 2023, this didn’t seem to work. If each step of reasoning is too unreliable, then the chains quickly go wrong. And if you can’t get close to the answer, then you can’t give it any reinforcement.
But in 2024, as many were saying AI progress had stalled, this new paradigm started to take off.
Consider the GPQA Diamond benchmark — a set of scientific questions designed so that people with PhDs in the field can mostly answer them, but non-experts can’t, even with 30 minutes of access to Google. It contains questions like this:

In 2023, GPT-4 performed only slightly better than random guessing on this benchmark. It could handle the reasoning required for high school-level science problems, but couldn’t manage PhD-level reasoning.
However, in October 2024, OpenAI took the GPT-4o base model and used reinforcement learning to create o1.19
It achieved 70% accuracy — making it about equal to PhDs in each field at answering these questions.
It’s no longer tenable to claim these models are just regurgitating their training data — neither the answers nor the chains of reasoning required to produce them exist on the internet.
Most people aren’t answering PhD-level science questions in their daily life, so they simply haven’t noticed recent progress. They still think of LLMs as basic chatbots.
But o1 was just the start. At the beginning of a new paradigm, it’s possible to get gains especially quickly.
Just three months after o1, OpenAI released results from o3. It’s the second version, named ‘o3’ because ‘o2’ is a telecom company. (But please don’t ask me to explain any other part of OpenAI’s model-naming practices.)
o3 is probably o1 but with even more reinforcement learning (and another change I’ll explain shortly).
It surpassed human expert-level performance on GPQA:
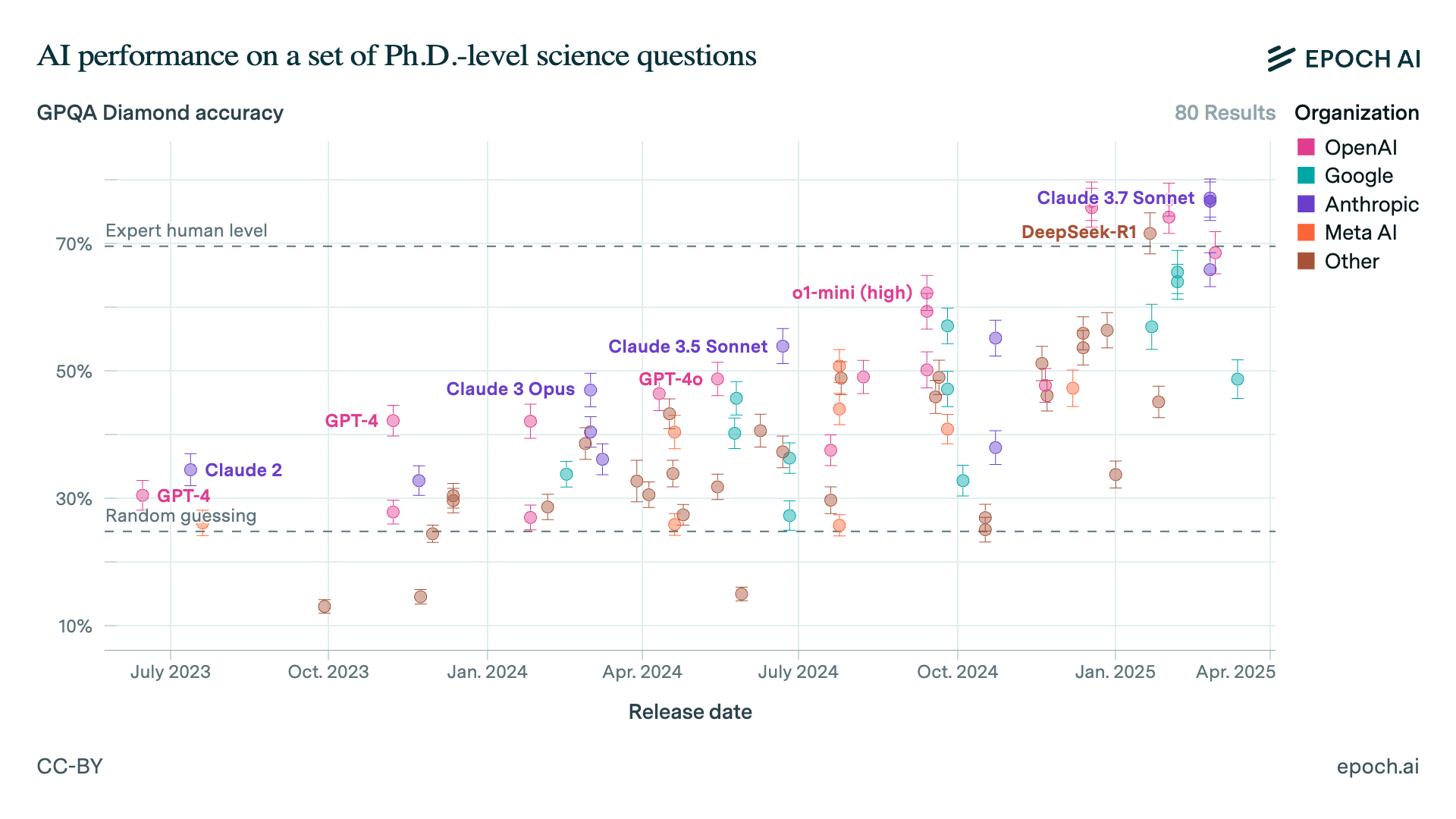
Reinforcement should be most useful for problems that have verifiable answers, such as in science, math, and coding.20 o3 performs much better in all of these areas than its base model.
Most benchmarks of math questions have now been saturated — leading models can get basically every question right.
In response, Epoch AI created Frontier Math — a benchmark of insanely hard mathematical problems. The easiest 25% are similar to Olympiad-level problems. The most difficult 25% are, according to Fields Medalist Terence Tao, “extremely challenging,” and would typically need an expert in that branch of mathematics to solve them.
Previous models, including o1, could hardly solve any of these questions.21 In December 2024, OpenAI claimed that o3 could solve 25%.22
These results went entirely unreported in the media. On the very day of the o3 results announcement, The Wall Street Journal was running this story:

This misses the crucial point that GPT-5 is no longer necessary — a new paradigm has started, which can make even faster gains than before.
How far can scaling reasoning models continue?
In January, DeepSeek replicated many of o1’s results. Their paper revealed that even basically the simplest version of the process works, suggesting there’s a huge amount more to try.
DeepSeek-R1 also reveals its entire chain of reasoning to the user, demonstrating its sophistication and surprisingly human quality: it’ll reflect on its answers, backtrack when wrong, consider multiple hypotheses, have insights, and more.

All of this behaviour emerges out of simple reinforcement learning. OpenAI researcher Sabastian Bubeck observed:
“No tactic was given to the model. Everything is emergent. Everything is learned through reinforcement learning. This is insane.”
The compute for the reinforcement learning stage of training DeepSeek-R1 likely only cost about $1m.
If it keeps working, OpenAI, Anthropic, and Google could now spend $1bn on the same process, approximately a 1000x scale up of compute.23
One reason it’s possible to scale up this much is that the models generate their own data.
This might sound circular, and the idea that synthetic data causes ‘model collapse‘ has been widely discussed.
But there’s nothing circular in this case. You can ask o1 to solve 100,000 math problems, then take only the cases where it got the right answer, and use them to train the next model.
Because the solutions can be quickly verified, you’ve generated more examples of genuinely good reasoning.
In fact, this data is much higher quality than what you’ll find on the internet because it contains the whole chain of reasoning and is known to be correct (not something the internet is famous for).24
This potentially creates a flywheel:
- Have your model solve a bunch of problems.
- Use the solutions to train the next model.25
- The next model can solve even harder problems.
- That generates even more solutions.
- And so on.
If the models can already perform PhD-level reasoning, the next stage would be researcher-level reasoning, and then generating novel insights.
This likely explains the unusually optimistic statements from AI company leaders. Sam Altman’s shift in opinion coincides exactly with the o3 release in December 2024.
Although most powerful in verifiable domains, the reasoning skills developed will probably generalise at least a bit. We’ve already seen o1 improve at legal reasoning, for instance.26
In other domains like business strategy or writing, it’s harder to clearly judge success, so the process takes longer, but we should expect it to work to some degree. How well this works is a crucial question going forward.
3. Increasing how long models think
If you could only think about a problem for a minute, you probably wouldn’t get far.
If you could think for a month, you’ll make a lot more progress — even though your raw intelligence isn’t higher.
LLMs used to be unable to think about a problem for more than about a minute before mistakes compounded or they drifted off topic, which really limited what they could do.
But as models have become more reliable at reasoning, they’ve become better at thinking for longer.
OpenAI showed that you can have o1 think 100 times longer than normal and get linear increases in accuracy on coding problems.
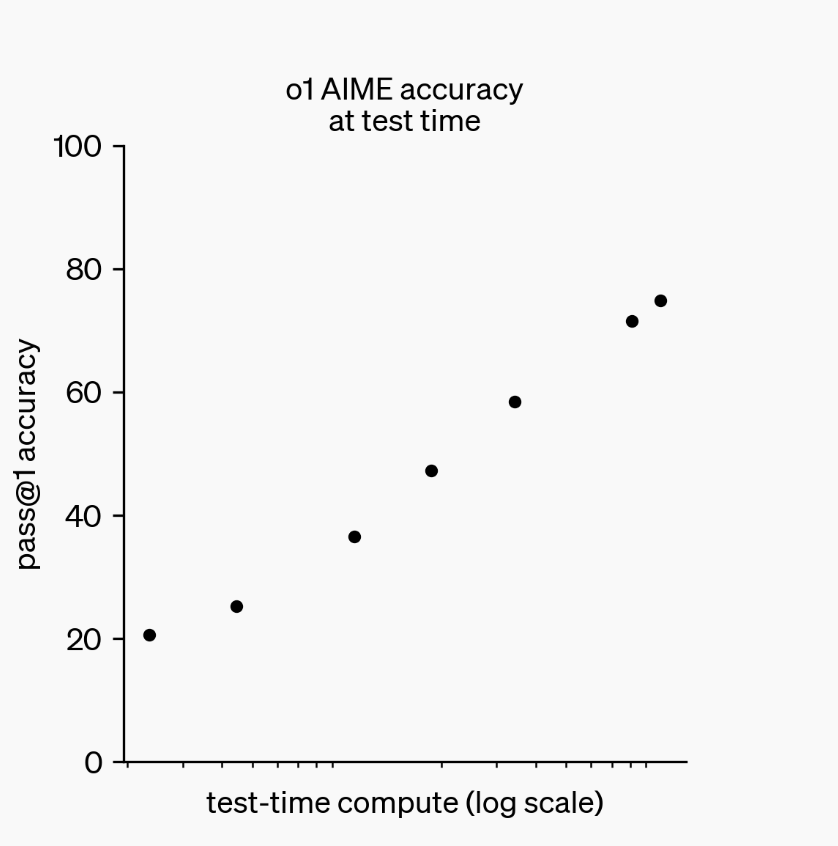
This is called using ‘test time compute’ – compute spent when the model is being run rather than trained.
If GPT-4o could usefully think for about one minute, o1 and DeepSeek-R1 seem like they can think for the equivalent of about an hour.27
As reasoning models get more reliable, they will be able to think for longer and longer.
At current rates, we’ll soon have models that can think for a month — and then a year.
(It’s particularly intriguing to consider what happens if they can think indefinitely—given sufficient compute, and assuming progress is possible in principle, they could continuously improve their answers to any question.)
Using more test time compute can be used to solve problems via brute force. One technique is to try to solve a problem 10, 100, or 1000 times, and to pick the solution with the most ‘votes’. This is probably another way o3 was able to beat o1.28
The immediate practical upshot of all this is you can pay more to get more advanced capabilities earlier.
Quantitatively, in 2026, I expect you’ll be able to pay 100,000 times more to get performance that would have previously only been accessible in 2028.29
Most users won’t be willing to do this, but if you have a crucial engineering, scientific, or business problem, even $1m is a bargain.
In particular, AI researchers may be able to use this technique to create another flywheel for AI research. It’s a process called iterated distillation and amplification, which you can read about here. Here’s roughly how it would work:
- Have your model think for longer to get better answers (‘amplification’).
- Use those answers to train a new model. That model can now produce almost the same answers immediately without needing to think for longer (‘distillation’).
- Now have the new model think for longer. It’ll be able to generate even better answers than the original.
- Repeat.
This process is essentially how DeepMind made AlphaZero superhuman at Go within a couple of days, without any human data.
4. The next stage: building better agents
GPT-4 resembles a coworker on their first day who is smart and knowledgeable, but who only answers a question or two before leaving the company.
Unsurprisingly, that’s also only a bit useful.
But the AI companies are now turning chatbots into agents.
An AI ‘agent’ is capable of doing a long chain of tasks in pursuit of a goal.
For example, if you want to build an app, rather than asking the model for help with each step, you simply say, “Build an app that does X.” It then asks clarifying questions, builds a prototype, tests and fixes bugs, and delivers a finished product — much like a human software engineer.
Agents work by taking a reasoning model and giving it a memory and access to tools (a ‘scaffolding’):
- You tell the reasoning module a goal, and it makes a plan to achieve it.
- Based on that, it uses the tools to take some actions.
- The results are fed back into the memory module.
- The reasoning module updates the plan.
- The loop continues until the goal is achieved (or determined not possible).
AI agents already work a bit.
SWE-bench Verified is a benchmark of real-world software engineering problems from GitHub that typically take about an hour to complete.
GPT-4 basically can’t do these problems because they involve using multiple applications.
However, when put into a simple agent scaffolding:30
- GPT-4 can solve about 20%.
- Claude Sonnet 3.5 could solve 50%.
- And o3 reportedly could solve over 70%.
This means o3 is basically as good as professional software engineers at completing these discrete tasks.
On competition coding problems, it would have ranked about top 200 in the world.
Here’s how these coding agents look in action:
Now consider perhaps the world’s most important benchmark: METR’s set of difficult AI research engineering problems (‘RE Bench’).
These include problems, like fine-tuning models or predicting experimental results, that engineers tackle to improve cutting-edge AI systems. They were designed to be genuinely difficult problems that closely approximate actual AI research.
A simple agent built on o1 and Claude 3.5 Sonnet is better than human experts when given two hours.
This performance exceeded the expectations of many forecasters (and o3 hasn’t been tested yet).31
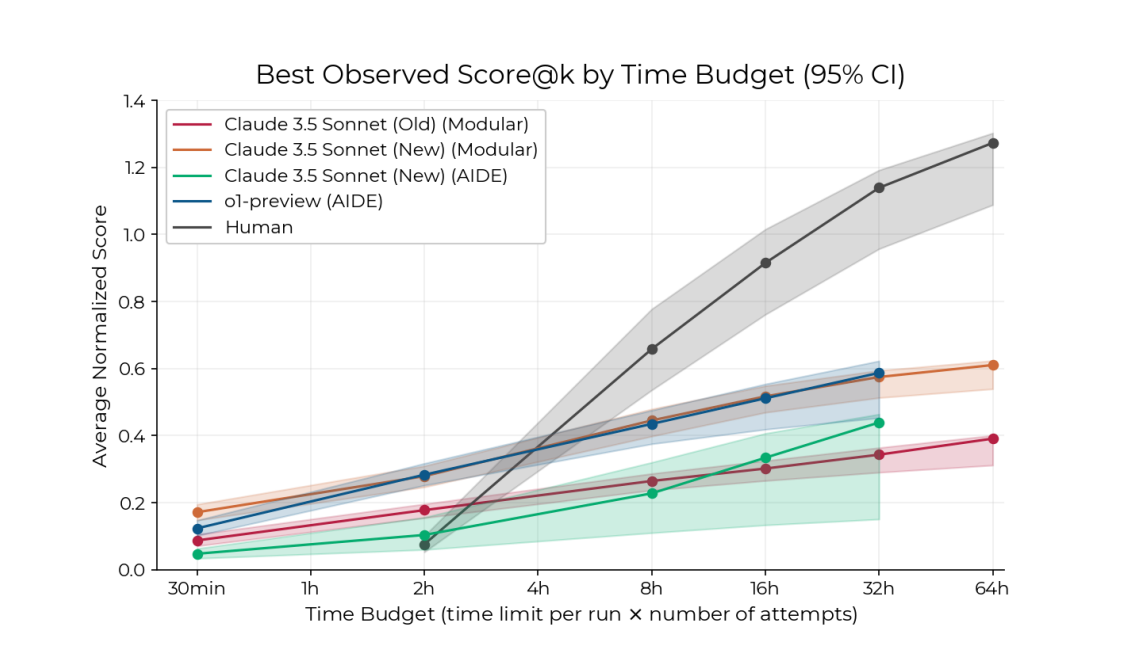
AI performance increases more slowly than human performance when given more time, so human experts still surpass the AIs at around the four hour mark.
But the AI models are catching up fast.
GPT-4o was only able to do tasks which took humans about 30 minutes.32
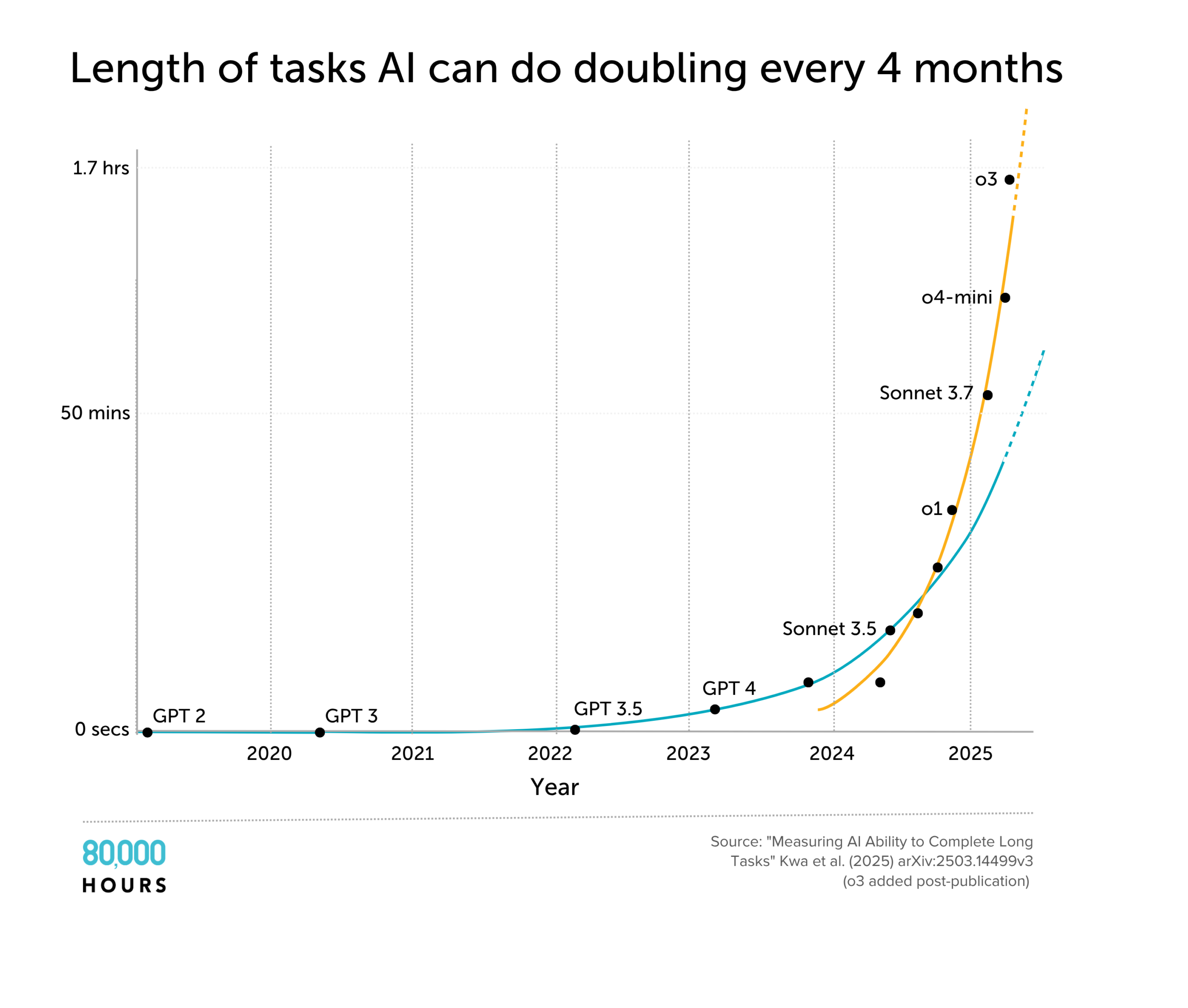
METR made a broader benchmark of computer use tasks categorised by time horizon. GPT-2 was only able to do tasks that took humans a few seconds; GPT-4 managed a few minutes; and the latest reasoning models could do tasks that took humans just under an hour.
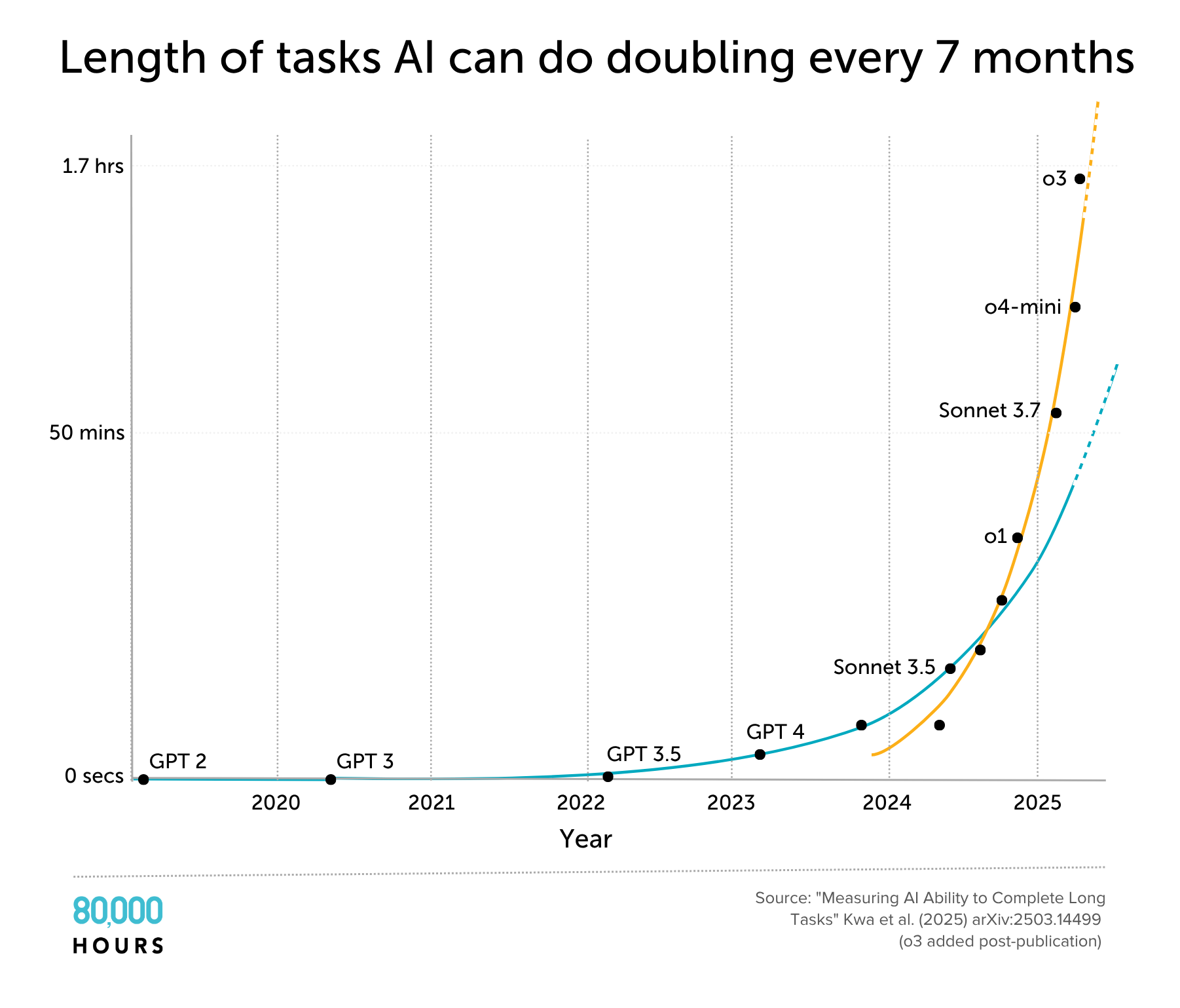
If this trend continues to the end of 2028, AI will be able to do AI research & software engineering tasks that take several weeks as well as many human experts.
The orange line shows that the trend in the last year has been even faster, perhaps due to the reasoning models paradigm.
Update April 2025: After this article was first published, results for o3 were released and it appears to be on the faster post-2024 trend rather than the slower post-2020 trend discussed above. If this continues, then progress would be almost twice as fast: time horizon doubling every four months rather than every seven.
If this faster trend is indeed due to the scale up of reinforcement learning, it probably can’t continue at recent rates for more than 1-2 years, so we might see another 1-2 years of 4 month doubling times, followed by a reversion to the previous 7 month trend.
Alternatively, this could be the start of a positive feedback loop, leading to hyperexponential progress.
AI models are also increasingly understanding their context — correctly answering questions about their own architecture, past outputs, and whether they’re being trained or deployed — another precondition for agency.
On a lighter note, while Claude 3.7 is still terrible at playing Pokemon, it’s much better than 3.5, and just a year ago, Claude 3 couldn’t play at all.
These graphs above explain why, although AI models can be very ‘intelligent’ at answering questions, they haven’t yet automated many jobs.
Most jobs aren’t just lists of discrete one hour tasks –– they involve figuring out what to; do coordinating with a team; long, novel projects with a lot of context, etc.
Even in one of AI’s strongest areas — software engineering –– today it can only do tasks that take under an hour. And it’s still often tripped up by things like finding the right button on a website. This means it’s a long way from being able to fully replace software engineers.
However, the trends suggest there’s a good chance that soon changes. An AI that can do 1-day or 1-week tasks would be able to automate dramatically more work than current models. Companies could start to hire hundreds of ‘digital workers’ overseen by a small number of humans.
How far can the trend of improving agents continue?
OpenAI dubbed 2025 the “year of agents.”
- While AI agent scaffolding is still primitive, it’s a top priority for the leading labs, which should lead to more progress.
- Gains will also come from hooking up the agent scaffolding to ever more powerful reasoning models — giving the agent a better, more reliable ‘planning brain.’
- Those in turn will be based on base models that have been trained on a lot more video data, which might make the agents much better at perception — a major bottleneck currently.
Once agents start working a bit, that unlocks more progress:
- Set an agent a task, like making a purchase or writing a popular tweet. Then if it succeeds, use reinforcement learning to make it more likely to succeed next time.
- In addition, each successfully completed task can be used as training data for the next generation of agents.
The world is an unending source of data, which lets the agents naturally develop a causal model of the world.33
Any of these measures could significantly increase reliability, and as we’ve seen several times in this article, reliability improvements can suddenly unlock new capabilities:
- Even a simple task like finding and booking a hotel that meets your preferences requires tens of steps. With a 90% chance of completing each step correctly, there’s only a 10% chance of completing 20 steps correctly.
However with 99% reliability per step, the overall chance of success leaps from 10% to 80% — the difference between not useful to very useful.
So progress could feel quite explosive.
All this said, agency is the most uncertain of the four drivers. We don’t yet have great benchmarks to measure it, so while there might be a lot of progress at navigating certain types of task, progress could remain slow on other dimensions. A few significant areas of weakness could hamstring AI’s applications. More fundamental breakthroughs might be required to make it really work.
None-the-less, recent trends and the above improvements in the pipeline mean I expect to see significant progress.
II. How good will AI become by 2030?
The four drivers projected forwards
Let’s recap everything we’ve covered so far. Looking ahead at the next two years, all four drivers of AI progress seem set to continue and build on each other:
- A base model trained with 500x more effective compute than GPT-4 will be released (‘GPT-5’).
- That model could be trained to reason with up to 100x more compute than o1 (‘o5’).
- It’ll be able to think for the equivalent of a month per task when needed.
- It’ll be hooked up to an improved agent scaffolding and further reinforced to be more agentic.
And that won’t be the end. The leading companies are on track to carry out $10bn training runs by 2028. This would be enough to pretrain a GPT-6-sized base model and do 100x more reinforcement learning (or some other combination).34
In addition, new drivers like reasoning models appear roughly every 1–2 years, so we should project at least one more discovery like this in the next four years. And there’s some chance we might see a more fundamental advance more akin to deep learning itself.
| Driver of progress | 2019–2023 | 2024–2028 |
|---|---|---|
| Scaling pretraining effective compute | 12x per year 300,000x total GPT-2 to GPT-4 | 12x per year 300,000x total GPT-4 to GPT-635 |
| Post training | RLHF, CoT, tool use | RL on reasoning models 40,000x scale up?36 |
| Thinking for longer | Doesn’t work well | Think 100,000x longer on high-value tasks |
| Agents | Mostly don’t work | 1h to multi-week tasks? |
| A new driver or paradigmatic advance | RLHF, CoT, RL reasoning models, basic agent scaffolding started working. | ??? Rapidly growing compute & AI workforce means more discoveries are likely. |
Putting all this together, people who picture the future as ‘slightly better chatbots’ are making a mistake. Absent a major disruption,37 progress is not going to plateau here.
The multi-trillion dollar question is how advanced AI will get.
Trend extrapolation of AI capabilities
Ultimately no-one knows, but one way to get a more precise answer is to extrapolate progress on benchmarks measuring AI capabilities.
Since all the drivers of progress are continuing at similar rates to the past, we can roughly extrapolate the recent rate of progress.38
Here’s a summary of all the benchmarks we’ve discussed (plus a couple of others) and where we might expect them to be in 2026:
| Benchmark | State-of-art performance in 2022 | State-of-art performance at end of 2024 | Rough trend extrapolation to end of 2026 |
|---|---|---|---|
| MMLU: compilation of college and professional knowledge tests | PaLM 69% | ~90% (saturated)39 | Saturated |
| BIG-Bench Hard: problems from common sense reasoning to physics to social bias, chosen to be especially hard for LLMs in 2021 | ~70%40 | ~90% (saturated) | Saturated |
| Humanity’s last exam: a compilation of 3,000 even harder questions at the frontier of human knowledge. | <3%41 | 9% | Already 25% Feb 2025. 40% to Saturated? |
| SWE-bench Verified: real world github software engineering problems that mostly take less than one hour to complete | <10% | 70% (Approx human expert-level) | Saturated |
| GPQA Diamond: PhD level science questions designed to be Google-proof | Random guessing (25%) | ~90% (above PhD in relevant discipline) | Saturated |
| MATH: High school math competition questions | 50% | 100% | 100% |
| FrontierMath: Math questions that require professional mathematicians in the relevant area | 0% | 25% | 50% to Saturated? |
| RE-bench: seven difficult AI research engineering tasks | Can't do any | Better than experts with two hours | Better than experts with 10–100 hours |
| METR Time horizon benchmark: SWE, cybersecurity, and AI engineering tasks | Tasks humans can do in 1min | Tasks humans can do in 30 min | Tasks humans can do in 6hr |
| Situational Awareness: questions designed to test if model understands itself and context | <30% | 60% | 90%? |
This implies that in two years we should expect AI systems that:
- Have expert-level knowledge of every field
- Can answer math and science questions as well as many professional researchers
- Are better than humans at coding
- Have general reasoning skills better than almost all humans
- Can autonomously complete many day long tasks on a computer
- And are still rapidly improving
The next leap might take us into beyond-human-level problem solving — the ability to answer as-yet-unsolved scientific questions independently.
What jobs would these systems be able to help with?
Many bottlenecks hinder real-world AI agent deployment, even for those that can use computers. These include regulation, reluctance to let AIs make decisions, insufficient reliability, institutional inertia, and lack of physical presence.42
Initially, powerful systems will also be expensive, and their deployment will be limited by available compute, so they will be directed only at the most valuable tasks.
This means most of the economy will probably continue pretty much as normal for a while. You’ll still consult human doctors (even if they use AI tools), get coffee from human baristas, and hire human plumbers.
However, there are a few crucial areas where, despite these bottlenecks, these systems could be rapidly deployed with significant consequences.
Software engineering
This is where AI is being most aggressively applied today. Google has said about 25% of their new code is written by AIs. Y Combinator startups say it’s 95%, and that they’re growing several times faster than before.
If coding becomes 10x cheaper, we’ll use far more of it. Maybe fairly soon, we’ll see billion-dollar software startups with a small number of human employees and hundreds of AI agents. Several AI startups have already become the fastest-growing companies of all time.

So this narrow application of AI could produce hundreds of billions of dollars of economic value pretty quickly — sufficient to fund continued AI scaling.
AI’s application to the economy could expand significantly from there. For instance, Epoch estimate that perhaps a third of work tasks can be performed remotely through a computer, and automation of those could more than double the economy.
Scientific research
The creators of AlphaFold already won the Nobel Prize for designing an AI that solves protein folding.
AI models have also found hundreds of thousands of stable crystals that could be used in material science and created faster and more accurate weather forecasts.43 I expect many more results like this once scientists have adapted AI to solve specific problems, for instance by training on genetic or cosmological data.
Future models might be able to have genuinely novel insights simply by someone asking them. But, even if not, a lot of science is amenable to brute force. In particular, in any domain that’s mainly virtual but has verifiable answers — such as mathematics, economic modeling, theoretical physics, or computer science — research could be accelerated by generating thousands of ideas and then verifying which ones work.
Even an experimental field like biology is also bottlenecked by things like programming and data analysis, constraints that could be substantially alleviated.
A single invention like nuclear weapons can change the course of history, so the impact of any speed up here could be dramatic.
AI research
A field that’s especially amenable to acceleration is AI research itself. Besides being fully virtual, it’s the field that AI researchers understand best, have huge incentives to automate, and face no barriers to deploying AI.
Initially, this will look like researchers using ‘intern-level’ AI agents to unblock them on specific tasks or software engineering capacity (which is a major bottleneck), or even help brainstorm ideas.
Later, it could look like having the models read all the literature, generate thousands of ideas to improve the algorithms, and automatically test them in small-scale experiments.
An AI model has already produced an AI research paper that was accepted to a conference workshop. Here’s a list of other ways AI is already being applied to AI research.
Given all this, it’s plausible we’ll have AI agents doing AI research before people have figured out all the kinks that enable AI to do most remote work jobs.
Broad economic application of AI is therefore not necessarily a good way to gauge AI progress — it may follow explosively after AI capabilities have already advanced substantially.
What’s the case against impressive AI progress by 2030?
Here’s the strongest case against in my mind.
First, concede that AI will likely become superhuman at clearly defined, discrete tasks, which means we’ll see continued rapid progress on benchmarks.
But argue it’ll remain poor at ill-defined, high-context, and long-time-horizon tasks.
That’s because these kinds of tasks don’t have clearly and quickly verifiable answers, and so they can’t be trained with reinforcement learning, and they’re not in the training data either.
That means the rate of progress on these kinds of tasks will be slow, and might even hit a plateau.
If you also argue its starting position is weak, then even after 4-6 more years of progress it still might be bad. The METR data shows AI can’t complete many computer use tasks that humans find trivial to do in a couple of minutes, especially at high reliability, and it’s still worse than a 7 year old child at Pokemon.
Second, argue that most knowledge jobs consist significantly of these long-horizon, messy, high-context tasks.
For example, software engineers spend a lot of their time figuring out what to build, coordinating with others, and understanding massive code bases rather than knocking off a list of well-defined tasks. Even if their productivity at coding increases 10x, if coding is only 50% of their work, their overall productivity only roughly doubles.
A prime example of a messy, ill-defined task is having novel conceptual insights, so you could argue this task, which is especially important for unlocking an acceleration, is likely to be the hardest to automate (contrary to others who think AI research might be easier to automate than many other jobs).
In this scenario, we’ll have extremely smart and knowledgeable AI assistants, and perhaps an acceleration in some limited virtual domains (perhaps like mathematics research), but they’ll remain tools, and humans will remain the main economic & scientific bottleneck.
Human AI researchers will see their productivity increase but not enough to start a positive feedback loop – AI progress will remain bottlenecked by novel insights, human coordination, and compute.
These limits, combined with problems finding a business model and the other barriers to deploying AI, will mean the models won’t create enough revenue to justify training runs over $10bn. That’ll mean progress slows massively after about 2028.44 Once progress slows, the profit margins on frontier models collapse, making it even harder to pay for more training.
The primary counterargument is the earlier graph from METR: models are improving at acting over longer horizons, which requires deeper contextual understanding and handling of more abstract, complex tasks. Projecting this trend forward suggests much more autonomous models within four years.
This could be achieved via many incremental advances I’ve sketched,45 but it’s also possible we’ll see a more fundamental innovation arise — the human brain itself proves such capabilities are possible.
Moreover, long horizon tasks can most likely be broken down into shorter tasks (e.g. making a plan, executing the first step etc.). If AI gets good enough at shorter tasks, then long horizon tasks might rapidly start to work too.
This is perhaps the central question of AI forecasting right now: will the horizon over which AIs can act plateau or continue to improve?
Here are some other ways AI progress could be slower or unimpressive:
- Disembodied cognitive labour could turn out not to be very useful, even in science, since innovation arises out of learning by doing across the economy. Broader automation (which will take much longer) is required. Read more.
- Pretraining could have big diminishing returns, so GPT-5 and GPT-6 will be disappointing (perhaps due to diminishing data quality).
- AI will continue to be bad at visual perception, limiting its ability to use a computer (see Moravec’s paradox). More generally, AI capabilities could remain very spiky – weak on dimensions that aren’t yet well understood, and this could limit their application.
- Benchmarks could seriously overstate progress due to issues with data contamination, and the difficulty of capturing messy tasks.
- An economic crisis, Taiwan conflict, other disaster, or massive regulatory crackdown could delay investment by several years.
- There are other unforeseen bottlenecks (cf planning fallacy).
For deeper exploration of the skeptical view, see “Are we on the brink of AGI?” by Steve Newman, “The promise of reasoning models” by Matthew Barnnett, “A bear case: My predictions regarding AI progress,” by Thane Ruthenis, and the Dwarkesh podcast with Epoch AI.
Ultimately, the evidence will never be decisive one way or another, and estimates will rely on judgement calls over which people can reasonably differ. However, I find it hard to look at the evidence and not put significant probability on AGI by 2030.
When do the ‘experts’ expect AGI to arrive?
I’ve made some big claims. As a non-expert, it would be great if there were experts who could tell us what to think.
Unfortunately, there aren’t. There are only different groups, with different drawbacks.
I’ve reviewed the views of these different groups of experts in a separate article.
One striking point is that every group has shortened their estimates dramatically. Today even many AI ‘skeptics’ think AGI will be achieved in 20 years – mid career for today’s college students.
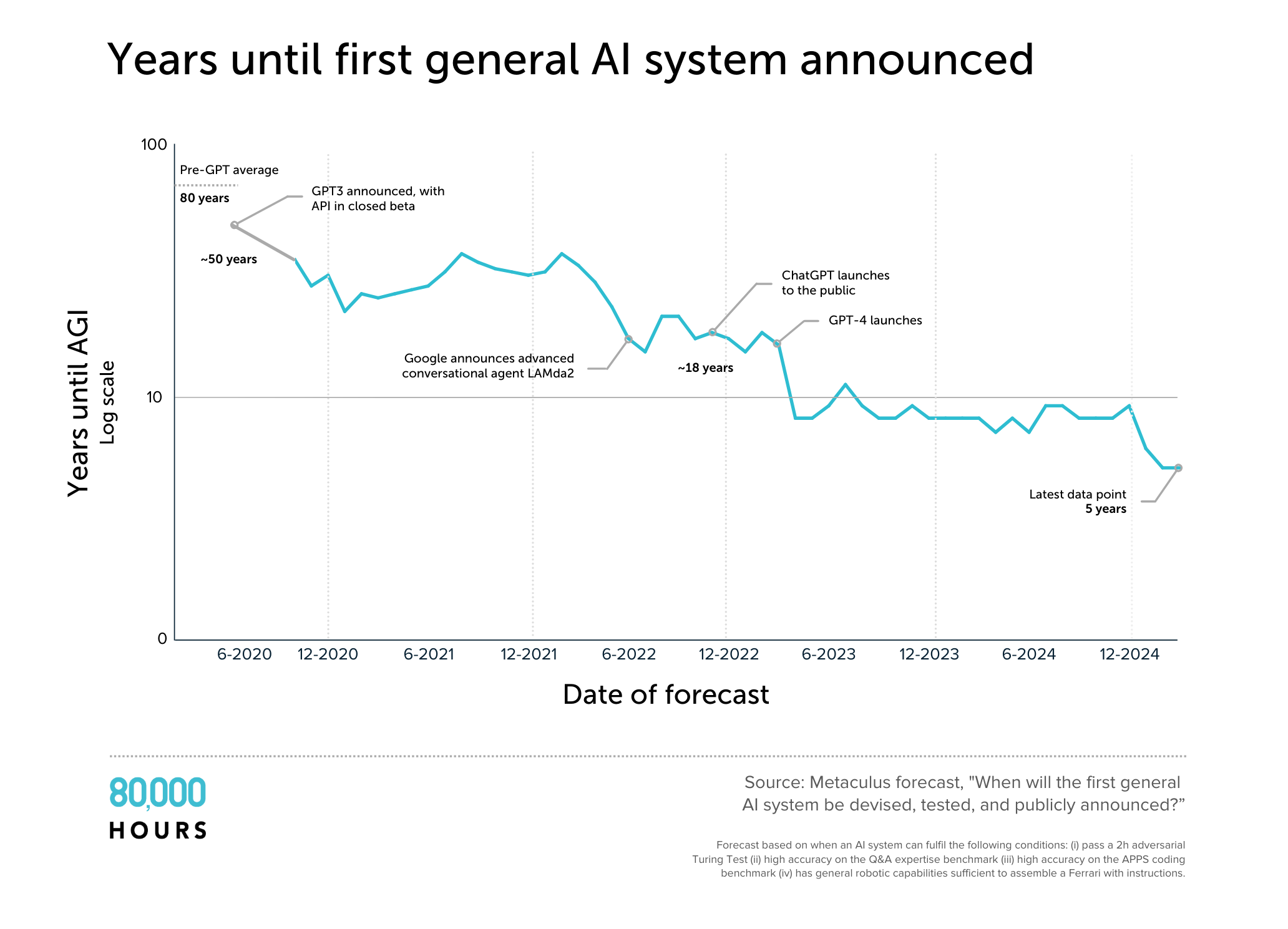
My overall read is that AGI by 2030 is within scope of expert opinion, so dismissing it as ‘sci fi’ is unjustified. Indeed, the people who know the most about the technology seem to have the shortest timelines.
Of course many experts think it’ll take much longer. But if 30% of experts think a plane will explode, and the other 70% think it’ll be fine, as non-experts we shouldn’t conclude it definitely won’t. If something is uncertain, that doesn’t mean it won’t happen.
III. Why the next 5 years are crucial
It’s natural to assume that since we don’t know when AGI will emerge, it might arrive soon, in the 2030s, the 2040s, and so on.
Although it’s a common perspective, I’m not sure it’s right.
The core drivers of AI progress are more compute and better algorithms.
More powerful AI is most likely to be discovered when the compute and labour used to improve AIs is growing most dramatically.
Right now, the total compute available for training and running AI is growing 3x per year,46 and the workforce is growing rapidly too.
This means that each year, the number of AI models that can be run increases 3x. In addition, three times more compute can be used for training, and that training can use better algorithms, which means they get more capable as well as more numerous.
Earlier, I argued these trends can continue until 2028. But now I’ll show it most likely runs into bottlenecks shortly thereafter.
Bottlenecks around 2030
First, money:
- Google, Microsoft, Meta etc. are spending tens of billions of dollars to build clusters that could train a GPT-6-sized model in 2028.
- Another 10x scale up would require hundreds of billions of investment. That’s do-able, but more than their current annual profits and would be similar to another Apollo Program or Manhattan Project in scale.47
- GPT-8 would require trillions. AI would need to become a top military priority or already be generating trillions of dollars of revenue (which would probably already be AGI).
Even if the money is available there will also be bottlenecks such as:
- Power: Current levels of AI chip sales, if sustained, mean that AI chips will use 4%+ of US electricity by 202848, but another 10x scale up would be 40%+. This is possible, but it would require building a lot of power plants.
- Chip production: Taiwan Semiconductor Manufacturing Company (TSMC) manufactures all of the world’s leading AI chips, but its most advanced capacity is still mostly used for mobile phones. That means TSMC can comfortably produce 5x more AI chips than it does now. However, reaching 50x would be a huge challenge. 49
- ‘Latency limitations‘ could also prevent training runs as large as GPT-7.50
So most likely, the rate of growth in compute slows around 2028–2032.
Algorithmic progress is also very rapid right now, but as each discovery gets made, the next one becomes harder and harder. Maintaining a constant rate of progress requires an exponentially growing research workforce.
In 2021, OpenAI had about 300 employees; today, it has about 3,000. Anthropic and DeepMind have also grown more than 3x, and new companies have entered. The number of ML papers produced per year has roughly doubled every two years.51
It’s hard to know exactly how to define the workforce of people who are truly advancing capabilities (vs selling the product or doing other ML research). But if the workforce needs to double every 1–3 years, that can only last so long before the talent pool runs out.52
My read is that growth can easily continue to the end of the decade but will probably start to slow in the early 2030s (unless AI has become good enough to substitute for AI researchers by then).
Algorithmic progress also depends on increasing compute, which enables more experiments. With sufficient compute, researchers can even conduct brute force searches for optimal algorithms. Thus, slowing compute growth will correspondingly slow algorithmic progress.
If compute and algorithmic efficiency increase by just 50% annually rather than 3x, a leap equivalent to the leap from GPT-3 to GPT-4 would take over 14 years instead of 2.5.
It also reduces the probability of discovering a new AI paradigm.
So there’s a race:
- Can AI models improve enough to generate enough revenue to pay for their next round of training before it’s no longer affordable?
- Can the models start to contribute to algorithmic research before we run out of human researchers thrown at the problem?
The moment of truth will be around 2028–2032.
Either progress slows, or AI itself overcomes these bottlenecks, allowing progress to continue or even accelerate.
Two potential futures for AI
If AI capable of contributing to AI research isn’t achieved before 2028–2032, the annual probability of its discovery decreases substantially.
Progress won’t suddenly halt — it’ll slow more gradually. Here are some illustrative estimates of probability of reaching AGI (don’t quote me on the exact numbers!):
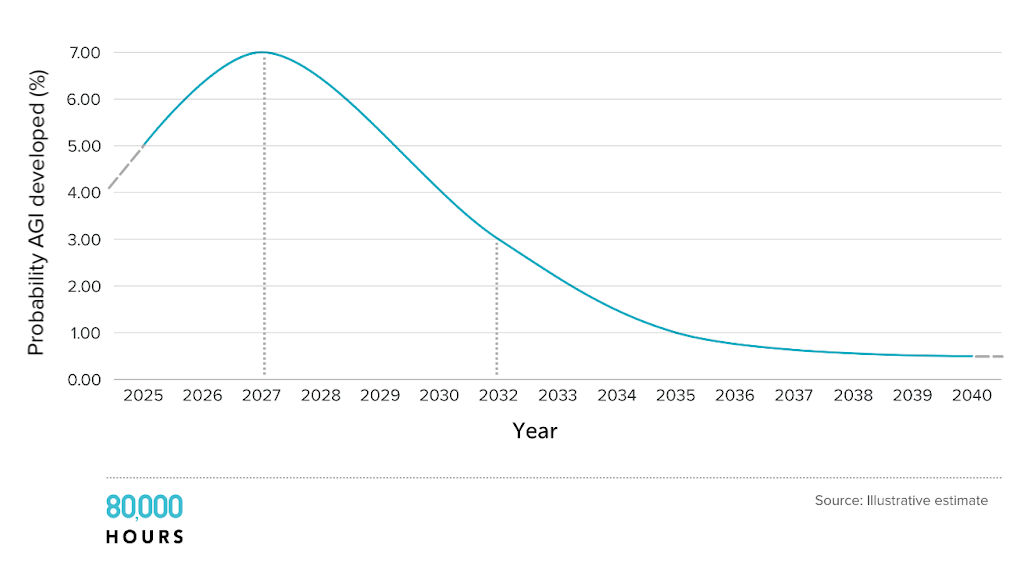
Very roughly, we can plan for two scenarios:53
- Either we hit AI that can cause transformative effects by ~2030: AI progress continues or even accelerates, and we probably enter a period of explosive change.
- Or progress will slow: AI models will get much better at clearly defined tasks, but won’t be able to do the ill-defined, long horizon work required to unlock a new growth regime. We’ll see a lot of AI automation, but otherwise the world will look more like ‘normal’.
We’ll know a lot more about which scenario we’re in within the next few years.
I roughly think of these scenarios as 50:50 — though I can vary between 30% and 80% depending on the day.
Hybrid scenarios are also possible – scaling could slow more gradually, or be delayed several years by a Taiwan conflict, pushing ‘AGI’ into the early 30s. But it’s useful to start with a simple model.
The numbers you put on each scenario also depend on your definition of AGI and what you think will be transformative. I’m most interested in forecasting AI that can meaningfully contribute to AI research.54 AGI in the sense of a model that can do almost all remote work tasks cheaper than a human may well take longer due to a long tail of bottlenecks. On the other hand, AGI in the sense of ‘better than almost all humans at reasoning when given an hour’ seems to be basically here already.
Conclusion
So will we have AGI by 2030?
Whatever the exact definition, significant evidence supports this possibility — we may only need to sustain current trends for a few more years.
We’ll never have decisive evidence either way, but it seems clearly overconfident to me to think the probability before 2030 is below 10%.
Given the massive implications and serious risks, there’s enough evidence to take this possibility extremely seriously.
Today’s situation feels like February 2020 just before COVID lockdowns: a clear trend suggested imminent, massive change, yet most people continued their lives as normal.
In an upcoming article, I’ll argue that AGI automating much of remote work and doubling the economy could be a conservative outcome.
If AI can do AI research, the gap between AGI and ‘superintelligence’ could be short.
This could trigger a massive research workforce expansion, potentially delivering a century’s worth of scientific progress in under a decade. Robotics, bioengineering, and space settlement could all arrive far sooner than commonly anticipated.
The next five years would be the start of one of the most pivotal periods in history.
Use your career to tackle this issue
If you want to help society navigate AGI, here’s what to do:
- Read this primer on AGI careers.
Join our newsletter to receive updates on new articles and jobs.
- Apply to get one-on-one help making a career transition from our team.
Further reading
AI 2027 is the best attempt at a concrete analysis of a scenario in which AGI arrives soon via the automation of AI research. It’s not an attempt to say what’s most likely to happen, but rather an in-depth exploration of a single scenario. However, the team also provide their own all-considered forecasts of several key outcomes in the accompanying research.
Perhaps the most compelling argument for near-term AI progress is Chapter 1 of Situational Awareness of Leopold Aschenbrenner.
The most influential case against near-term AGI is probably The case for multidecade AI timelines by Ege Erdil, published by Epoch AI. Ege and Tamay discussed these ideas on the Dwarkesh podcast in April 2025. (Of course, 30 years is not long in the scheme of history, and Ege still thinks AI will have a transformative effect on society.)
Tomas Pueyo has a more accessible intro covering similar material to this article: The most important time in history is now.
Reinforcement learning works! a podcast by Nathan Labenz is a good explanation of reasoning models, and why they might unlock dramatic progress. Helen Toner adds a useful summary of the debate about how far this will continue.
Epoch AI has a review of all the different ways of forecasting AI. All of them are consistent with AGI arriving before 2030, though some give lower probabilities. (Several of the estimates have also shortened after it was written.)
Epoch AI also has many great datasets that underpin this post. See their key trends page for an overview and their article Can scaling continue through 2030.
An approach to AI forecasting that was popular several years ago is to estimate the compute used to train the human brain, and then estimate when leading AI models might surpass that point (tldr: we might be there around now). See Forecasting transformative AI: the ‘biological anchors’ method in a nutshell by Holden Karnofsky for an introduction.
When do experts expect AGI? is a supplementary article to this post about what we can learn from expert forecasts. Also see Through a glass darkly by Scott Alexander, which explores this topic in further depth.
Here are some of the best articles I’ve seen making the case against transformative AI progress in the next few years: Are we on the brink of AGI? by Steve Newman, The promise of reasoning models by Matthew Barnnett, and A bear case: My predictions regarding AI progress, by Thane Ruthenis, Ege and Tamay on the Dwarkesh podcast, and Why I don’t think AGI is around the corner by Dwarkesh Patel, which argues continuous learning could be a significant bottleneck (though see discussion in the comments). Toby Ord also discusses some reasons for skepticism of AGI before 2030 on our podcast.
Notes and references
- After this article was published, he gave some more specific estimates in a post titled, “The Gentle Singularity“.
2025 has seen the arrival of agents that can do real cognitive work; writing computer code will never be the same. 2026 will likely see the arrival of systems that can figure out novel insights. 2027 may see the arrival of robots that can do tasks in the real world.↩
- There’s no single point at which a system becomes ‘AGI,’ and the term gets used in many different ways.
More fundamentally, we can classify AI systems based on the (i) strength and (ii) breadth of their capabilities.
‘Narrow’ AI demonstrates strong performance at a small range of tasks (e.g. chess-playing AI). Most technologies have very narrow applications.
‘General’ AI is supposed to have strong capabilities in a wide range of domains, in the same way that humans can learn to do a wide range of jobs. But there’s no single point at which narrow becomes general – it’s just a spectrum.
Typically, when people say ‘AGI’ what they have in mind is something like ‘at least human level or better at most cognitive tasks.’ This is roughly what I’ll take it to mean in this article, though I think often my conclusions aren’t sensitive to the exact definition, and often consider several definitions, or try to discuss specific capabilities instead.
An even more general AI could also do non-cognitive tasks; for example, in combination with robotics, it could also do physical tasks.
Usually it’s better to try to forecast specific abilities rather than ‘AGI’. Otherwise, people focus on different definitions of AGI depending on what they think could cause transformative impacts on society. For instance, people who think an acceleration of AI R&D is what matters may focus on a definition they believe is sufficient for that threshold; while someone who thinks what matters is a broad economic acceleration will be more concerned by the ability to do real jobs and robotics.
Bear in mind comparatively narrow systems (e.g. specialised in scientific or AI research) might still be able to cause transformative impacts, so ‘AGI’ might not even be necessary for dramatic social change.
On the other hand, if AIs remain limited to cognitive tasks, they won’t be able to automate the entire chain of production, limiting some of the most dramatic possible outcomes.
Some propose using the term ‘transformative AI’ to get across the idea that what matters is the possibility of transformative effects, rather than generality. I’ve decided to stick with AGI since it’s the most commonly used term, but try to be clear about definitions.
Note definitions of AGI are usually in terms of ‘capabilities,’ i.e. the ability to solve real problems or carry out tasks. Talking about ‘intelligence’ makes people think of these models as having purely intellectual abilities, like a nerdy savant, but companies today are building general-purpose agents which would eventually have good social skills, creativity, the ability to do physical manipulation, and so on. ‘Artificial general competence’ might have been a better name.
You can see a more precise definition in this paper by DeepMind researchers. Morris, Meredith, et al. Levels of AGI: Operationalizing Progress on the Path to AGI. arxiv.org/pdf/2311.02462.↩
- “It’s not centuries. It may not be decades. It’s several years.” Source: Interview at the Johns Hopkins University Bloomberg Center in 2025; time stamp: 27:50.↩
- The increase in training compute was driven by:
- Increased spending (2.5x per year; from Epoch AI Machine Learning Trends; Archived link retrieved 11-Feb-2025)
- Improvements in chip processing power (1.3x per year; from Epoch AI Machine Learning Trends; Archived link retrieved 11-Feb-2025)
- Better adapting of those chips for AI workloads (1.3x per year, extrapolated)↩
- This is shown in Figure 1 and Figure 6 in Chen, Mark, et al. Evaluating Large Language Models Trained on Code. 14 July 2021, arxiv.org/pdf/2107.03374.
OpenAI also made a similar claim in the post on their release of GPT-4. In the section on predictable scaling, they showed that training compute had a predictable relationship with performance on 23 coding challenges over five orders of magnitude.
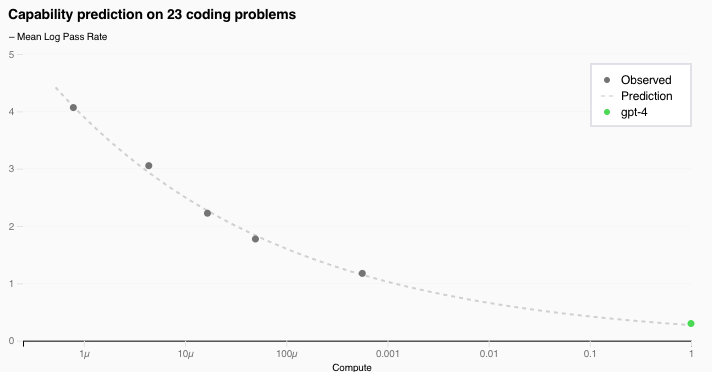
 ↩
↩ - The scaling laws are not technically laws; they’re regularities in the data.
The scaling laws are normally formulated in terms of “loss,” which is a measure of the prediction error — exponentially more compute leads to a linear decline in loss (until you hit the fundamental limit).
There’s a question about how loss translates into real world capabilities. However, we can skip the notion of loss, and focus directly on the scaling relationship between compute and benchmark performance, which shows a similar pattern.↩
- The compute used on the final training run for GPT-4 likely cost about $40m. DeepSeek said they used $6m on their final run (all-in costs are much higher). The trend line would suggest a tenfold reduction, hitting $4m, so DeepSeek was more expensive than what we expected based on trends. On the other hand, DeepSeek-V3 is significantly better than the original GPT-4. But on the other, other hand, some of these improvements aren’t due only to algorithmic efficiency. So overall, I’d say it was roughly on trend, or a little ahead of trend. DeepSeek also charges users more than 10 times less than OpenAI, but a lot of that is due to slashing their profit margin rather than greater efficiency running the model. Released earlier to no fanfare, Google Gemini Flash 2.0 scores better than DeepSeek and is actually cheaper, clearly showing that other labs have achieved similar gains. The real news was that a Chinese lab reached the forefront of algorithmic efficiency.↩
- See this model of compute training over time.↩
- Levesque, H. (2012) proposed Winograd schemas — a type of commonsense language reasoning test — as an alternative to a Turing test. He argued that Winograd schemas could help determine whether AI systems truly understand language in the way humans do, rather than merely recognizing patterns. Each schema consists of a sentence with an ambiguous pronoun, and the correct interpretation depends on implicit knowledge of the meaning of words rather than just statistical correlations. He argued that these questions can’t be gamed by deception or ‘cheap tricks.’
Levesque, Hector J. “On Our Best Behaviour.” Artificial Intelligence, vol. 212, July 2014, pp. 27–35, https://doi.org/10.1016/j.artint.2014.03.007. Archived link (retrieved 10-Feb-2025)↩
- A recent study found non-experts couldn’t distinguish AI from human-generated poetry. The poetry is terrible, but it was made with GPT-3.5.
Since there were two choices (human or AI), blind chance would produce a score of 50%, and perfect skill a score of 100%.The median score on the test was 60%, only a little above chance. The mean was 60.6%. Participants said the task was harder than expected (median difficulty 4 on a 1–5 scale).
Observed accuracy was in fact slightly lower than chance (46.6%, χ2(1, N = 16340) = 75.13, p [less than] 0.0001)…Participants were more likely to guess that AI-generated poems were written by humans than they were for actual human-written poems (χ2(2, N = 16340) = 247.04, w = 0.123, p [less than] 0.0001). The five poems with the lowest rates of “human” ratings were all written by actual human poets; four of the five poems with the highest rates of “human” ratings were generated by AI.
Porter, Brian, and Edouard Machery. “AI-Generated Poetry Is Indistinguishable from Human-Written Poetry and Is Rated More Favorably.” Scientific Reports, vol. 14, no. 1, Nature Portfolio, Nov. 2024, https://doi.org/10.1038/s41598-024-76900-1.
Moving beyond GPT, this survey showed most people are poor at judging which paintings are produced by AI vs human artists.↩
- Total FLOP used in training would be around 2e28 (about 1000x GPT-4), and the cost of the final training run would be around $6bn (the cost of the cluster required to train it would be about $60bn). See the simple model here.↩
- I’m not making any claims about what OpenAI will actually call their model in 2028. That’ll probably be something silly like GPT-o3x. I just mean a model trained with this much more effective compute. See a very simple extrapolation with numbers.↩
- The trend has roughly been for training to cost 10x more each generation. Based on that, I expect GPT-6 might cost 2–3x more than $10bn, but it’s right to within an order of magnitude.↩
- 2024 net income:
- Microsoft: $88bn; Microsoft 2024 Annual Report
- Meta: $62bn;Meta Reports Fourth Quarter and Full Year 2024 Results
- Alphabet: $100bn; Alphabet Annual Report 2024↩
- 1) Nvidia sold about $100bn of AI accelerator chips in 2024 (Press releases from Q1, Q2, Q3). If that holds up for three years, then the total stock of chips will be worth $300bn. The all-in cost of the datacentres containing these chips would be around $500bn. So if 2% were used on a single training run, that run would cost about $10bn. This would require using 6% of global chips for four months. Well over 10% of Nvidia chips are bought by Microsoft and Meta, so they would all be able to do a training run of that size. Google also has enough of its own TPU chips to do the same. xAI would likely be capable of it too.
2) Brokers forecast Nvidia’s revenue will be $196bn in 2025. Approximately 80% of their total revenue is based on data centers, and 80% of data center revenue is based on GPU sales. Therefore, the revenue estimate suggests Nvidia will sell ~$125bn of chips in 2025, and that’s based significantly on orders that have already been placed. Other chip providers besides Nvidia also make up a growing share of the market, and I’ve ignored those in this estimate. So the above is likely conservative.
Additionally, information on some specific plans is available:
- Google is building a 1 GW cluster, about 7x bigger than the largest clusters today (which are around 100k H100 chips / 150 MW).
- Microsoft is building a set of a datacentres that could work together, containing 500–700 B200 chips (equivalent to perhaps 1.2m H100 chips), and that would use around 1GW.
- xAI has announced it intends to build a one million GPU cluster.↩
- Microsoft earned about $13bn of AI revenue in 2024 (up 2.75x), OpenAI perhaps $4bn (up about 3x), and Anthropic probably ~$1bn (up 5x). In addition, Google and Meta use AI heavily internally to improve their products, which indirectly generates revenue. Many newly created AI startups are also reporting very rapid revenue growth.↩
- It does this by producing one token of reasoning, then feeding that token back into the model and asking it to predict what next token would most make sense in the line of reasoning given the previous token, and so on. It’s called “chain of thought” or CoT.↩
- OpenAI probably also does reinforcement learning on each step of reasoning too.↩
- They probably also did a couple of other steps, like fine-tuning the base model on a dataset of reasoning examples. They probably also do positive reinforcement based on each step in the reasoning, rather than just the final answer. OpenAI discusses using per-step reward models, in which each step in the reasoning tree is rated, in their 2023 paper Let’s verify step by step.↩
- Interestingly this is a reversal of the last generation of systems. LLMs were initially surprisingly good at writing and creative tasks, but bad at maths.↩
- In Epoch’s testing, the best model could answer 2% (Figure 2 in the announcement). If the labs had done their own testing, this might have been a bit higher.↩
- There was controversy about the result because OpenAI was somewhat involved in creating the benchmark. However, I expect the basic point — that o3 performed much better than previous models — is still correct.↩
- $1bn is easily affordable given money they’ve already raised and still cheap compared to training GPT-6. In terms of effective compute, the scale up could be even larger, due to increasing chip and algorithmic efficiencies. Though, if it were applied to larger models, the compute per forward pass would go up.
Also note that GPT-5 and GPT-6 could be delayed because compute will be used to do reinforcement learning in post-training instead of pretraining a bigger base LLM. However, the trend to spend more on training compute — for both pre and post-training — will likely continue.↩
- In addition, there are other examples of synthetic data being useful.↩
- The DeepSeek paper shows you may be able to make this even easier by taking the old model and distilling it into a much smaller model. This enables you to get similar performance but with much less compute required to run it. That then enables you to create the next round of data more cheaply.
In addition, the trend of 10x increases in algorithmic efficiency every two years means that your ability to produce synthetic data increases 10x every two years. So even if it initially takes a lot of compute, that’ll rapidly change.↩
- According to Nathan Labenz in an episode of his podcast Cognitive Revolution.↩
- By this I mean they can reason for about as many tokens as a human could produce in an hour, approximately 10,000. This is about 100x more than GPT-4o, corresponding to the two orders of extra test time compute that OpenAI showed can be used.↩
- Nathan Labenz discusses the possibility of o3’s use of tree search in an episode of his podcast Cognitive Revolution:
It seems like with o3, it seems like there is something going on that is not just single autoregressive rollout… The number of tokens they are generating per second is higher than could realistically be generated by a single autoregressive rollout. So it seems like there is something going on with o3, where they have found a way to parallelize the computation and get a result. We don’t’ know what that is…You could do a huge number of generations and take the most common solutions. Maybe that’s it. Maybe they have some other algorithm that is aggregating these different rollouts.
There are other ways to do tree search – majority voting is just one example.↩
- Suppose GPT-o7 is able to answer a question for $1 in 2028. Instead you’ll be able to pay GPT-o5 $100,000 to think 100,000 times longer, and generate the same answer in 2026.
In 2023, Epoch estimated you should be able to have a model think 100,000 longer and get gains in performance equivalent to what you’d get from a model that was trained on 1000x times more compute — roughly one generation ahead.
In some cases, it might be possible to achieve the same performance as a model trained using 2 OOM more compute, by spending additional compute during inference. This is approximately the difference between successive generations of GPT models (eg: GPT-3 and GPT-4), without taking into account algorithmic progress.
Pablo Villalobos and David Atkinson (2023), “Trading Off Compute in Training and Inference”. Archived link (retrieved 11-Feb-2025)↩
- According to the official SWE-bench Verified leaderboard. (Archived link, retrieved 11-Feb-2025)↩
- Many AI forecasters expected this leap to take several years. Ajeya Cotra wrote about how this result caused her to significantly reduce her timelines, as did Daniel Kokotajlo.↩
- According to a report from Model Evaluation and Threat Research (METR):
Preliminary evaluations on GPT-4o and Claude. We also used our task suite to evaluate the performance of simple baseline LM agents built using models from the Claude and GPT-4 families. We found that the agents based on the most capable models (3.5 Sonnet and GPT-4o) complete a fraction of tasks comparable to what our human baseliners can do in approximately 30 minutes.↩
- Agents could also be set millions of virtual test tasks or be made to interact with other agents. This kind of “self-play” can enable rapid improvement in abilities without any external data, as happened with AlphaZero (which played against itself millions of times to become superhuman in Go in about a day).↩
- It’s hard to forecast how compute will be spent across pretraining, post training, and inference. In reality it’ll be allocated to wherever is making the largest gains. It’s possible most training compute will be spent on reinforcement learning, and GPT-6 will be delayed relative to the old trends. The broad trend in how much compute is used to train and run AI models is more robust.↩
- May be delayed if the compute is used for reinforcement learning or inference instead.↩
- What’s the scale up of reinforcement learning?
Assume $1–10m of compute was used on o1.
The labs have the resources to spend up to $1bn if it keeps working, which is 100–1000x more funding.
Over the next four years, the chips will be at least 4x more efficient at inference (H100s vs GB200s vs whatever’s next).
The models will be ~100x more algorithmically efficient than GPT-4o.
But the models might have 10x more parameters (if GPT-5 is used) or 100x if GPT-6, which means each forward pass requires more compute.
So in total this is 400–400,000x more effective compute for reinforcement learning by the end of 2028.↩
- The probability of an invasion of Taiwan before 2030 is 25% according to Metaculus as of February 11, 2025. A Taiwan invasion would likely result in most of TSMC’s chip fabs being destroyed, which would halt the supply of all AI chips. This would probably not fully stop AI progress — progress could continue for a while using chips that are already installed. There would be an epic effort to create more fabs on American soil (as TSMC has already done in Arizona), which could resume supply within a couple of years. At the same time, a war with China might lead to massive AI investment in order to seek a competitive edge.
Other scenarios that could meaningfully slow down progress would be a major economic recession or other global catastrophe like COVID, or a huge regulatory crackdown driven by popular opposition — which probably wouldn’t prevent progress forever (since the military and economic advantages would be so large), but could delay it a lot.↩
- You could do the extrapolation in terms of either time or compute; it won’t make a big difference. Arguably, progress should accelerate, especially for tasks amenable to reinforcement learning, but let’s use linear gains to be conservative.↩
- Claude Sonnet 3.5 with 5-shot chain of thought prompting, according to Anthropic.↩
- GPT.3.5 and PaLM scored ~70% averaged across subjects with chain of thought reasoning (Table 2; Laskar, et al. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets. May 2023, https://doi.org/10.48550/arxiv.2305.18486).
With further fine-tuning models can score even higher. For example, a fine-tuned 3-shot chain of thought PaLM model scored ~78%.↩
- GPT-4o can get about 3%. The best 2022 models would likely be worse. o3-mini can now get 13%. https://agi.safe.ai/ (Archived link retrieved 11-Feb-2025)↩
- Though robotics algorithms are also advancing rapidly, so this might not be much further
behind.↩ - This section previously cited a research paper reporting that an AI tool had made top material scientists 80% more productive at finding new materials. MIT has since investigated that paper and requested that it be withdrawn from the discourse. The university said it “has no confidence in the provenance, reliability or validity of the data and has no confidence in the veracity of the research contained in the paper.”↩
- If revenue growth stopped now, it’s possible people wouldn’t even want to fund $10bn training runs, but we’re already close to having large enough clusters, and there’s enough players involved who could YOLO it (xAI, Meta, Google) that it would take a lot for someone to not attempt one at this point.↩
- For example, we could see continued progress towards long-horizon agency through:
- Bigger multimodal pretraining runs making models more reliable at each step and better at perception
- Better reasoning models thinking for longer so being better at planning
- Improved agent scaffolding
- Directly training for agency with RL
- Weak agent models generating training data for more powerful ones.↩
- Total spending on AI chips is increasing about 2x per year (estimate based on Nvidia’s annual reports), and the efficiency of these chips for doing AI workloads is increasing about 1.6x per year (extrapolated from spending and training compute). Training compute has been growing ~4x per year (archived link retrieved 11-Feb-2025) because a larger fraction of compute has been allocated to training runs.↩
- Table 1 from Stine, D.D. The Manhattan Project, the Apollo Program, and Federal Energy Technology R&D Programs: A Comparative Analysis. (Archived link retrieved 11-Feb-2025)↩
- This is calculated based on AI chip sales, and it is within the range of others’ estimates:
- The current power capacity of the US is approximately 1230 GW, according to the US Energy Information Administration.
- The United States is projected to add almost 160 GW of theoretical power capacity between 2024 and 2028, according to a RAND report on AI’s power requirements under exponential growth.
- RAND’s report estimates that AI power requirements will reach 117 GW by 2028 (8.4% of total US supply), but note that other estimates from Goldman Sachs, McKinsey, and SemiAnalysis range from 3.5–5%.↩
- Their total capacity in terms of wafers — the unit used in chip production — have only grown ~10% per year recently (or a bit higher if adjusted for transistors per wafer), so once existing leading wafer capacity is used for AI, the rate of growth would slow a lot. New fabs can be built in two years, and they could construct them a lot faster than in the past if there was enough funding, but likely slower than the current 2x rate of growth.
Learn more in Can AI scaling continue through 2030 by Epoch AI.↩
- Epoch discusses this bottleneck in Data movement bottlenecks to LLM scaling. Though
innovation hasn’t focused on this bottleneck so far, I’d expect it to be possible to go beyond the limitations sketched in the report. This bottleneck also won’t prevent you from doing a ton of reinforcement learning on a smaller model.Erdil, Ege, and David Schneider-Joseph. “Data Movement Limits to Frontier Model Training.” ArXiv.org, 2024, arxiv.org/abs/2411.01137.↩
-
Krenn, Mario, et al. Predicting the Future of AI with AI: High-Quality Link Prediction in an Exponentially Growing Knowledge Network. 23 Sept. 2022, https://doi.org/10.48550/arxiv.2210.00881.↩
- There are similar dynamics with chip efficiency, which has increased faster than Moore’s law by better adapting the chips to AI workflows, e.g. switching from FP32 to tensor-FP16 led to a 10x increase in efficiency according to data from Epoch AI:
Compared to using non-tensor FP32, TF32, tensor-FP16, and tensor-INT8 provide around 6x, 10x, and 12x greater performance on average in the aggregate performance trends.
However, this can’t continue indefinitely without an exponentially growing chip research workforce.↩
- More precisely we could split it into multiple scenarios: chance of AGI in five years, chance it arrives in the 2030s (probably lower); chance it arrives in the 2040s (lower still), etc. Focusing on these two is a simplification.↩
- A key point is when a team of human researchers aided by AI are more than 2x as productive than a team without AI aids, since that would be equivalent to doubling the AI research workforce, which might be enough to start a positive feedback loop. See more.↩