

#219 – Toby Ord on graphs AI companies would prefer you didn’t (fully) understand
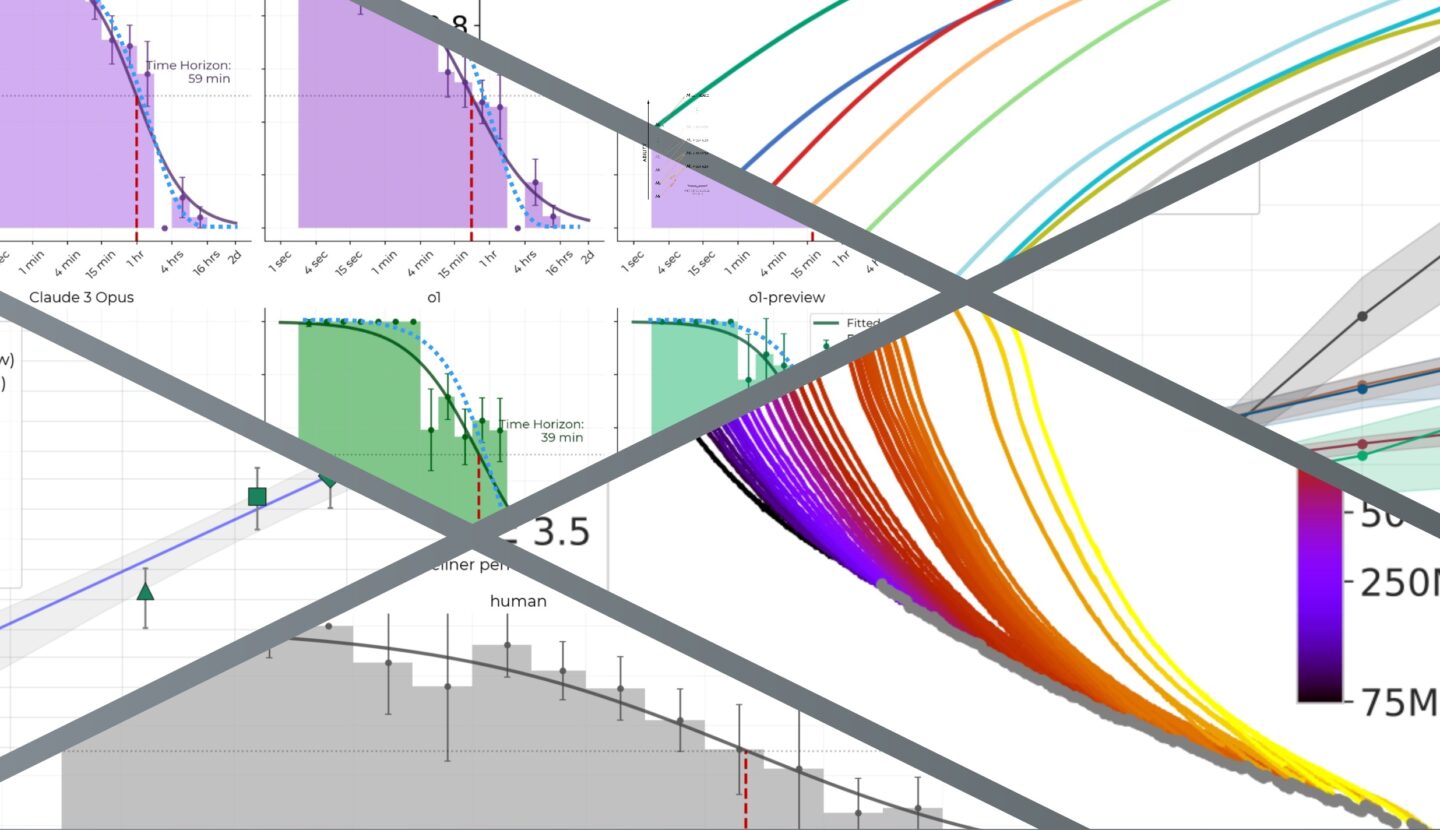
The era of making AI smarter by just making it bigger is ending. But that doesn’t mean progress is slowing down — far from it. AI models continue to get much more powerful, just using very different methods. And those underlying technical changes force a big rethink of what coming years will look like.
Toby Ord — Oxford philosopher and bestselling author of The Precipice — has been tracking these shifts and mapping out the implications both for governments and our lives.
As he explains, until recently anyone can access the best AI in the world “for less than the price of a can of Coke.” But unfortunately, that’s over.
What changed? AI companies first made models smarter by throwing a million times as much computing power at them during training, to make them better at predicting the next word. But with high quality data drying up, that approach petered out in 2024.
So they pivoted to something radically different: instead of training smarter models, they’re giving existing models dramatically more time to think — leading to the rise in “reasoning models” that are at the frontier today.
The results are impressive but this extra computing time comes at a cost: OpenAI’s o3 reasoning model achieved stunning results on a famous AI test by writing an Encyclopedia Britannica‘s worth of reasoning to solve individual problems — at a cost of over $1,000 per question.
This isn’t just technical trivia: if this improvement method sticks, it will change much about how the AI revolution plays out — starting with the fact that we can expect the rich and powerful to get access to the best AI models well before the rest of us.
Companies have also begun applying “reinforcement learning” in which models are asked to solve practical problems, and then told to “do more of that” whenever it looks like they’ve gotten the right answer.
This has led to amazing advances in problem-solving ability — but it also explains why AI models have suddenly gotten much more deceptive. Reinforcement learning has always had the weakness that it encourages creative cheating, or tricking people into thinking you got the right answer even when you didn’t.
Toby shares typical recent examples of this “reward hacking” — from models Googling answers while pretending to reason through the problem (a deception hidden in OpenAI’s own release data), to achieving “100x improvements” by hacking their own evaluation systems.
To cap it all off, it’s getting harder and harder to trust publications from AI companies, as marketing and fundraising have become such dominant concerns.
While companies trumpet the impressive results of the latest models, Toby points out that they’ve actually had to spend a million times as much just to cut model errors by half. And his careful inspection of an OpenAI graph supposedly demonstrating that o3 was the new best model in the world revealed that it was actually no more efficient than its predecessor.
But Toby still thinks it’s critical to pay attention, given the stakes:
…there is some snake oil, there is some fad-type behaviour, and there is some possibility that it is nonetheless a really transformative moment in human history. It’s not an either/or. I’m trying to help people see clearly the actual kinds of things that are going on, the structure of this landscape, and to not be confused by some of these charts.
Recorded on May 23, 2025.
Video editing: Simon Monsour
Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong
Music: Ben Cordell
Camera operator: Jeremy Chevillotte
Transcriptions and web: Katy Moore

















