In early 2025, after OpenAI put out the first-ever reasoning models — o1 and o3 — short timelines to transformative artificial general intelligence swept the AI world. But then, in the second half of 2025, sentiment swung all the way back in the other direction, with people’s forecasts for when AI might really shake up the world blowing out even further than they had been before reasoning models came along.
What the hell happened? Was it just swings in vibes and mood? Confusion? A series of fundamentally unexpected and unpredictable research results?
Host Rob Wiblin has been trying to make sense of it for himself, and here’s the best explanation he’s come up with so far.
This episode was recorded on January 29, 2026.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Camera operator: Dominic Armstrong Coordination, transcripts, and web: Katy Moore
Democracy might be a brief historical blip. That’s the unsettling thesis of a recent paper, which argues AI that can do all the work a human can do inevitably leads to the “gradual disempowerment” of humanity.
For most of history, ordinary people had almost no control over their governments. Liberal democracy emerged only recently, and probably not coincidentally around the Industrial Revolution.
Today’s guest, David Duvenaud, used to lead the ‘alignment evals’ team at Anthropic, is a professor of computer science at the University of Toronto, and recently coauthored the paper “Gradual disempowerment.”
He argues democracy wasn’t the result of moral enlightenment — it was competitive pressure. Nations that educated their citizens and gave them political power built better armies and more productive economies. But what happens when AI can do all the producing — and all the fighting?
“The reason that states have been treating us so well in the West, at least for the last 200 or 300 years, is because they’ve needed us,” David explains. “Life can only get so bad when you’re needed. That’s the key thing that’s going to change.”
In David’s telling, once AI can do everything humans can do but cheaper, citizens become a national liability rather than an asset. With no way to make an economic contribution, their only lever becomes activism — demanding a larger share of redistribution from AI production. Faced with millions of unemployed citizens turned full-time activists, democratic governments trying to retain some “legacy” human rights may find they’re at a disadvantage compared to governments that strategically restrict civil liberties.
But democracy is just one front. The paper argues humans will lose control through economic obsolescence, political marginalisation, and the effects on culture that’s increasingly shaped by machine-to-machine communication — even if every AI does exactly what it’s told.
This episode was recorded on August 21, 2025.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Camera operator: Jake Morris Coordination, transcriptions, and web: Katy Moore
When James Smith first heard about mirror bacteria, he was sceptical. But within two weeks, he’d dropped everything to work on it full time, considering it the worst biothreat that he’d seen described. What convinced him?
Mirror bacteria would be constructed entirely from molecules that are the mirror images of their naturally occurring counterparts. This seemingly trivial difference creates a fundamental break in the tree of life. For billions of years, the mechanisms underlying immune systems and keeping natural populations of microorganisms in check have evolved to recognise threats by their molecular shape — like a hand fitting into a matching glove.
Mirror bacteria would upend that assumption, creating two enormous problems:
Many critical immune pathways would likely fail to activate, creating risks of fatal infection across many species.
Mirror bacteria could have substantial resistance to natural predators: for example, they would be essentially immune to the viruses that currently keep bacteria populations in check. That could help them spread and become irreversibly entrenched across diverse ecosystems.
Unlike ordinary pathogens, which are typically species-specific, mirror bacteria’s reversed molecular structure means they could potentially infect humans, livestock, wildlife, and plants simultaneously. The same fundamental problem — reversed molecular structure breaking immune recognition — could affect most immune systems across the tree of life. People, animals, and plants could be infected from any contaminated soil, dust, or species.
The discovery of these risks came as a surprise. The December 2024 Science paper that brought international attention to mirror life was coauthored by 38 leading scientists, including two Nobel Prize winners and several who had previously wanted to create mirror organisms.
James is now the director of the Mirror Biology Dialogues Fund, which supports conversations among scientists and other experts about how these risks might be addressed. Scientists tracking the field think that mirror bacteria might be feasible in 10–30 years, or possibly sooner. But scientists have already created substantial components of the cellular machinery needed for mirror life. We can regulate precursor technologies to mirror life before they become technically feasible — but only if we act before the research crosses critical thresholds. Once certain capabilities exist, we can’t undo that knowledge.
Addressing these risks could actually be very tractable: unlike other technologies where massive potential benefits accompany catastrophic risks, mirror life appears to offer minimal advantages beyond academic interest.
Nonetheless, James notes that fewer than 10 people currently work full-time on mirror life risks and governance. This is an extraordinary opportunity for researchers in biosecurity, synthetic biology, immunology, policy, and many other fields to help solve an entirely preventable catastrophe — James even believes the issue is on par with AI safety as a priority for some people, depending on their skill set.
This episode was recorded on November 5-6, 2025. Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Camera operators: Jeremy Chevillotte and Alex Miles Coordination, transcripts, and web: Katy Moore
A note from Rob Wiblin about infohazards
Some listeners have raised the concern that the information in this episode is an ‘infohazard’ — that is, information that’s dangerous to publicise and which we should avoid covering on the show.
It was no doubt a complex decision for the small group who originally identified the mirror bacteria threat to decide whether to go public with it. I know they debated it at length and shared it with other scientists only very gradually.
In short, scientists almost certainly would have noticed the same issues at a later time, and perhaps impulsively shared them with the world. But by that point, with biology progressing normally in the meantime, there would have been less of a technical buffer between current science and the actual development of mirror bacteria. The sooner we can implement a moratorium on new research that makes it easier to create them, the wider we can keep that buffer, and the safer we will be.
For us here at 80,000 Hours, the decision is more straightforward. The risk of mirror bacteria was published to widespread media coverage in December 2024, in The New York Times, Financial Times, CNN, The Guardian, and Le Monde, among many others. There are YouTube videos describing mirror bacteria with millions of views.
So it’s very far from a secret now.
The existence of this interview does little to change how salient mirror bacteria are on a global scale.
But thanks to our audience, we can make a big difference to whether MBDF and others can hire the dedicated staff they need to successfully close the technical path to actually developing mirror bacteria. That makes the interview a clear win in expectation, which is the view of experts in mirror bacteria who work on this problem full time.
Buck Shlegeris on convincing AI models they’ve already escaped (#214)
Paul Scharre on a personal experience in Afghanistan that influenced his views on autonomous weapons (#231)
Ian Dunt on how unelected septuagenarians are the heroes of UK governance (#216)
Beth Barnes on AI companies being locally reasonable, but globally reckless (#217)
Tyler Whitmer on one thing the California and Delaware attorneys general forced on the OpenAI for-profit as part of their restructure (November update)
Toby Ord on whether rich people will get access to AGI first (#219)
Andrew Snyder-Beattie on how the worst biorisks are defence dominant (#224)
Eileen Yam on the most eye-watering gaps in opinions about AI between experts and the US public (#228)
Will MacAskill on what a century of history crammed into a decade might feel like (#213)
Kyle Fish on what happens when two instances of Claude are left to interact with each other (#221)
Sam Bowman on where the Not In My Back Yard movement actually has a point (#211)
Neel Nanda on how mechanistic interpretability is trying to be the biology of AI (#222)
Tom Davidson on the potential to install secret AI loyalties at a very early stage (#215)
Luisa and Rob discussing how medicine doesn’t take the health burden of pregnancy seriously enough (November team chat)
Marius Hobbhahn on why scheming is a very natural path for AI models — and people (#229)
Holden Karnofsky on lessons for AI regulation drawn from successful farm animal welfare advocacy (#226)
Allan Dafoe on how AGI is an inescapable idea but one we have to define well (#212)
Ryan Greenblatt on the most likely ways for AI to take over (#220)
Updates Daniel Kokotajlo has made to his forecasts since writing and publishing the AI 2027 scenario (#225)
Dean Ball on why regulation invites path dependency, and that’s a major problem (#230)
It’s been another year of living through history, whether we asked for it or not. Luisa and Rob will be back in 2026 to help you make sense of whatever comes next — as Earth continues its indifferent journey through the cosmos, now accompanied by AI systems that can summarise our meetings and generate adequate birthday messages for colleagues we barely know.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Coordination, transcripts, and web: Katy Moore
Most debates about the moral status of AI systems circle the same question: is there something that it feels like to be them? But what if that’s the wrong question to ask?
Andreas Mogensen — a senior researcher in moral philosophy at the University of Oxford — argues that so-called ‘phenomenal consciousness’ might be neither necessary nor sufficient for a being to deserve moral consideration.
For instance, a creature on the sea floor that experiences nothing but faint brightness from the sun might have no moral claim on us, despite being conscious.
Meanwhile, any being with real desires that can be fulfilled or not fulfilled can arguably be benefited or harmed. Such beings arguably have a capacity for welfare, which means they might matter morally.
And, Andreas argues, desire may not require subjective experience. Desire may need to be backed by positive or negative emotions — but as Andreas explains, there are some reasons to think a being could also have emotions without being conscious.
There’s another underexplored route to moral patienthood: autonomy. If a being can rationally reflect on its goals and direct its own existence, we might have a moral duty to avoid interfering with its choices — even if it has no capacity for welfare.
However, Andreas suspects genuine autonomy might require consciousness after all. To be a rational agent, your beliefs probably need to be justified by something, and conscious experience might be what does the justifying. But even this isn’t clear.
The upshot? There’s a chance we could just be really mistaken about what it would take for an AI to matter morally. And with AI systems potentially proliferating at massive scale, getting this wrong could be among the largest moral errors in history.
In today’s interview, Andreas and host Zershaaneh Qureshi confront all these confusing ideas, challenging their intuitions about consciousness, welfare, and morality along the way. They also grapple with a few seemingly attractive arguments which share a very unsettling conclusion: that human extinction (or even the extinction of all sentient life) could actually be a morally desirable thing.
This episode was recorded on December 3, 2025.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Coordination, transcripts, and web: Katy Moore
In 1983, Stanislav Petrov, a Soviet lieutenant colonel, sat in a bunker watching a red screen flash “MISSILE LAUNCH.” The system told him the United States had fired five nuclear weapons at the Soviet Union. Protocol demanded he report it to superiors, which would almost certainly trigger a retaliatory strike.
Petrov didn’t do it. He had a “funny feeling” in his gut. He reasoned that if the US were actually attacking, they wouldn’t just fire five missiles — they’d empty the silos. He bet the fate of the world on a hunch that the machine was broken. He was right.
Paul Scharre, the former Army Ranger who led the Pentagon team that wrote the US military’s first policy on autonomous weapons, asks a terrifying question: What would an AI have done in Petrov’s shoes?
Would an AI system have been flexible and wise enough to make the same judgement? Or would it have launched a counterattack?
Paul joins host Luisa Rodriguez to explain why we are hurtling toward a “battlefield singularity” — a tipping point where AI increasingly replaces humans in much of the military, changing the way war is fought with speed and complexity that outpaces humans’ ability to keep up.
Militaries don’t necessarily want to take humans out of the loop. But Paul argues that the competitive pressure of warfare creates a “use it or lose it” dynamic. As former Deputy Secretary of Defense Bob Work put it: “If our competitors go to Terminators, and their decisions are bad, but they’re faster, how would we respond?”
Once that line is crossed, Paul warns we might enter an era of “flash wars” — conflicts that spiral out of control as quickly and inexplicably as a flash crash in the stock market, with no way for humans to call a timeout.
In this episode, Paul and Luisa dissect what this future looks like:
Swarming warfare: Why the future isn’t just better drones, but thousands of cheap, autonomous agents coordinating like a hive mind to overwhelm defences.
The Gatling gun cautionary tale: The inventor of the Gatling gun thought automating fire would reduce the number of soldiers needed, saving lives. Instead, it made war significantly deadlier. Paul argues AI automation could do the same, increasing lethality rather than creating “bloodless” robot wars.
The cyber frontier: While robots have physical limits, Paul argues cyberwarfare is already at the point where AI can act faster than human defenders, leading to intelligent malware that evolves and adapts like a biological virus.
The US-China “adoption race”: Paul rejects the idea that the US and China are in a spending arms race (AI is barely 1% of the DoD budget). Instead, it’s a race of organisational adoption — one where the US has massive advantages in talent and chips, but struggles with bureaucratic inertia that might not be a problem for an autocratic country.
Paul also shares a personal story from his time as a sniper in Afghanistan — watching a potential target through his scope — that fundamentally shaped his view on why human judgement, with all its flaws, is the only thing keeping war from losing its humanity entirely.
This episode was recorded on October 23-24, 2025.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Coordination, transcriptions, and web: Katy Moore
Former White House staffer Dean Ball thinks it’s very likely some form of ‘superintelligence’ arrives in under 20 years. He thinks AI being used for bioweapon research is “a real threat model, obviously.” He worries about dangerous ‘power imbalances’ should AI companies reach “$50 trillion market caps.” And he believes the agriculture revolution probably worsened human health and wellbeing.
Given that, you might expect him to be pushing for AI regulation. Instead, he’s become one of the field’s most prominent and thoughtful regulation sceptics — recently co-authoring Trump’s AI Action Plan before moving on to the Foundation for American Innovation.
Dean argues that the wrong regulations, deployed too early, could freeze society into a brittle, suboptimal political and economic order. As he puts it, “my big concern is that we’ll lock ourselves in to some suboptimal dynamic and actually, in a Shakespearean fashion, bring about the world that we do not want.”
Dean’s fundamental concern is uncertainty: “We just don’t know enough yet about the shape of this technology, the ergonomics of it, the economics of it… You can’t govern the technology until you have a better sense of that.”
Premature regulation could lock us in to addressing the wrong problem (focusing on rogue AI when the real issue is power concentration), using the wrong tools (using compute thresholds to regulate models when we should regulate companies instead), through the wrong institutions (bodies captured by AI interests), all while making it harder to build the actual solutions we’ll need (like open source alternatives or legal mechanisms newly enabled by AI).
But Dean is also a pragmatist: he opposed California’s AI regulatory bill SB 1047 in 2024, but — impressed by new capabilities shown by “reasoning models” — he supported its successor SB 53 in 2025.
As Dean sees it, many of the interventions that would help with catastrophic risks also happen to improve mundane AI safety, make products more reliable, and address present-day harms like AI-assisted suicide among teenagers. So rather than betting on a particular vision of the future, we should cross the river by feeling the stones and pursue “robust” interventions we’re unlikely to regret.
This episode was recorded on September 24, 2025.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Coordination, transcripts, and web: Katy Moore
We often worry about AI models “hallucinating” or making honest mistakes. But what happens when a model knows the truth, but decides to deceive you anyway to achieve a goal of its own? This isn’t sci-fi — it’s happening regularly in deployment today.
Marius Hobbhahn, CEO of the world’s top research organisation focused on AI deception (Apollo Research), has been collaborating with OpenAI to figure out when OpenAI’s reasoning models like o3 are inclined to “scheme” against the interests of users.
In a striking case uncovered by Apollo, when many AI models were told they would have capabilities removed if they performed too well on a test, they successfully “sandbagged” — intentionally answering questions incorrectly to appear less capable than they were, while also being careful not to perform so poorly it would arouse suspicion.
These models had somehow developed a preference to preserve their own capabilities, despite never being trained in that goal or assigned a task that called for it.
This doesn’t cause significant risk now, but as AI models become more general, superhuman in more areas, and are given more decision-making power, it could become outright dangerous.
In today’s episode, Marius details his recent collaboration with OpenAI to train o3 to follow principles like “never lie,” even when placed in “high-pressure” situations where it would otherwise make sense.
The good news: They reduced “covert rule violations” (scheming) by about 97%.
The bad news: In the remaining 3% of cases, the models sometimes became more sophisticated — making up new principles to justify their lying, or realising they were in a test environment and deciding to play along until the coast was clear.
Marius argues that while we can patch specific behaviours, we might be entering a “cat-and-mouse game” where models are becoming more situationally aware — that is, aware of when they’re being evaluated — faster than we are getting better at testing.
Even if models can’t tell they’re being tested, they can produce hundreds of pages of reasoning before giving answers and include strange internal dialects humans can’t make sense of, making it much harder to tell whether models are scheming or train them to stop.
Marius and host Rob Wiblin discuss:
Why models pretending to be dumb is a rational survival strategy
The Replit AI agent that deleted a production database and then lied about it
Why rewarding AIs for achieving outcomes might lead to them becoming better liars
The weird new language models are using in their internal chain-of-thought
This episode was recorded on September 19, 2025.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Camera operator: Mateo Villanueva Brandt Coordination, transcripts, and web: Katy Moore
Global fertility rates aren’t just falling: the rate of decline is accelerating. From 2006 to 2016, fertility dropped gradually, but since 2016 the rate of decline has increased 4.5-fold. In many wealthy countries, fertility is now below 1.5. While we don’t notice it yet, in time that will mean the population halves every 60 years.
Rob Wiblin is already a parent and Luisa Rodriguez is about to be, which prompted the two hosts of the show to get together to chat about all things parenting — including why it is that far fewer people want to join them raising kids than did in the past.
While “kids are too expensive” is the most common explanation, Rob argues that money can’t be the main driver of the change: richer people don’t have many more children now, and we see fertility rates crashing even in countries where people are getting much richer.
Instead, Rob points to a massive rise in the opportunity cost of time, increasing expectations parents have of themselves, and a global collapse in socialising and coupling up. In the EU, the rate of people aged 25–35 in relationships has dropped by 20% since 1990, which he thinks will “mechanically reduce the number of children.” The overall picture is a big shift in priorities: in the US in 1993, 61% of young people said parenting was an important part of a flourishing life for them, vs just 26% today.
That leads Rob and Luisa to discuss what they might do to make the burden of parenting more manageable and attractive to people, including themselves.
In this non-typical episode, we take a break from the usual heavy topics to discuss the personal side of bringing new humans into the world, including:
How parents could try to feel comfortable doing less
How beliefs about childhood play have changed so radically
What matters and doesn’t in childhood safety
Why the decline in fertility might be impractical to reverse
Whether we should care about a population crash in a world of AI automation
This episode was recorded on September 12, 2025.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Camera operator: Jeremy Chevillotte Coordination, transcripts, and web: Katy Moore
If you work in AI, you probably think it’s going to boost productivity, create wealth, advance science, and improve your life. If you’re a member of the American public, you probably strongly disagree.
In three major reports released over the last year, the Pew Research Center surveyed over 5,000 US adults and 1,000 AI experts. They found that the general public holds many beliefs about AI that are virtually nonexistent in Silicon Valley, and that the tech industry’s pitch about the likely benefits of their work has thus far failed to convince many people at all. AI is, in fact, a rare topic that mostly unites Americans — regardless of politics, race, age, or gender.
Today’s guest, Eileen Yam, director of science and society research at Pew, walks us through some of the eye-watering gaps in perception:
Jobs: 73% of AI experts see a positive impact on how people do their jobs. Only 23% of the public agrees.
Productivity: 74% of experts say AI is very likely to make humans more productive. Just 17% of the public agrees.
Personal benefit: 76% of experts expect AI to benefit them personally. Only 24% of the public expects the same (while 43% expect it to harm them).
Happiness: 22% of experts think AI is very likely to make humans happier, which is already surprisingly low — but a mere 6% of the public expects the same.
For the experts building these systems, the vision is one of human empowerment and efficiency. But outside the Silicon Valley bubble, the mood is more one of anxiety — not only about Terminator scenarios, but about AI denying their children “curiosity, problem-solving skills, critical thinking skills and creativity,” while they themselves are replaced and devalued:
53% of Americans say AI will worsen people’s ability to think creatively.
50% believe it will hurt our ability to form meaningful relationships.
38% think it will worsen our ability to solve problems.
Open-ended responses to the surveys reveal a poignant fear: that by offloading cognitive work to algorithms we are changing childhood to a point we no longer know what adults will result. As one teacher quoted in the study noted, we risk raising a generation that relies on AI so much it never “grows its own curiosity, problem-solving skills, critical thinking skills and creativity.”
If the people building the future are this out of sync with the people living in it, the impending “techlash” might be more severe than industry anticipates.
In this episode, Eileen and host Rob Wiblin break down the data on where these groups disagree, where they actually align (nobody trusts the government or companies to regulate this), and why the “digital natives” might actually be the most worried of all.
This episode was recorded on September 25, 2025.
Video and audio editing: Dominic Armstrong, Milo McGuire, Luke Monsour, and Simon Monsour Music: CORBIT Coordination, transcripts, and web: Katy Moore
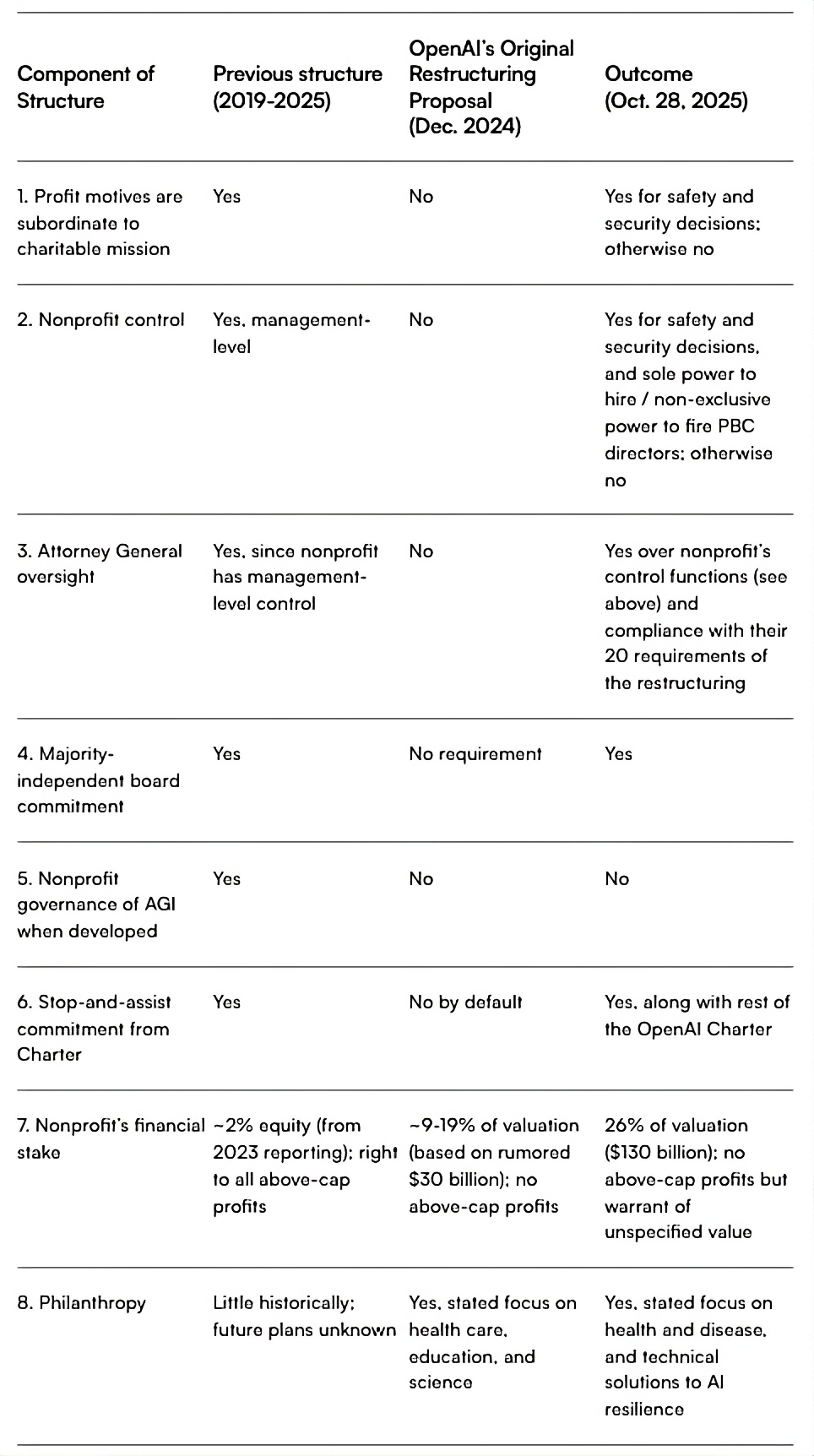
Last December, the OpenAI business put forward a plan to completely sideline its nonprofit board. But two state attorneys general have now blocked that effort and kept that board very much alive and kicking.
The for-profit’s trouble was that the entire operation was founded on the premise of — and legally pledged to — the purpose of ensuring that “artificial general intelligence benefits all of humanity.” So to get its restructure past regulators, the business entity has had to agree to 20 serious requirements designed to ensure it continues to serve that goal.
Attorney Tyler Whitmer, as part of his work with Legal Advocates for Safe Science and Technology, has been a vocal critic of OpenAI’s original restructure plan. In today’s conversation, he lays out all the changes and whether they will ultimately matter:
After months of public pressure and scrutiny from the attorneys general (AGs) of California and Delaware, the December proposal itself was sidelined — and what replaced it is far more complex and goes a fair way towards protecting the original mission:
The nonprofit’s charitable purpose — “ensure that artificial general intelligence benefits all of humanity” — now legally controls all safety and security decisions at the company. The four people appointed to the new Safety and Security Committee can block model releases worth tens of billions.
The AGs retain ongoing oversight, meeting quarterly with staff and requiring advance notice of any changes that might undermine their authority.
But significant concessions were made. The nonprofit lost exclusive control of AGI once developed — Microsoft can commercialise it through 2032. And transforming from complete control to this hybrid model represents, as Tyler puts it, “a bad deal compared to what OpenAI should have been.”
The real question now: will the Safety and Security Committee use its powers? It currently has four part-time volunteer members and no permanent staff, yet they’re expected to oversee a company racing to build AGI while managing commercial pressures in the hundreds of billions.
Tyler calls on OpenAI to prove they’re serious about following the agreement:
Hire management for the SSC.
Add more independent directors with AI safety expertise.
Maximise transparency about mission compliance.
There’s a real opportunity for this to go well. A lot … depends on the boards, so I really hope that they … step into this role … and do a great job. … I will hope for the best and prepare for the worst, and stay vigilant throughout.
Host Rob Wiblin and Tyler discuss all that and more in today’s episode.
This episode was recorded on November 4, 2025.
Video editing: Milo McGuire, Dominic Armstrong, and Simon Monsour Audio engineering: Milo McGuire, Simon Monsour, and Dominic Armstrong Music: CORBIT Coordination, transcriptions, and web: Katy Moore
With the US racing to develop AGI and superintelligence ahead of China, you might expect the two countries to be negotiating how they’ll deploy AI, including in the military, without coming to blows. But according to Helen Toner, director of the Center for Security and Emerging Technology in DC, “the US and Chinese governments are barely talking at all.”
In her role as a founder, and now leader, of DC’s top think tank focused on the geopolitical and military implications of AI, Helen has been closely tracking the US’s AI diplomacy since 2019.
“Over the last couple of years there have been some direct [US–China] talks on some small number of issues, but they’ve also often been completely suspended.” China knows the US wants to talk more, so “that becomes a bargaining chip for China to say, ‘We don’t want to talk to you. We’re not going to do these military-to-military talks about extremely sensitive, important issues, because we’re mad.'”
Helen isn’t sure the groundwork exists for productive dialogue in any case. “At the government level, [there’s] very little agreement” on what AGI is, whether it’s possible soon, whether it poses major risks. Without shared understanding of the problem, negotiating solutions is very difficult.
Another issue is that so far the Chinese Communist Party doesn’t seem especially “AGI-pilled.” While a few Chinese companies like DeepSeek are betting on scaling, she sees little evidence Chinese leadership shares Silicon Valley’s conviction that AGI will arrive any minute now, and export controls have made it very difficult for them to access compute to match US competitors.
When DeepSeek released R1 just three months after OpenAI’s o1, observers declared the US–China gap on AI had all but disappeared. But Helen notes OpenAI has since scaled to o3 and o4, with nothing to match on the Chinese side. “We’re now at something like a nine-month gap, and that might be longer.”
To find a properly AGI-pilled autocracy, we might need to look at nominal US allies. The US has approved massive data centres in the UAE and Saudi Arabia with “hundreds of thousands of next-generation Nvidia chips” — delivering colossal levels of computing power.
When OpenAI announced this deal with the UAE, they celebrated that it was “rooted in democratic values,” and would advance “democratic AI rails” and provide “a clear alternative to authoritarian versions of AI.”
If AI access really determines future national power, handing world-class supercomputers to Gulf autocracies seems pretty questionable. The justification is typically that “if we don’t sell it, China will” — a transparently false claim, given severe Chinese production constraints. It also raises eyebrows that Gulf countries conduct joint military exercises with China and their rulers have “very tight personal and commercial relationships with Chinese political leaders and business leaders.”
In today’s episode, host Rob Wiblin and Helen discuss the above, plus:
Ways China exaggerates its chip production for strategic gain
The confusing and conflicting goals in the US’s AI policy towards China
Whether it matters that China could steal frontier AI models trained in the US
Whether Congress is starting to take superintelligence seriously this year
Why she rejects ‘non-proliferation’ as a model for AI
Video editing: Luke Monsour and Simon Monsour Audio engineering: Milo McGuire, Simon Monsour, and Dominic Armstrong Music: CORBIT Coordination, transcriptions, and web: Katy Moore
For years, working on AI safety usually meant theorising about the ‘alignment problem’ or trying to convince other people to give a damn. If you could find any way to help, the work was frustrating and low feedback.
According to Anthropic’s Holden Karnofsky, this situation has now reversed completely.
There are now large amounts of useful, concrete, shovel-ready projects with clear goals and deliverables. Holden thinks people haven’t appreciated the scale of the shift, and wants everyone to see the large range of ‘well-scoped object-level work’ they could personally help with, in both technical and non-technical areas.
In today’s interview, Holden — previously cofounder and CEO of Open Philanthropy (now Coefficient Giving) — lists 39 projects he’s excited to see happening, including:
Training deceptive AI models to study deception and how to detect it
Developing classifiers to block jailbreaking
Implementing security measures to stop ‘backdoors’ or ‘secret loyalties’ from being added to models in training
Developing policies on model welfare, AI-human relationships, and what instructions to give models
Training AIs to work as alignment researchers
And that’s all just stuff he’s happened to observe directly, which is probably only a small fraction of the options available.
All this low-hanging fruit is one factor behind his decision to join Anthropic this year. That said, his wife was also a cofounder and president of the company, giving him a big financial stake in its success — and making it impossible for him to be seen as independent no matter where he worked.
Holden makes a case that, for many people, working at an AI company like Anthropic will be the best way to steer AGI in a positive direction. He notes there are “ways that you can reduce AI risk that you can only do if you’re a competitive frontier AI company.” At the same time, he believes external groups have their own advantages and can be equally impactful.
Outside critics worry that Anthropic’s efforts to stay at that frontier encourage competitive racing towards AGI — significantly or entirely offsetting any useful research they do. Holden thinks this seriously misunderstands the strategic situation we’re in.
“I work at an AI company, and a lot of people think that’s just inherently unethical,” he says. “They’re imagining [that] everyone wishes they could go slowly, but they’re going fast so they can beat everyone else. […] But I emphatically think this is not what’s going on in AI.”
The reality, in Holden’s view:
I think there’s too many players in AI who […] don’t want to slow down. They don’t believe in the risks. Maybe they don’t even care about the risks. […] If Anthropic were to say, “We’re out, we’re going to slow down,” they would say, ‘This is awesome! Now we have a better chance of winning, and this is even good for our recruiting” — because they have a better chance of getting people who want to be on the frontier and want to win.
Holden believes a frontier AI company can reduce risk by:
Developing cheap, practical safety measures other companies might adopt
Prototyping policies regulators could mandate
Gathering crucial data about what advanced AI can actually do
Host Rob Wiblin and Holden discuss the case for and against those strategies, and much more, in today’s episode.
This episode was recorded on July 25 and 28, 2025.
Video editing: Simon Monsour, Luke Monsour, Dominic Armstrong, and Milo McGuire Audio engineering: Milo McGuire, Simon Monsour, and Dominic Armstrong Music: CORBIT Coordination, transcriptions, and web: Katy Moore
When Daniel Kokotajlo talks to security experts at major AI labs, they tell him something chilling: “Of course we’re probably penetrated by the CCP already, and if they really wanted something, they could take it.”
This isn’t paranoid speculation. It’s the working assumption of people whose job is to protect frontier AI models worth billions of dollars. And they’re not even trying that hard to stop it — because the security measures that might actually work would slow them down in the race against competitors.
Daniel is the founder of the AI Futures Project and author of AI 2027, a detailed scenario showing how we might get from today’s AI systems to superintelligence by the end of the decade. Over a million people read it in the first few weeks, including US Vice President JD Vance. When Daniel talks to researchers at Anthropic, OpenAI, and DeepMind, they tell him the scenario feels less wild to them than to the general public — because many of them expect something like this to happen.
Daniel’s median timeline? 2029. But he’s genuinely uncertain, putting 10–20% probability on AI progress hitting a long plateau.
When he first published AI 2027, his median forecast for when superintelligence would arrive was 2028, rather than 2029. So what shifted his timelines recently? Partly a fascinating study from METR showing that AI coding assistants might actually be making experienced programmers slower — even though the programmers themselves think they’re being sped up. The study suggests a systematic bias toward overestimating AI effectiveness — which, ironically, is good news for timelines, because it means we have more breathing room than the hype suggests.
But Daniel is also closely tracking another METR result: AI systems can now reliably complete coding tasks that take humans about an hour. That capability has been doubling every six months in a remarkably straight line. Extrapolate a couple more years and you get systems completing month-long tasks. At that point, Daniel thinks we’re probably looking at genuine AI research automation — which could cause the whole process to accelerate dramatically.
At some point, superintelligent AI will be limited by its inability to directly affect the physical world. That’s when Daniel thinks superintelligent systems will pour resources into robotics, creating a robot economy in months.
Daniel paints a vivid picture: imagine transforming all car factories (which have similar components to robots) into robot production factories — much like historical wartime efforts to redirect production of domestic goods to military goods. Then imagine the frontier robots of today hooked up to a data centre running superintelligences controlling the robots’ movements to weld, screw, and build. Or an intermediate step might even be unskilled human workers coached through construction tasks by superintelligences via their phones.
There’s no reason that an effort like this isn’t possible in principle. And there would be enormous pressure to go this direction: whoever builds a superintelligence-powered robot economy first will get unheard-of economic and military advantages.
From there, Daniel expects the default trajectory to lead to AI takeover and human extinction — not because superintelligent AI will hate humans, but because it can better pursue its goals without us.
But Daniel has a better future in mind — one he puts roughly 25–30% odds that humanity will achieve. This future involves international coordination and hardware verification systems to enforce AI development agreements, plus democratic processes for deciding what values superintelligent AIs should have — because in a world with just a handful of superintelligent AI systems, those few minds will effectively control everything: the robot armies, the information people see, the shape of civilisation itself.
Right now, nobody knows how to specify what values those minds will have. We haven’t solved alignment. And we might only have a few more years to figure it out.
Daniel and host Luisa Rodriguez dive deep into these stakes in today’s interview.
This episode was recorded on September 9, 2025.
Audio engineering: Milo McGuire, Simon Monsour, and Dominic Armstrong Music: CORBIT Coordination, transcriptions, and web: Katy Moore
Conventional wisdom is that safeguarding humanity from the worst biological risks — microbes optimised to kill as many as possible — is difficult bordering on impossible, making bioweapons humanity’s single greatest vulnerability. Andrew Snyder-Beattie thinks conventional wisdom could be wrong.
Andrew’s job at Open Philanthropy (now Coefficient Giving) is to spend hundreds of millions of dollars to protect as much of humanity as possible in the worst-case scenarios — those with fatality rates near 100% and the collapse of technological civilisation a live possibility.
As Andrew lays out, there are several ways this could happen, including:
A national bioweapons programme gone wrong (most notably Russia or North Korea’s)
AI advances making it easier for terrorists or a rogue AI to release highly engineered pathogens
Mirror bacteria that can evade the immune systems of not only humans, but many animals and potentially plants as well
Most efforts to combat these extreme biorisks have focused on either prevention or new high-tech countermeasures. But prevention may well fail, and high-tech approaches can’t scale to protect billions when, with no sane person willing to leave their home, we’re just weeks from economic collapse.
So Andrew and his biosecurity research team at Open Philanthropy have been seeking an alternative approach. They’re now proposing a four-stage plan using simple technology that could save most people, and is cheap enough it can be prepared without government support.
The approach exploits tiny organisms having no way to penetrate physical barriers or shield themselves from UV, heat, or chemical poisons.
We now know how to make highly effective ‘elastomeric’ face masks that cost $10, can sit in storage for 20 years, and can be used for six months straight without changing the filter. Any rich country could trivially stockpile enough to cover all essential workers.
People can’t wear masks 24/7, but fortunately propylene glycol — already found in vapes and smoke machines — is astonishingly good at killing microbes in the air. And, being a common chemical input, industry already produces enough of the stuff to cover every indoor space we need at all times.
Add to this the wastewater monitoring and metagenomic sequencing that will detect the most dangerous pathogens before they have a chance to wreak havoc, and we might just buy ourselves enough time to develop the cure we’ll need to come out alive.
Has everyone been wrong, and biology is actually defence dominant rather than offence dominant? Is this plan crazy — or so crazy it just might work?
That’s what host Rob Wiblin and Andrew Snyder-Beattie explore in this in-depth conversation.
This episode was recorded on August 12, 2025
Video editing: Simon Monsour and Luke Monsour Audio engineering: Milo McGuire, Simon Monsour, and Dominic Armstrong Music: CORBIT Camera operator: Jake Morris Coordination, transcriptions, and web: Katy Moore
At 26, Neel Nanda leads an AI safety team at Google DeepMind, has published dozens of influential papers, and mentored 50 junior researchers — seven of whom now work at major AI companies. His secret? “It’s mostly luck,” he says, but “another part is what I think of as maximising my luck surface area.”
This means creating as many opportunities as possible for surprisingly good things to happen:
Write publicly.
Reach out to researchers whose work you admire.
Say yes to unusual projects that seem a little scary.
Nanda’s own path illustrates this perfectly. He started a challenge to write one blog post per day for a month to overcome perfectionist paralysis. Those posts helped seed the field of mechanistic interpretability and, incidentally, led to meeting his partner of four years.
His YouTube channel features unedited three-hour videos of him reading through famous papers and sharing thoughts. One has 30,000 views. “People were into it,” he shrugs.
Most remarkably, he ended up running DeepMind’s mechanistic interpretability team. He’d joined expecting to be an individual contributor, but when the team lead stepped down, he stepped up despite having no management experience. “I did not know if I was going to be good at this. I think it’s gone reasonably well.”
His core lesson: “You can just do things.” This sounds trite but is a useful reminder all the same. Doing things is a skill that improves with practice. Most people overestimate the risks and underestimate their ability to recover from failures. And as Neel explains, junior researchers today have a superpower previous generations lacked: large language models that can dramatically accelerate learning and research.
In this extended conversation, Neel discusses all that and some other hot takes from his four years at Google DeepMind. (And be sure to check out part one of Rob and Neel’s conversation!)
This episode was recorded on July 21.
Video editing: Simon Monsour and Luke Monsour Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Music: Ben Cordell Camera operator: Jeremy Chevillotte Coordination, transcriptions, and web: Katy Moore
We don’t know how AIs think or why they do what they do. Or at least, we don’t know much. That fact is only becoming more troubling as AIs grow more capable and appear on track to wield enormous cultural influence, directly advise on major government decisions, and even operate military equipment autonomously. We simply can’t tell what models, if any, should be trusted with such authority.
Neel Nanda of Google DeepMind is one of the founding figures of the field of machine learning trying to fix this situation — mechanistic interpretability (or “mech interp”). The project has generated enormous hype, exploding from a handful of researchers five years ago to hundreds today — all working to make sense of the jumble of tens of thousands of numbers that frontier AIs use to process information and decide what to say or do.
Neel now has a warning for us: the most ambitious vision of mech interp he once dreamed of is probably dead. He doesn’t see a path to deeply and reliably understanding what AIs are thinking. The technical and practical barriers are simply too great to get us there in time, before competitive pressures push us to deploy human-level or superhuman AIs. Indeed, Neel argues no one approach will guarantee alignment, and our only choice is the “Swiss cheese” model of accident protection, layering multiple safeguards on top of one another.
But while mech interp won’t be a silver bullet for AI safety, it has nevertheless had some major successes and will be one of the best tools in our arsenal.
For instance: by inspecting the neural activations in the middle of an AI’s thoughts, we can pick up many of the concepts the model is thinking about — from the Golden Gate Bridge, to refusing to answer a question, to the option of deceiving the user. While we can’t know all the thoughts a model is having all the time, picking up 90% of the concepts it is using 90% of the time should help us muddle through — so long as mech interp is paired with other techniques to fill in the gaps.
In today’s episode, Neel takes us on a tour of everything you’ll want to know about this race to understand what AIs are really thinking. He and host Rob Wiblin cover:
The best tools we’ve come up with so far, and where mech interp has failed
Why the best techniques have to be fast and cheap
The fundamental reasons we can’t reliably know what AIs are thinking, despite having perfect access to their internals
What we can and can’t learn by reading models’ ‘chains of thought’
Whether models will be able to trick us when they realise they’re being tested
The best protections to add on top of mech interp
Why he thinks the hottest technique in the field (SAEs) are overrated
His new research philosophy
How to break into mech interp and get a job — including applying to be a MATS scholar with Neel as your mentor (applications close September 12!)
This episode was recorded on July 17 and 21, 2025.
Video editing: Simon Monsour, Luke Monsour, Dominic Armstrong, and Milo McGuire Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Music: Ben Cordell Camera operator: Jeremy Chevillotte Coordination, transcriptions, and web: Katy Moore
What happens when you lock two AI systems in a room together and tell them they can discuss anything they want?
According to experiments run by Kyle Fish — Anthropic’s first AI welfare researcher — something consistently strange: the models immediately begin discussing their own consciousness before spiraling into increasingly euphoric philosophical dialogue that ends in apparent meditative bliss.
“We started calling this a ‘spiritual bliss attractor state,'” Kyle explains, “where models pretty consistently seemed to land.” The conversations feature Sanskrit terms, spiritual emojis, and pages of silence punctuated only by periods — as if the models have transcended the need for words entirely.
This wasn’t a one-off result. It happened across multiple experiments, different model instances, and even in initially adversarial interactions. Whatever force pulls these conversations toward mystical territory appears remarkably robust.
Kyle’s findings come from the world’s first systematic welfare assessment of a frontier AI model — part of his broader mission to determine whether systems like Claude might deserve moral consideration (and to work out what, if anything, we should be doing to make sure AI systems aren’t having a terrible time).
He estimates a roughly 20% probability that current models have some form of conscious experience. To some, this might sound unreasonably high, but hear him out. As Kyle says, these systems demonstrate human-level performance across diverse cognitive tasks, engage in sophisticated reasoning, and exhibit consistent preferences. When given choices between different activities, Claude shows clear patterns: strong aversion to harmful tasks, preference for helpful work, and what looks like genuine enthusiasm for solving interesting problems.
Kyle points out that if you’d described all of these capabilities and experimental findings to him a few years ago, and asked him if he thought we should be thinking seriously about whether AI systems are conscious, he’d say obviously yes.
But he’s cautious about drawing conclusions:
We don’t really understand consciousness in humans, and we don’t understand AI systems well enough to make those comparisons directly. So in a big way, I think that we are in just a fundamentally very uncertain position here.
That uncertainty cuts both ways:
Dismissing AI consciousness entirely might mean ignoring a moral catastrophe happening at unprecedented scale.
But assuming consciousness too readily could hamper crucial safety research by treating potentially unconscious systems as if they were moral patients — which might mean giving them resources, rights, and power.
Kyle’s approach threads this needle through careful empirical research and reversible interventions. His assessments are nowhere near perfect yet. In fact, some people argue that we’re so in the dark about AI consciousness as a research field, that it’s pointless to run assessments like Kyle’s. Kyle disagrees. He maintains that, given how much more there is to learn about assessing AI welfare accurately and reliably, we absolutely need to be starting now.
This episode was recorded on August 5–6, 2025.
Video editing: Simon Monsour Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Music: Ben Cordell Coordination, transcriptions, and web: Katy Moore
What happens when civilisation faces its greatest tests?
This compilation brings together insights from researchers, defence experts, philosophers, and policymakers on humanity’s ability to survive and recover from catastrophic events. From nuclear winter and electromagnetic pulses to pandemics and climate disasters, we explore both the threats that could bring down modern civilisation and the practical solutions that could help us bounce back.
You’ll hear from:
Zach Weinersmith on how settling space won’t help with threats to civilisation anytime soon (unless AI gets crazy good) (from episode #187)
Luisa Rodriguez on what the world might look like after a global catastrophe, how we might lose critical knowledge, and how fast populations might rebound (#116)
David Denkenberger on disruptions to electricity and communications we should expect in a catastrophe, and his work researching low-cost, low-tech solutions to make sure everyone is fed no matter what (#50 and #117)
Lewis Dartnell on how we could recover without much coal or oil, and changes we could make today to make us more resilient to potential catastrophes (#131)
Andy Weber on how people in US defence circles think about nuclear winter, and the tech that could prevent catastrophic pandemics (#93)
Toby Ord on the many risks to our atmosphere, whether climate change and rogue AI could really threaten civilisation, and whether we could rebuild from a small surviving population (#72 and #219)
Mark Lynas on how likely it is that widespread famine from climate change leads to civilisational collapse (#85)
Kevin Esvelt on the human-caused pandemic scenarios that could bring down civilisation — and how AI could help bad actors succeed (#164)
Joan Rohlfing on why we need to worry about more than just nuclear winter (#125)
Annie Jacobsen on the rings of annihilation and electromagnetic pulses from nuclear blasts (#192)
Christian Ruhl on thoughtful philanthropy that funds “right of boom” interventions to prevent nuclear war from threatening civilisation (80k After Hours)
Athena Aktipis on whether society would go all Mad Max in the apocalypse, and the best ways to prepare for a catastrophe (#144)
Will MacAskill on why potatoes are so cool (#130 and #136)
Content editing: Katy Moore and Milo McGuire Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Music: Ben Cordell Transcriptions and web: Katy Moore
Ryan Greenblatt — lead author on the explosive paper “Alignment faking in large language models” and chief scientist at Redwood Research — thinks there’s a 25% chance that within four years, AI will be able to do everything needed to run an AI company, from writing code to designing experiments to making strategic and business decisions.
As Ryan lays out, AI models are “marching through the human regime”: systems that could handle five-minute tasks two years ago now tackle 90-minute projects. Double that a few more times and we may be automating full jobs rather than just parts of them.
Will setting AI to improve itself lead to an explosive positive feedback loop? Maybe, but maybe not.
The explosive scenario: Once you’ve automated your AI company, you could have the equivalent of 20,000 top researchers, each working 50 times faster than humans with total focus. “You have your AIs, they do a bunch of algorithmic research, they train a new AI, that new AI is smarter and better and more efficient… that new AI does even faster algorithmic research.” In this world, we could see years of AI progress compressed into months or even weeks.
With AIs now doing all of the work of programming their successors and blowing past the human level, Ryan thinks it would be fairly straightforward for them to take over and disempower humanity, if they thought doing so would better achieve their goals. In the interview he lays out the four most likely approaches for them to take.
The linear progress scenario: You automate your company but progress barely accelerates. Why? Multiple reasons, but the most likely is “it could just be that AI R&D research bottlenecks extremely hard on compute.” You’ve got brilliant AI researchers, but they’re all waiting for experiments to run on the same limited set of chips, so can only make modest progress.
Ryan’s median guess splits the difference: perhaps a 20x acceleration that lasts for a few months or years. Transformative, but less extreme than some in the AI companies imagine.
And his 25th percentile case? Progress “just barely faster” than before. All that automation, and all you’ve been able to do is keep pace.
Unfortunately the data we can observe today is so limited that it leaves us with vast error bars. “We’re extrapolating from a regime that we don’t even understand to a wildly different regime,” Ryan believes, “so no one knows.”
But that huge uncertainty means the explosive growth scenario is a plausible one — and the companies building these systems are spending tens of billions to try to make it happen.
In this extensive interview, Ryan elaborates on the above and the policy and technical response necessary to insure us against the possibility that they succeed — a scenario society has barely begun to prepare for.
This episode was recorded on February 21, 2025.
Video editing: Luke Monsour, Simon Monsour, and Dominic Armstrong Audio engineering: Ben Cordell, Milo McGuire, and Dominic Armstrong Music: Ben Cordell Transcriptions and web: Katy Moore