In today’s episode, host Luisa Rodriguez speaks to Matt Clancy — who oversees Open Philanthropy’s Innovation Policy programme — about his recent work modelling the risks and benefits of the increasing speed of scientific progress.
They cover:
Whether scientific progress is actually net positive for humanity.
Scenarios where accelerating science could lead to existential risks, such as advanced biotechnology being used by bad actors.
Why Matt thinks metascience research and targeted funding could improve the scientific process and better incentivise outcomes that are good for humanity.
Whether Matt trusts domain experts or superforecasters more when estimating how the future will turn out.
Why Matt is sceptical that AGI could really cause explosive economic growth.
And much more.
Producer and editor: Keiran Harris Audio engineering lead: Ben Cordell Technical editing: Simon Monsour, Milo McGuire, and Dominic Armstrong Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
Why space travel is suddenly getting a lot cheaper and re-igniting enthusiasm around space settlement.
What Zach thinks are the best and worst arguments for settling space.
Zach’s journey from optimistic about space settlement to a self-proclaimed “space bastard” (pessimist).
How little we know about how microgravity and radiation affects even adults, much less the children potentially born in a space settlement.
A rundown of where we could settle in the solar system, and the major drawbacks of even the most promising candidates.
Why digging bunkers or underwater cities on Earth would beat fleeing to Mars in a catastrophe.
How new space settlements could look a lot like old company towns — and whether or not that’s a bad thing.
The current state of space law and how it might set us up for international conflict.
How space cannibalism legal loopholes might work on the International Space Station.
And much more.
Producer and editor: Keiran Harris Audio engineering lead: Ben Cordell Technical editing: Simon Monsour, Milo McGuire, and Dominic Armstrong Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
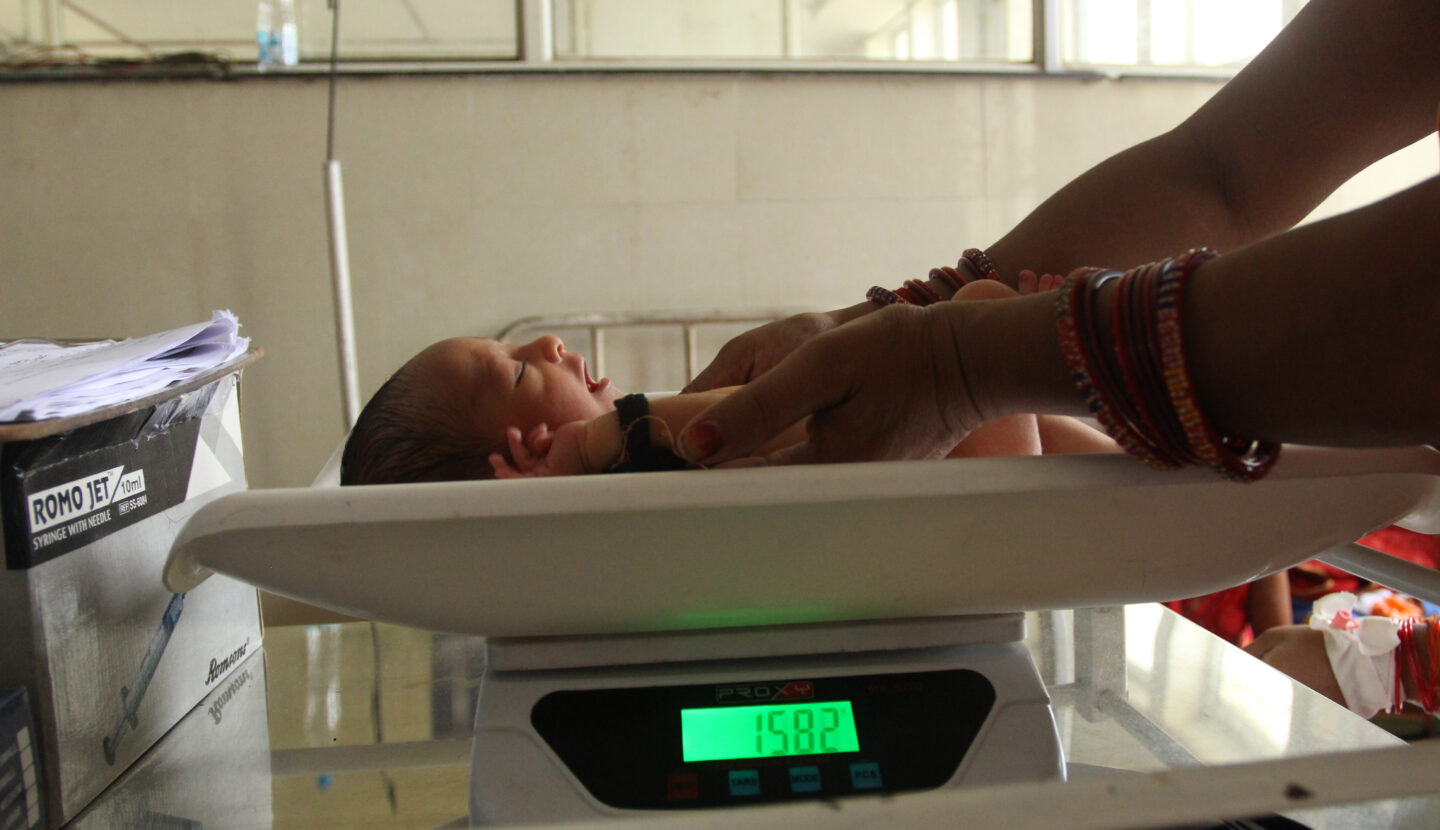
In today’s episode, host Luisa Rodriguez speaks to Dean Spears — associate professor of economics at the University of Texas at Austin and founding director of r.i.c.e. — about his experience implementing a surprisingly low-tech but highly cost-effective kangaroo mother care programme in Uttar Pradesh, India to save the lives of vulnerable newborn infants.
They cover:
The shockingly high neonatal mortality rates in Uttar Pradesh, India, and how social inequality and gender dynamics contribute to poor health outcomes for both mothers and babies.
The remarkable benefits for vulnerable newborns that come from skin-to-skin contact and breastfeeding support.
The challenges and opportunities that come with working with a government hospital to implement new, evidence-based programmes.
How the currently small programme might be scaled up to save more newborns’ lives in other regions of Uttar Pradesh and beyond.
How targeted health interventions stack up against direct cash transfers.
Plus, a sneak peak into Dean’s new book, which explores the looming global population peak that’s expected around 2080, and the consequences of global depopulation.
And much more.
Producer and editor: Keiran Harris Audio engineering lead: Ben Cordell Technical editing: Simon Monsour, Milo McGuire, and Dominic Armstrong Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
The staggering scale of animal suffering in factory farms, and how it will only get worse without intervention.
Work to improve farmed animal welfare that Open Philanthropy is excited about funding.
The amazing recent progress made in farm animal welfare — including regulatory attention in the EU and a big win at the US Supreme Court — and the work that still needs to be done.
The occasional tension between ending factory farming and curbing climate change.
How AI could transform factory farming for better or worse — and Lewis’s fears that the technology will just help us maximise cruelty in the name of profit.
Lewis’s personal journey working on farm animal welfare, and how he copes with the emotional toll of confronting the scale of animal suffering.
How listeners can get involved in the growing movement to end factory farming — from career and volunteer opportunities to impactful donations.
And much more.
Producer and editor: Keiran Harris Audio engineering lead: Ben Cordell Technical editing: Simon Monsour, Milo McGuire, and Dominic Armstrong Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
Many of you will have heard of Zvi Mowshowitz as a superhuman information-absorbing-and-processing machine — which he definitely is.
As the author of the Substack Don’t Worry About the Vase, Zvi has spent as much time as literally anyone in the world over the last two years tracking in detail how the explosion of AI has been playing out — and he has strong opinions about almost every aspect of it. So in today’s episode, host Rob Wiblin asks Zvi for his takes on:
US-China negotiations
Whether AI progress has stalled
The biggest wins and losses for alignment in 2023
EU and White House AI regulations
Which major AI lab has the best safety strategy
The pros and cons of the Pause AI movement
Recent breakthroughs in capabilities
In what situations it’s morally acceptable to work at AI labs
Whether you agree or disagree with his views, Zvi is super informed and brimming with concrete details.
Zvi and Rob also talk about:
The risk of AI labs fooling themselves into believing their alignment plans are working when they may not be.
The “sleeper agent” issue uncovered in a recent Anthropic paper, and how it shows us how hard alignment actually is.
Why Zvi disagrees with 80,000 Hours’ advice about gaining career capital to have a positive impact.
Zvi’s project to identify the most strikingly horrible and neglected policy failures in the US, and how Zvi founded a new think tank (Balsa Research) to identify innovative solutions to overthrow the horrible status quo in areas like domestic shipping, environmental reviews, and housing supply.
Why Zvi thinks that improving people’s prosperity and housing can make them care more about existential risks like AI.
An idea from the online rationality community that Zvi thinks is really underrated and more people should have heard of: simulacra levels.
And plenty more.
Producer and editor: Keiran Harris Audio engineering lead: Ben Cordell Technical editing: Simon Monsour, Milo McGuire, and Dominic Armstrong Transcriptions: Katy Moore
In today’s episode, host Rob Wiblin speaks for a fourth time with listener favourite Spencer Greenberg — serial entrepreneur and host of the Clearer Thinking podcast — about a grab-bag of topics that Spencer has explored since his last appearance on the show a year ago.
They cover:
How much money makes you happy — and the tricky methodological issues that come up trying to answer that question.
The importance of hype in making valuable things happen.
How to recognise warning signs that someone is untrustworthy or likely to hurt you.
Whether Registered Reports are successfully solving reproducibility issues in science.
The personal principles Spencer lives by, and whether or not we should all establish our own list of life principles.
The biggest and most harmful systemic mistakes we commit when making decisions, both individually and as groups.
The potential harms of lightgassing, which is the opposite of gaslighting.
How Spencer’s team used non-statistical methods to test whether astrology works.
Whether there’s any social value in retaliation.
And much more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour, Milo McGuire, and Dominic Armstrong Transcriptions: Katy Moore
The methods used to assess the welfare ranges and capacities for pleasure and pain of chickens, pigs, octopuses, bees, and other animals — and the limitations of that approach.
Concrete examples of how someone might use the estimated moral weights to compare the benefits of animal vs human interventions.
The results that most surprised Bob.
Why the team used a hedonic theory of welfare to inform the project, and what non-hedonic theories of welfare might bring to the table.
Thought experiments like Tortured Tim that test different philosophical assumptions about welfare.
Confronting our own biases when estimating animal mental capacities and moral worth.
The limitations of using neuron counts as a proxy for moral weights.
How different types of risk aversion, like avoiding worst-case scenarios, could impact cause prioritisation.
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour and Milo McGuire Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
In today’s episode, host Luisa Rodriguez speaks to Laura Deming — founder of The Longevity Fund — about the challenge of ending ageing.
They cover:
How lifespan is surprisingly easy to manipulate in animals, which suggests human longevity could be increased too.
Why we irrationally accept age-related health decline as inevitable.
The engineering mindset Laura takes to solving the problem of ageing.
Laura’s thoughts on how ending ageing is primarily a social challenge, not a scientific one.
The recent exciting regulatory breakthrough for an anti-ageing drug for dogs.
Laura’s vision for how increased longevity could positively transform society by giving humans agency over when and how they age.
Why this decade may be the most important decade ever for making progress on anti-ageing research.
The beauty and fascination of biology, which makes it such a compelling field to work in.
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour and Milo McGuire Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
And the discussion around misinformation and disinformation has shifted to focus on how generative AI or a future super-persuasive AI might change the game and make it extremely hard to figure out what was going on in the world — or alternatively, extremely easy to mislead people into believing convenient lies.
But this week’s guest, cognitive scientist Hugo Mercier, has a very different view on how people form beliefs and figure out who to trust — one in which misinformation really is barely a problem today, and is unlikely to be a problem anytime soon. As he explains in his book Not Born Yesterday, Hugo believes we seriously underrate the perceptiveness and judgement of ordinary people.
In this interview, host Rob Wiblin and Hugo discuss:
How our reasoning mechanisms evolved to facilitate beneficial communication, not blind gullibility.
How Hugo makes sense of our apparent gullibility in many cases — like falling for financial scams, astrology, or bogus medical treatments, and voting for policies that aren’t actually beneficial for us.
Rob and Hugo’s ideas about whether AI might make misinformation radically worse, and which mass persuasion approaches we should be most worried about.
Why Hugo thinks our intuitions about who to trust are generally quite sound, even in today’s complex information environment.
The distinction between intuitive beliefs that guide our actions versus reflective beliefs that don’t.
Why fake news and conspiracy theories actually have less impact than most people assume.
False beliefs that have persisted across cultures and generations — like bloodletting and vaccine hesitancy — and theories about why.
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour and Milo McGuire Transcriptions: Katy Moore
Mental health problems like depression and anxiety affect enormous numbers of people and severely interfere with their lives. By contrast, we don’t see similar levels of physical ill health in young people. At any point in time, something like 20% of young people are working through anxiety or depression that’s seriously interfering with their lives — but nowhere near 20% of people in their 20s have severe heart disease or cancer or a similar failure in a key organ of the body other than the brain.
From an evolutionary perspective, that’s to be expected, right? If your heart or lungs or legs or skin stop working properly while you’re a teenager, you’re less likely to reproduce, and the genes that cause that malfunction get weeded out of the gene pool.
So why is it that these evolutionary selective pressures seemingly fixed our bodies so that they work pretty smoothly for young people most of the time, but it feels like evolution fell asleep on the job when it comes to the brain? Why did evolution never get around to patching the most basic problems, like social anxiety, panic attacks, debilitating pessimism, or inappropriate mood swings? For that matter, why did evolution go out of its way to give us the capacity for low mood or chronic anxiety or extreme mood swings at all?
Today’s guest, Randy Nesse — a leader in the field of evolutionary psychiatry — wrote the book Good Reasons for Bad Feelings, in which he sets out to try to resolve this paradox.
In the interview, host Rob Wiblin and Randy discuss the key points of the book, as well as:
How the evolutionary psychiatry perspective can help people appreciate that their mental health problems are often the result of a useful and important system.
How evolutionary pressures and dynamics lead to a wide range of different personalities, behaviours, strategies, and tradeoffs.
The missing intellectual foundations of psychiatry, and how an evolutionary lens could revolutionise the field.
How working as both an academic and a practicing psychiatrist shaped Randy’s understanding of treating mental health problems.
The “smoke detector principle” of why we experience so many false alarms along with true threats.
The origins of morality and capacity for genuine love, and why Randy thinks it’s a mistake to try to explain these from a selfish gene perspective.
Evolutionary theories on why we age and die.
And much more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Dominic Armstrong Transcriptions: Katy Moore
In today’s episode, host Luisa Rodriguez speaks to Emily Oster — economist at Brown University, host of the ParentData podcast, and the author of three hugely popular books that provide evidence-based insights into pregnancy and early childhood.
They cover:
Common pregnancy myths and advice that Emily disagrees with — and why you should probably get a doula.
Whether it’s fine to continue with antidepressants and coffee during pregnancy.
What the data says — and doesn’t say — about outcomes from parenting decisions around breastfeeding, sleep training, childcare, and more.
Which factors really matter for kids to thrive — and why that means parents shouldn’t sweat the small stuff.
How to reduce parental guilt and anxiety with facts, and reject judgemental “Mommy Wars” attitudes when making decisions that are best for your family.
The effects of having kids on career ambitions, pay, and productivity — and how the effects are different for men and women.
Practical advice around managing the tradeoffs between career and family.
What to consider when deciding whether and when to have kids.
Relationship challenges after having kids, and the protective factors that help.
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour and Milo McGuire Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
In today’s episode, their conversation continues, with Nathan diving deeper into:
What AI now actually can and can’t do — across language and visual models, medicine, scientific research, self-driving cars, robotics, weapons — and what the next big breakthrough might be.
Why most people, including most listeners, probably don’t know and can’t keep up with the new capabilities and wild results coming out across so many AI applications — and what we should do about that.
How we need to learn to talk about AI more productively — particularly addressing the growing chasm between those concerned about AI risks and those who want to see progress accelerate, which may be counterproductive for everyone.
Where Nathan agrees with and departs from the views of ‘AI scaling accelerationists.’
The chances that anti-regulation rhetoric from some AI entrepreneurs backfires.
How governments could (and already do) abuse AI tools like facial recognition, and how militarisation of AI is progressing.
Preparing for coming societal impacts and potential disruption from AI.
Practical ways that curious listeners can try to stay abreast of everything that’s going on.
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour and Milo McGuire Transcriptions: Katy Moore
OpenAI says its mission is to build AGI — an AI system that is better than human beings at everything. Should the world trust them to do this safely?
That’s the central theme of today’s episode with Nathan Labenz — entrepreneur, AI scout, and host of The Cognitive Revolution podcast. Nathan saw the AI revolution coming years ago, and, astonished by the research he was seeing, set aside his role as CEO of Waymark and made it his full-time job to understand AI capabilities across every domain. He has been obsessively tracking the AI world since — including joining OpenAI’s “red team” that probed GPT-4 to find ways it could be abused, long before it was public.
Whether OpenAI was taking AI safety seriously enough became a topic of dinner table conversation around the world after the shocking firing and reinstatement of Sam Altman as CEO last month.
Nathan’s view: it’s complicated. Discussion of this topic has often been heated, polarising, and personal. But Nathan wants to avoid that and simply lay out, in a way that is impartial and fair to everyone involved, what OpenAI has done right and how it could do better in his view.
When he started on the GPT-4 red team, the model would do anything from diagnose a skin condition to plan a terrorist attack without the slightest reservation or objection. When later shown a “Safety” version of GPT-4 that was almost the same, he approached a member of OpenAI’s board to share his concerns and tell them they really needed to try out GPT-4 for themselves and form an opinion.
In today’s episode, we share this story as Nathan told it on his own show, The Cognitive Revolution, which he did in the hope that it would provide useful background to understanding the OpenAI board’s reservations about Sam Altman, which to this day have not been laid out in any detail.
But while he feared throughout 2022 that OpenAI and Sam Altman didn’t understand the power and risk of their own system, he has since been repeatedly impressed, and came to think of OpenAI as among the better companies that could hypothetically be working to build AGI.
Their efforts to make GPT-4 safe turned out to be much larger and more successful than Nathan was seeing. Sam Altman and other leaders at OpenAI seem to sincerely believe they’re playing with fire, and take the threat posed by their work very seriously. With the benefit of hindsight, Nathan suspects OpenAI’s decision to release GPT-4 when it did was for the best.
On top of that, OpenAI has been among the most sane and sophisticated voices advocating for AI regulations that would target just the most powerful AI systems — the type they themselves are building — and that could make a real difference. They’ve also invested major resources into new ‘Superalignment’ and ‘Preparedness’ teams, while avoiding using competition with China as an excuse for recklessness.
At the same time, it’s very hard to know whether it’s all enough. The challenge of making an AGI safe and beneficial may require much more than they hope or have bargained for. Given that, Nathan poses the question of whether it makes sense to try to build a fully general AGI that can outclass humans in every domain at the first opportunity. Maybe in the short term, we should focus on harvesting the enormous possible economic and humanitarian benefits of narrow applied AI models, and wait until we not only have a way to build AGI, but a good way to build AGI — an AGI that we’re confident we want, which we can prove will remain safe as its capabilities get ever greater.
By threatening to follow Sam Altman to Microsoft before his reinstatement as OpenAI CEO, OpenAI’s research team has proven they have enormous influence over the direction of the company. If they put their minds to it, they’re also better placed than maybe anyone in the world to assess if the company’s strategy is on the right track and serving the interests of humanity as a whole. Nathan concludes that this power and insight only adds to the enormous weight of responsibility already resting on their shoulders.
In today’s extensive conversation, Nathan and host Rob Wiblin discuss not only all of the above, but also:
Speculation about the OpenAI boardroom drama with Sam Altman, given Nathan’s interactions with the board when he raised concerns from his red teaming efforts.
Which AI applications we should be urgently rolling out, with less worry about safety.
Whether governance issues at OpenAI demonstrate AI research can only be slowed by governments.
Whether AI capabilities are advancing faster than safety efforts and controls.
The costs and benefits of releasing powerful models like GPT-4.
Nathan’s view on the game theory of AI arms races and China.
Whether it’s worth taking some risk with AI for huge potential upside.
The need for more “AI scouts” to understand and communicate AI progress.
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Milo McGuire and Dominic Armstrong Transcriptions: Katy Moore
Lead is one of the most poisonous things going. A single sugar sachet of lead, spread over a park the size of an American football field, is enough to give a child that regularly plays there lead poisoning. For life they’ll be condemned to a ~3-point-lower IQ; a 50% higher risk of heart attacks; and elevated risk of kidney disease, anaemia, and ADHD, among other effects.
We’ve known lead is a health nightmare for at least 50 years, and that got lead out of car fuel everywhere. So is the situation under control? Not even close.
Around half the kids in poor and middle-income countries have blood lead levels above 5 micrograms per decilitre; the US declared a national emergency when just 5% of the children in Flint, Michigan exceeded that level. The collective damage this is doing to children’s intellectual potential, health, and life expectancy is vast — the health damage involved is around that caused by malaria, tuberculosis, and HIV combined.
This week’s guest, Lucia Coulter — cofounder of the incredibly successful Lead Exposure Elimination Project (LEEP) — speaks about how LEEP has been reducing childhood lead exposure in poor countries by getting bans on lead in paint enforced.
Various estimates suggest the work is absurdly cost effective. LEEP is in expectation preventing kids from getting lead poisoning for under $2 per child (explore the analysis here). Or, looking at it differently, LEEP is saving a year of healthy life for $14, and in the long run is increasing people’s lifetime income anywhere from $300–1,200 for each $1 it spends, by preventing intellectual stunting.
Which raises the question: why hasn’t this happened already? How is lead still in paint in most poor countries, even when that’s oftentimes already illegal? And how is LEEP able to get bans on leaded paint enforced in a country while spending barely tens of thousands of dollars? When leaded paint is gone, what should they target next?
With host Robert Wiblin, Lucia answers all those questions and more:
Why LEEP isn’t fully funded, and what it would do with extra money (you can donate here).
How bad lead poisoning is in rich countries.
Why lead is still in aeroplane fuel.
How lead got put straight in food in Bangladesh, and a handful of people got it removed.
Why the enormous damage done by lead mostly goes unnoticed.
The other major sources of lead exposure aside from paint.
Generalisable lessons LEEP has learned from coordinating with governments in poor countries.
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Milo McGuire and Dominic Armstrong Transcriptions: Katy Moore
In today’s episode, host Luisa Rodriguez speaks to Nita Farahany — professor of law and philosophy at Duke Law School — about applications of cutting-edge neurotechnology.
They cover:
How close we are to actual mind reading.
How hacking neural interfaces could cure depression.
How companies might use neural data in the workplace — like tracking how productive you are, or using your emotional states against you in negotiations.
How close we are to being able to unlock our phones by singing a song in our heads.
How neurodata has been used for interrogations, and even criminal prosecutions.
The possibility of linking brains to the point where you could experience exactly the same thing as another person.
Military applications of this tech, including the possibility of one soldier controlling swarms of drones with their mind.
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour and Milo McGuire Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
In today’s episode, host Luisa Rodriguez interviews Jeff Sebo — director of the Mind, Ethics, and Policy Program at NYU — about preparing for a world with digital minds.
They cover:
The non-negligible chance that AI systems will be sentient by 2030
What AI systems might want and need, and how that might affect our moral concepts
What happens when beings can copy themselves? Are they one person or multiple people? Does the original own the copy or does the copy have its own rights? Do copies get the right to vote?
What kind of legal and political status should AI systems have? Legal personhood? Political citizenship?
What happens when minds can be connected? If two minds are connected, and one does something illegal, is it possible to punish one but not the other?
The repugnant conclusion and the rebugnant conclusion
The experience of trying to build the field of AI welfare
What improv comedy can teach us about doing good in the world
And plenty more.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Dominic Armstrong and Milo McGuire Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
Is following important political and international news a civic duty — or is it our civic duty to avoid it?
It’s common to think that ‘staying informed’ and checking the headlines every day is just what responsible adults do.
But in today’s episode, host Rob Wiblin is joined by economist Bryan Caplan to discuss the book Stop Reading the News: A Manifesto for a Happier, Calmer and Wiser Life — which argues that reading the news both makes us miserable and distorts our understanding of the world. Far from informing us and enabling us to improve the world, consuming the news distracts us, confuses us, and leaves us feeling powerless.
In the first half of the episode, Bryan and Rob discuss various alleged problems with the news, including:
That it overwhelmingly provides us with information we can’t usefully act on.
That it’s very non-representative in what it covers, in particular favouring the negative over the positive and the new over the significant.
That it obscures the big picture, falling into the trap of thinking ‘something important happens every day.’
That it’s highly addictive, for many people chewing up 10% or more of their waking hours.
That regularly checking the news leaves us in a state of constant distraction and less able to engage in deep thought.
And plenty more.
Bryan and Rob conclude that if you want to understand the world, you’re better off blocking news websites and spending your time on Wikipedia, Our World in Data, or reading a textbook. And if you want to generate political change, stop reading about problems you already know exist and instead write your political representative a physical letter — or better yet, go meet them in person.
In the second half of the episode, Bryan and Rob cover:
Why Bryan is pretty sceptical that AI is going to lead to extreme, rapid changes, or that there’s a meaningful chance of it going terribly.
Bryan’s case that rational irrationality on the part of voters leads to many very harmful policy decisions.
How to allocate resources in space.
Bryan’s experience homeschooling his kids.
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour and Milo McGuire Transcriptions: Katy Moore
In today’s episode, host Luisa Rodriguez interviews award-winning investigative journalist Alison Young on the surprising frequency of lab leaks and what needs to be done to prevent them in the future.
They cover:
The most egregious biosafety mistakes made by the CDC, and how Alison uncovered them through her investigative reporting
The Dugway life science test facility case, where live anthrax was accidentally sent to labs across the US and several other countries over a period of many years
The time the Soviets had a major anthrax leak, and then hid it for over a decade
The 1977 influenza pandemic caused by vaccine trial gone wrong in China
The last death from smallpox, caused not by the virus spreading in the wild, but by a lab leak in the UK
Ways we could get more reliable oversight and accountability for these labs
And the investigative work Alison’s most proud of
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Simon Monsour and Milo McGuire Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore
In today’s episode, host Luisa Rodriguez interviews Paul Niehaus — cofounder of GiveDirectly — on the case for giving unconditional cash to the world’s poorest households.
They cover:
The empirical evidence on whether giving cash directly can drive meaningful economic growth
How the impacts of GiveDirectly compare to USAID employment programmes
GiveDirectly vs GiveWell’s top-recommended charities
How long-term guaranteed income affects people’s risk-taking and investments
Whether recipients prefer getting lump sums or monthly instalments
How GiveDirectly tackles cases of fraud and theft
The case for universal basic income, and GiveDirectly’s UBI studies in Kenya, Malawi, and Liberia
The political viability of UBI
Plenty more
Producer and editor: Keiran Harris Audio Engineering Lead: Ben Cordell Technical editing: Dominic Armstrong and Milo McGuire Additional content editing: Katy Moore and Luisa Rodriguez Transcriptions: Katy Moore