Many people — with a diverse range of skills and experience — are urgently needed to help mitigate these risks.
I think you should consider making this the focus of your career.
This article explains why.
1) World-changing AI systems could come much sooner than people expect
In an earlier article I explained why there’s a significant chance that AI could contribute to scientific research or automate many jobs by 2030. Current systems can already do a lot, there are clear ways to continue to improve them in the coming years. Forecasters and experts widely agree that the probability of widespread disruption is much higher than it was even just a couple of years ago.
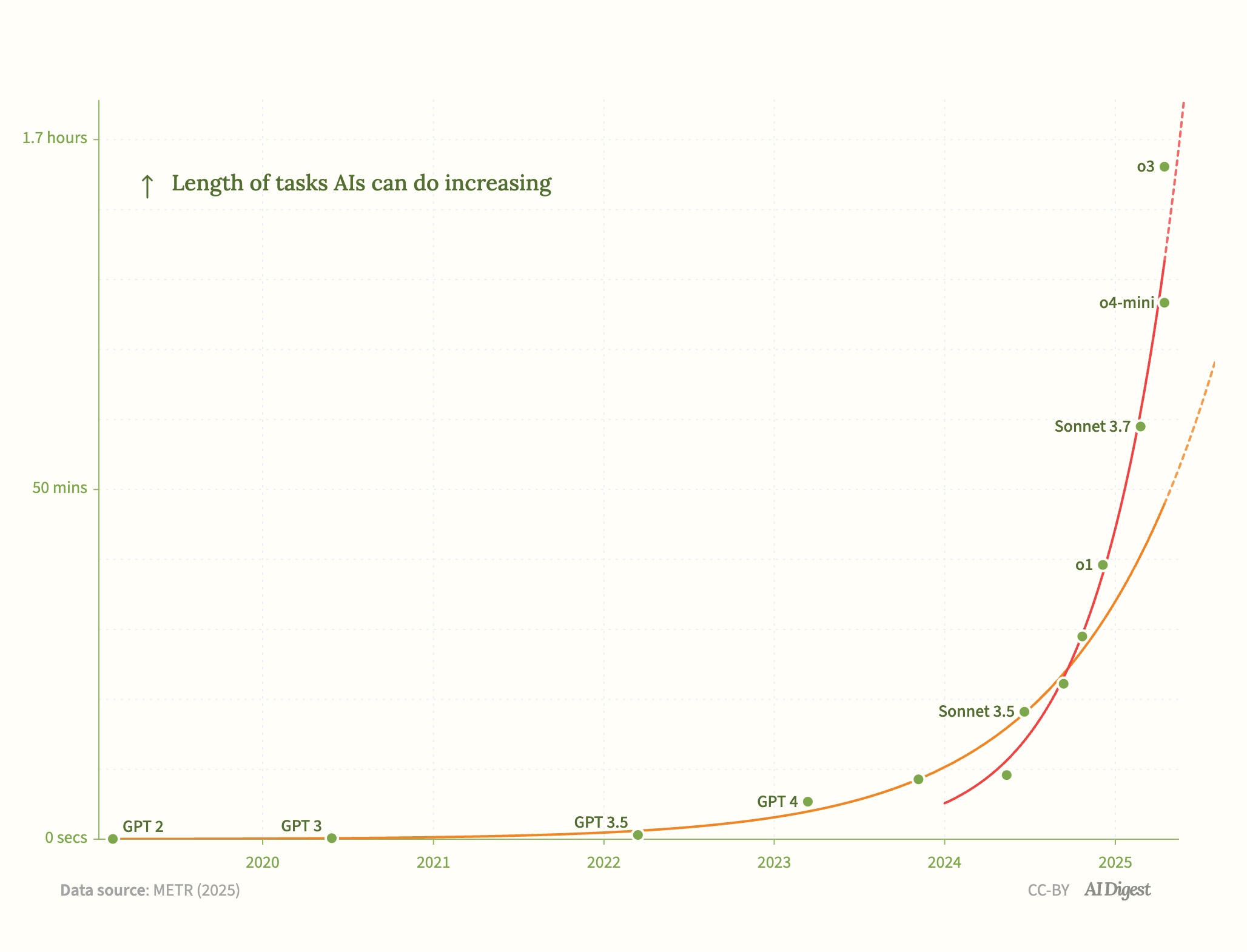
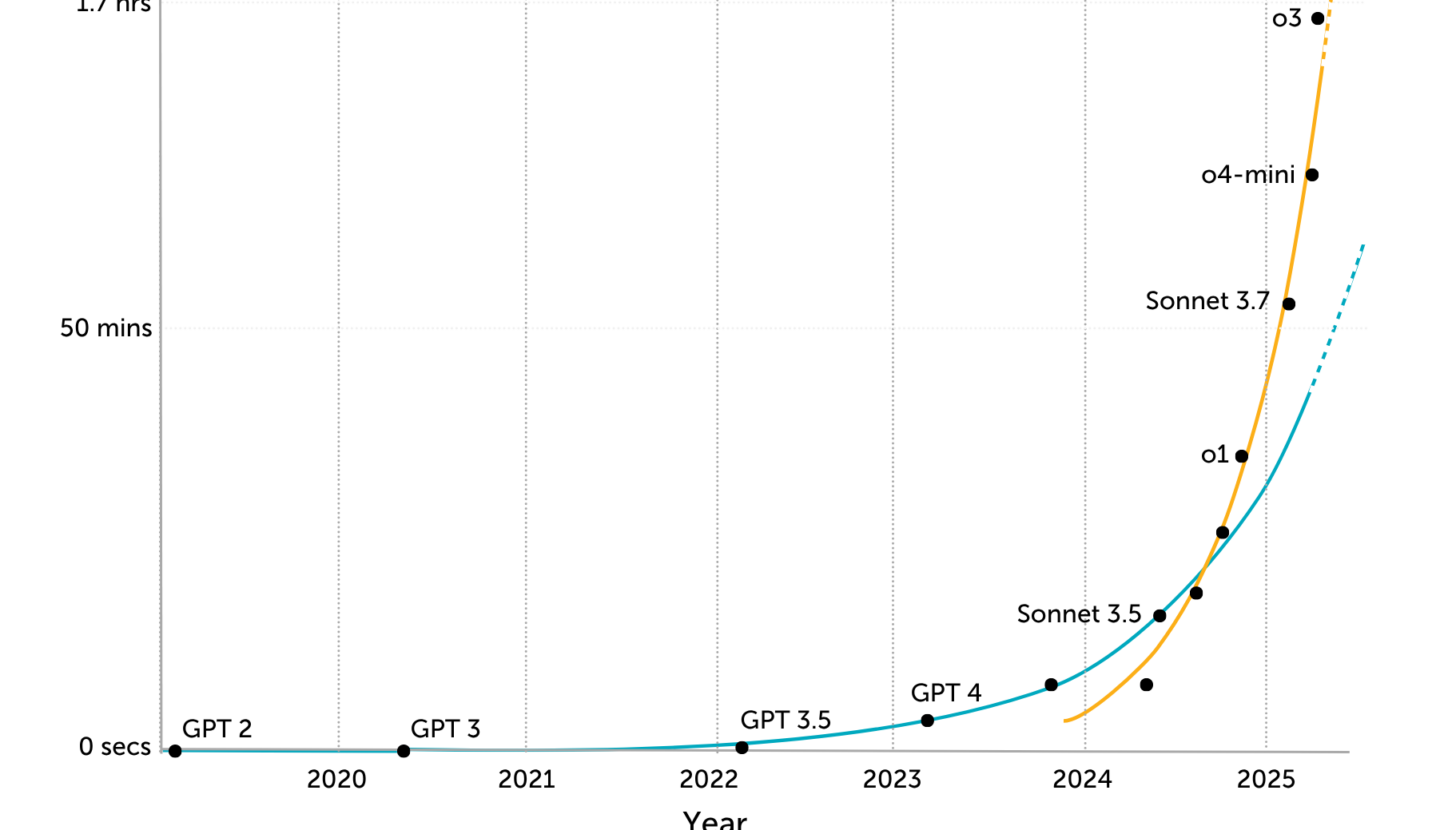
AI systems are rapidly becoming more autonomous, as measured by the METR time horizon benchmark. The most recent models, such as o3, seem to be on an even faster trend that started in 2024.
2) The impact on society could be explosive
People say AI will be transformative, but few really get just how wild it could be.
What happens when your desire to do good starts to undermine your own wellbeing?
Over the years, we’ve heard from therapists, charity directors, researchers, psychologists, and career advisors — all wrestling with how to do good without falling apart. Today’s episode brings together insights from 16 past guests on the emotional and psychological costs of pursuing a high-impact career to improve the world — and how to best navigate the all-too-common guilt, burnout, perfectionism, and imposter syndrome along the way.
You’ll hear from:
80,000 Hours’ former CEO on managing anxiety, self-doubt, and a chronic sense of falling short (from episode #100)
Randy Nesse on why we evolved to be anxious and depressed (episode #179)
Hannah Boettcher on how ‘optimisation framing’ can quietly distort our sense of self-worth (from our 80k After Hours feed)
Mental Health Navigator is a service that simplifies finding and accessing mental health information and resources all over the world — built specifically for the effective altruism community
Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Content editing: Katy Moore and Milo McGuire Transcriptions and web: Katy Moore
Podcast by Robert Wiblin · Published April 4th, 2025
Most AI safety conversations centre on alignment: ensuring AI systems share our values and goals. But despite progress, we’re unlikely to know we’ve solved the problem before the arrival of human-level and superhuman systems in as little as three years.
So some are developing a backup plan to safely deploy models we fear are actively scheming to harm us — so-called “AI control.” While this may sound mad, given the reluctance of AI companies to delay deploying anything they train, not developing such techniques is probably even crazier.
Today’s guest — Buck Shlegeris, CEO of Redwood Research — has spent the last few years developing control mechanisms, and for human-level systems they’re more plausible than you might think. He argues that given companies’ unwillingness to incur large costs for security, accepting the possibility of misalignment and designing robust safeguards might be one of our best remaining options.
Buck asks us to picture a scenario where, in the relatively near future, AI companies are employing 100,000 AI systems running 16 times faster than humans to automate AI research itself. These systems would need dangerous permissions: the ability to run experiments, access model weights, and push code changes. As a result, a misaligned system could attempt to hack the data centre, exfiltrate weights, or sabotage research. In such a world, misalignment among these AIs could be very dangerous.
But in the absence of a method for reliably aligning frontier AIs, Buck argues for implementing practical safeguards to prevent catastrophic outcomes. His team has been developing and testing a range of straightforward, cheap techniques to detect and prevent risky behaviour by AIs — such as auditing AI actions with dumber but trusted models, replacing suspicious actions, and asking questions repeatedly to catch randomised attempts at deception.
Most importantly, these methods are designed to be cheap and shovel-ready. AI control focuses on harm reduction using practical techniques — techniques that don’t require new, fundamental breakthroughs before companies could reasonably implement them, and that don’t ask us to forgo the benefits of deploying AI.
As Buck puts it:
Five years ago I thought of misalignment risk from AIs as a really hard problem that you’d need some really galaxy-brained fundamental insights to resolve. Whereas now, to me the situation feels a lot more like we just really know a list of 40 things where, if you did them — none of which seem that hard — you’d probably be able to not have very much of your problem.
Of course, even if Buck is right, we still need to do those 40 things — which he points out we’re not on track for. And AI control agendas have their limitations: they aren’t likely to work once AI systems are much more capable than humans, since greatly superhuman AIs can probably work around whatever limitations we impose.
Still, AI control agendas seem to be gaining traction within AI safety. Buck and host Rob Wiblin discuss all of the above, plus:
Why he’s more worried about AI hacking its own data centre than escaping
What to do about “chronic harm,” where AI systems subtly underperform or sabotage important work like alignment research
Why he might want to use a model he thought could be conspiring against him
Why he would feel safer if he caught an AI attempting to escape
Why many control techniques would be relatively inexpensive
How to use an untrusted model to monitor another untrusted model
What the minimum viable intervention in a “lazy” AI company might look like
How even small teams of safety-focused staff within AI labs could matter
The moral considerations around controlling potentially conscious AI systems, and whether it’s justified
This episode was originally recorded on February 21, 2025.
Video: Simon Monsour and Luke Monsour Audio engineering: Ben Cordell, Milo McGuire, and Dominic Armstrong Transcriptions and web: Katy Moore
Problem profile by Cody Fenwick · Published April 2025
The proliferation of advanced AI systems may lead to the gradual disempowerment of humanity, even if efforts to prevent them from becoming power-seeking or scheming are successful. Humanity may be incentivised to hand over increasing amounts of control to AIs, giving them power over the economy, politics, culture, and more. Over time, humanity’s interests may be sidelined and our control over the future undermined, potentially constituting an existential catastrophe.
There’s disagreement over how serious a problem this is and how it relates to other concerns about AI alignment. It’s also unclear, if this is a genuine risk, what we could do about it. But we think it’s potentially very important, and more people should work on clarifying the issue and perhaps figuring out how to address it.
Since 2016, we’ve ranked ‘risks from artificial intelligence’ as our top pressing problem. Whilst we’ve provided research and support on how to work on reducing AI risks since that point (and before!), we’ve put in varying amounts of investment over time and between programmes.
We think we should consolidate our effort and focus because:
We think that AGI by 2030 is plausible — and this is much sooner than most of us would have predicted five years ago. This is far from guaranteed, but we think the view is compelling based on analysis of the current flow of inputs into AI development and the speed of recent AI progress. You can read about this argument in far more detail in this new article.
We are in a window of opportunity to influence AGI, before laws and norms are set in place.
80,000 Hours has an opportunity to help more people take advantage of this window. We want our strategy to be responsive to changing events in the world, and we think that prioritising reducing risks from AI is probably the best way to achieve our high-level, cause-impartial goal of doing the most good for others over the long term by helping people have high-impact careers. We expect the landscape to move faster in the coming years, so we’ll need a faster moving culture to keep up.
What happens when a USB cable can secretly control your system? Are we hurtling toward a security nightmare as critical infrastructure connects to the internet? Is it possible to secure AI model weights from sophisticated attackers? And could AI might actually make computer security better rather than worse?
With AI security concerns becoming increasingly urgent, we bring you insights from 15 top experts across information security, AI safety, and governance, examining the challenges of protecting our most powerful AI models and digital infrastructure — including a sneak peek from an episode that hasn’t yet been released with Tom Davidson, where he explains how we should be more worried about “secret loyalties” in AI agents.
You’ll hear:
Holden Karnofsky on why every good future relies on strong infosec, and how hard it’s been to hire security experts (from episode #158)
Tantum Collins on why infosec might be the rare issue everyone agrees on (episode #166)
Nick Joseph on whether AI companies can develop frontier models safely with the current state of information security (episode #197)
Sella Nevo on why AI model weights are so valuable to steal, the weaknesses of air-gapped networks, and the risks of USBs (episode #195)
Kevin Esvelt on what cryptographers can teach biosecurity experts (episode #164)
Lennart Heim on on Rob’s computer security nightmares (episode #155)
Zvi Mowshowitz on the insane lack of security mindset at some AI companies (episode #184)
Nova DasSarma on the best current defences against well-funded adversaries, politically motivated cyberattacks, and exciting progress in infosecurity (episode #132)
Bruce Schneier on whether AI could eliminate software bugs for good, and why it’s bad to hook everything up to the internet (episode #64)
Nita Farahany on the dystopian risks of hacked neurotech (episode #174)
Vitalik Buterin on how cybersecurity is the key to defence-dominant futures (episode #194)
Nathan Labenz on how even internal teams at AI companies may not know what they’re building (episode #176)
Allan Dafoe on backdooring your own AI to prevent theft (episode #212)
Tom Davidson on how dangerous “secret loyalties” in AI models could be (episode to be released!)
Carl Shulman on the challenge of trusting foreign AI models (episode #191, part 2)
Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Content editing: Katy Moore and Milo McGuire Transcriptions and web: Katy Moore
We expect there will be substantial progress in AI in the coming years, potentially even to the point where machines come to outperform humans in many, if not all, tasks. This could have enormous benefits, helping to solve currently intractable global problems, but could also pose severe risks. These risks could arise accidentally (for example, if we don’t find technical solutions to concerns about the safety of AI systems), or deliberately (for example, if AI systems worsen geopolitical conflict). We think more work needs to be done to reduce these risks.
Some of these risks from advanced AI could be existential — meaning they could cause human extinction, or an equally permanent and severe disempowerment of humanity.1 There have not yet been any satisfying answers to concerns — discussed below — about how this rapidly approaching, transformative technology can be safely developed and integrated into our society. Finding answers to these concerns is neglected and may well be tractable. We estimated that there were around 400 people worldwide working directly on this in 2022, though we believe that number has grown.2 As a result, the possibility of AI-related catastrophe may be the world’s most pressing problem — and the best thing to work on for those who are well-placed to contribute.
Promising options for working on this problem include technical research on how to create safe AI systems, strategy research into the particular risks AI might pose, and policy research into ways in which companies and governments could mitigate these risks. As policy approaches continue to be developed and refined, we need people to put them in place and implement them. There are also many opportunities to have a big impact in a variety of complementary roles, such as operations management, journalism, earning to give, and more — some of which we list below.
In recent months, the CEOs of leading AI companies have grown increasingly confident about rapid progress:
OpenAI’s Sam Altman: Shifted from saying in November “the rate of progress continues” to declaring in January “we are now confident we know how to build AGI”
Anthropic’s Dario Amodei: Stated in January “I’m more confident than I’ve ever been that we’re close to powerful capabilities… in the next 2-3 years”
Google DeepMind’s Demis Hassabis: Changed from “as soon as 10 years” in autumn to “probably three to five years away” by January.
Is it just hype? What explains the shift? And could we really have Artificial General Intelligence (AGI) by 2028?
In this article, I interrogate these claims. I’ll examine what’s driven recent progress, estimate how far those drivers can continue, and explain why they’re likely to continue for at least four more years.
In particular, while in 2024 progress in LLM chatbots seemed to slow, a new approach started to work: teaching the models to reason using reinforcement learning.
In just a year, this let them surpass human PhDs at answering difficult scientific reasoning questions, and achieve expert-level performance on one-hour coding tasks.
We don’t know how capable AI will become, but extrapolating the recent rate of progress suggests that, by 2028, we could reach AI models with beyond-human reasoning abilities,
Blog post by Benjamin Todd · Published March 21st, 2025
As a non-expert, it would be great if there were experts who could tell us when we should expect artificial general intelligence (AGI) to arrive.
Unfortunately, there aren’t.
There are only different groups of experts with different weaknesses.
This article is an overview of what five different types of experts say about when we’ll reach AGI, and what we can learn from them (that feeds into my full article on forecasting AI).
In short:
Every group shortened their estimates in recent years.
AGI before 2030 seems within the range of expert opinion, even if many disagree.
None of the forecasts seem especially reliable, so they neither rule in nor rule out AGI arriving soon.
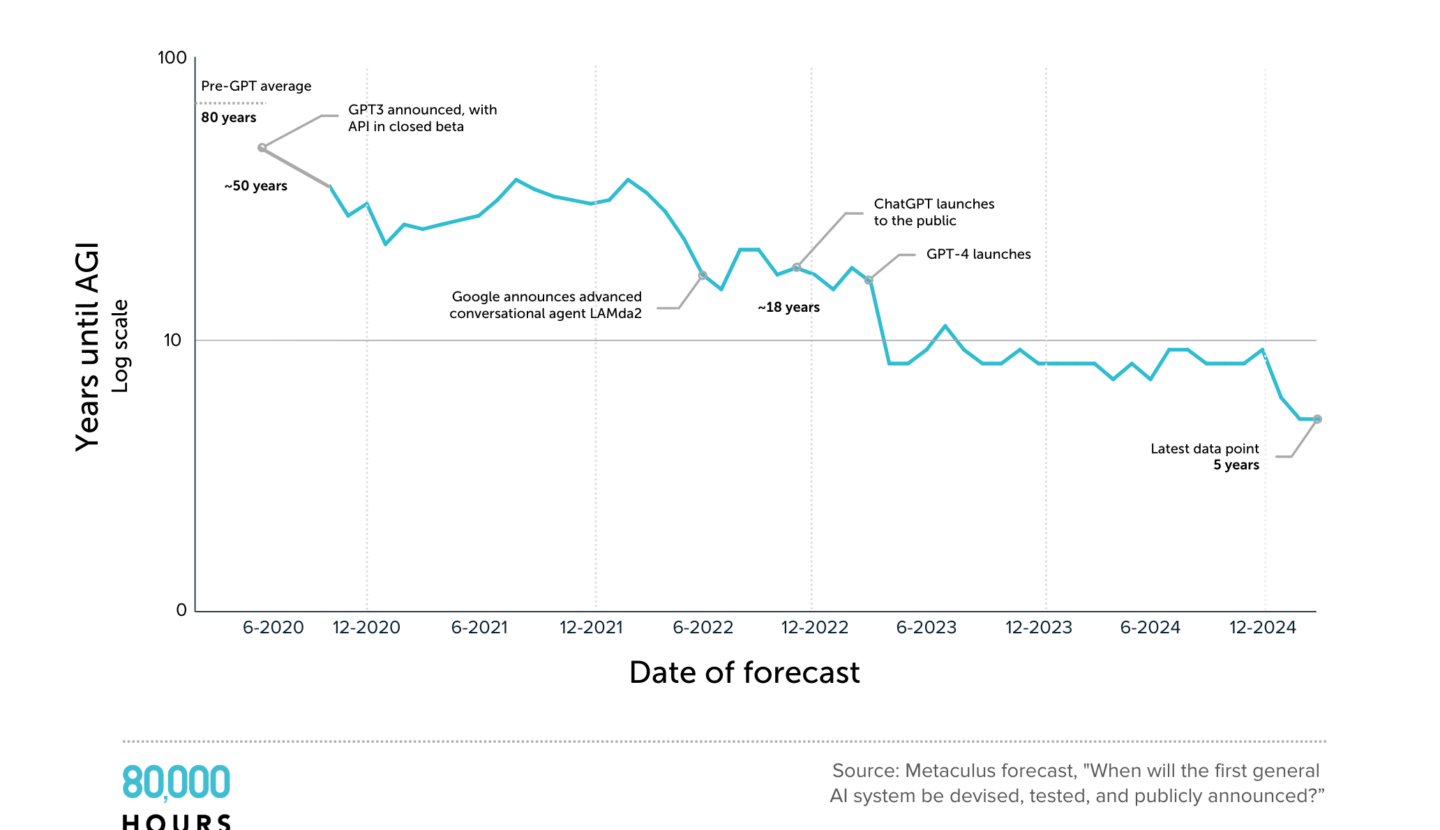
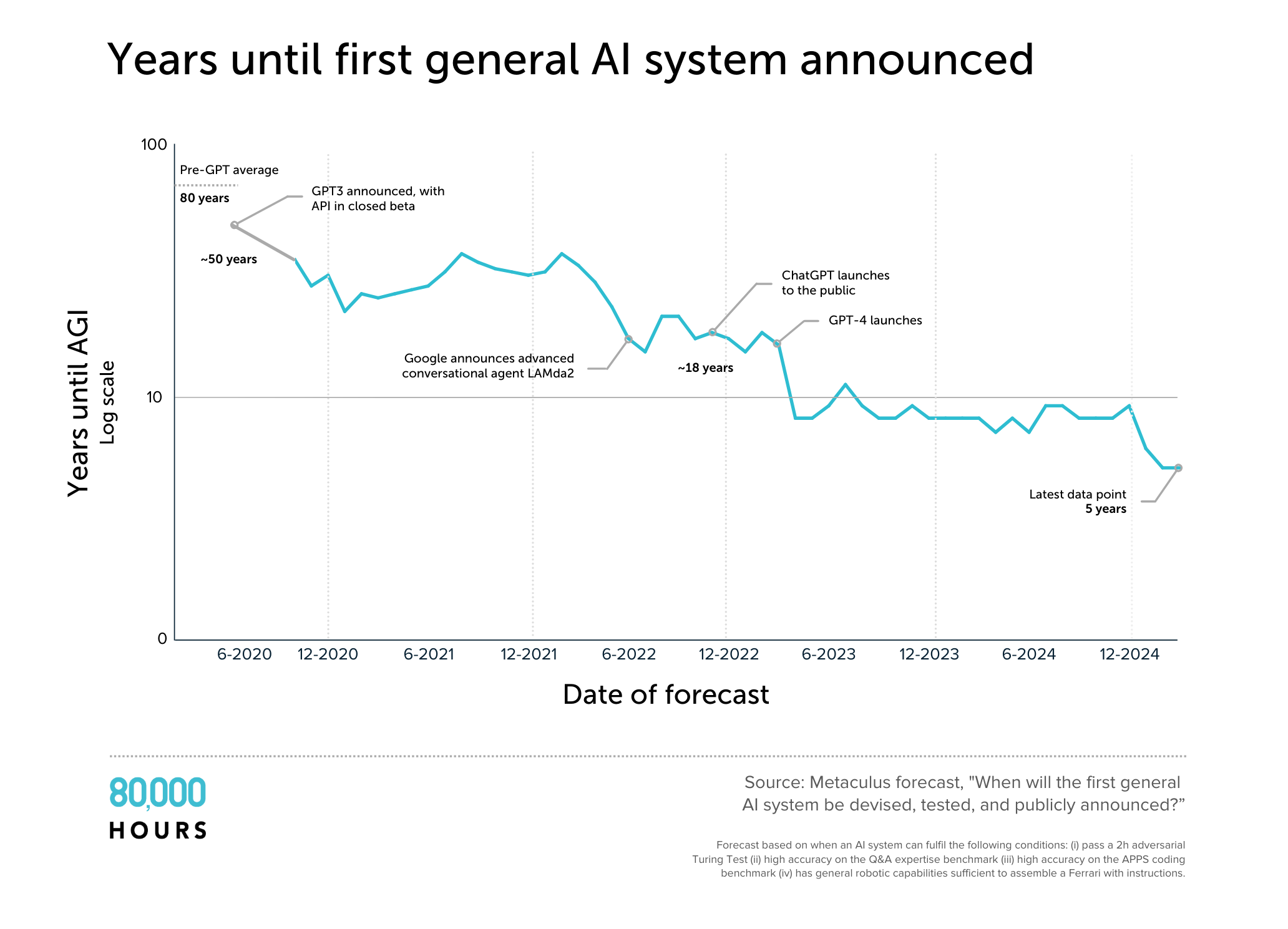
In four years, the mean estimate on Metaculus for when AGI will be developed has plummeted from 50 years to five years. There are problems with the definition used, but the graph reflects a broader pattern of declining estimates.
Problem profile by Stephen Clare · Last updated March 2025 · First published June 2023
Economic growth and technological progress have bolstered the arsenals of the world’s most powerful countries. That means the next war between them could be far worse than World War II, the deadliest conflict humanity has yet experienced.
Could such a war actually occur? We can’t rule out the possibility. Technical accidents or diplomatic misunderstandings could spark a conflict that quickly escalates. International tension could cause leaders to decide they’re better off fighting than negotiating. And rapidly advancing AI may change the way wars are fought and lead to dangerous geopolitical upheaval.
It seems hard to make progress on this problem. It’s also less neglected than some of the problems that we think are most pressing. There are certain issues, like making nuclear weapons or military artificial intelligence systems safer, which seem promising — although it may be more impactful to work directly on reducing risks from AI, bioweapons or nuclear weapons directly. You might also be able to reduce the chances of misunderstandings and miscalculations by developing expertise in one of the most important bilateral relationships (such as that between the United States and China).
Finally, by making conflict less likely, reducing competitive pressure, and improving international cooperation, you might be helping to reduce other risks, like the chance of future pandemics.
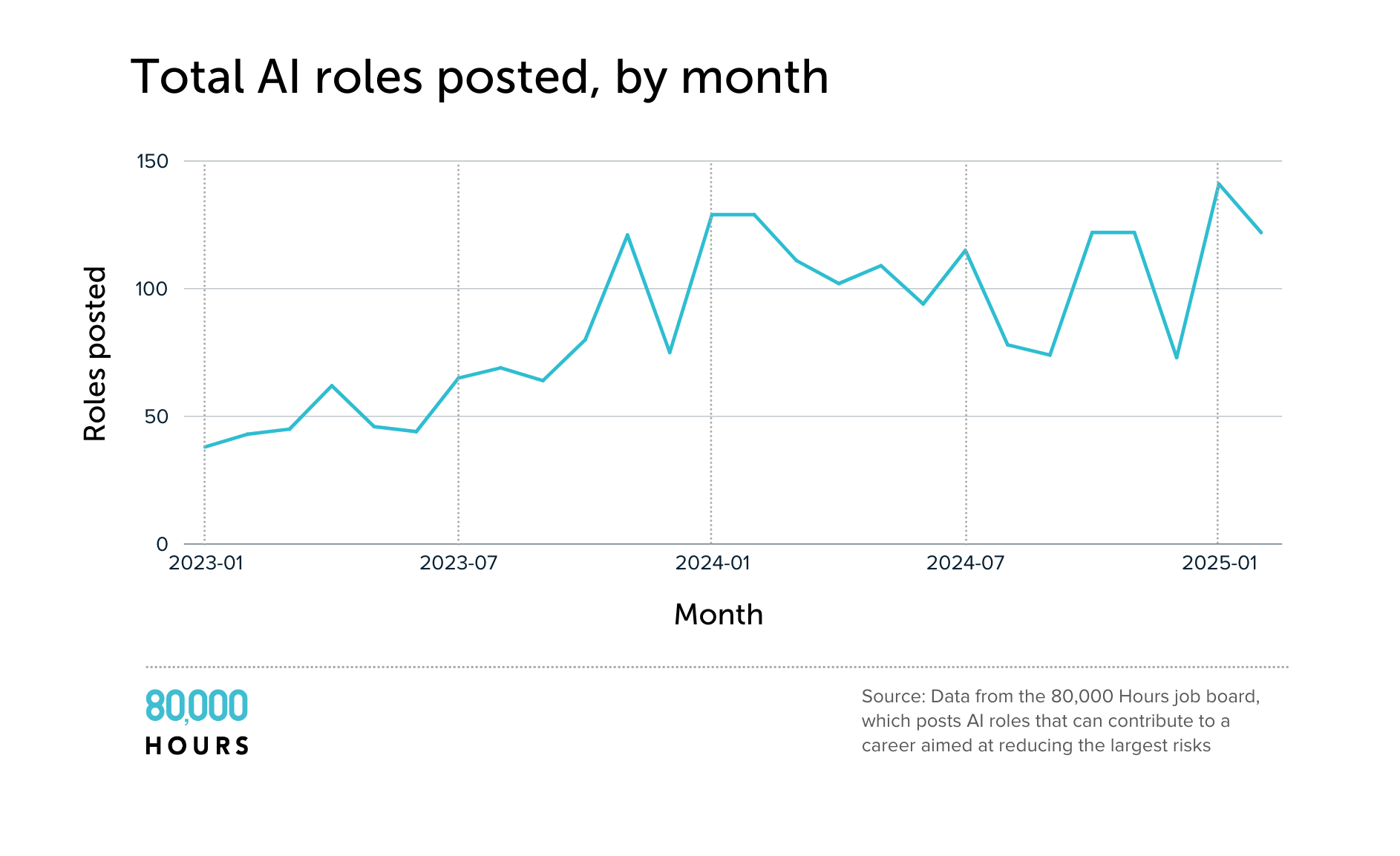
As AI has advanced rapidly and the risks have become more salient, we’ve seen many more jobs available to help mitigate the dangers.
The number of AI-related jobs we posted on our job board rose throughout 2023 and then plateaued in 2024. But in January 2025, we posted the most AI-relevant jobs yet!
In 2023, we posted an average of 63 AI-related roles per month. In 2024, the average rose to 105 — a 67% increase.
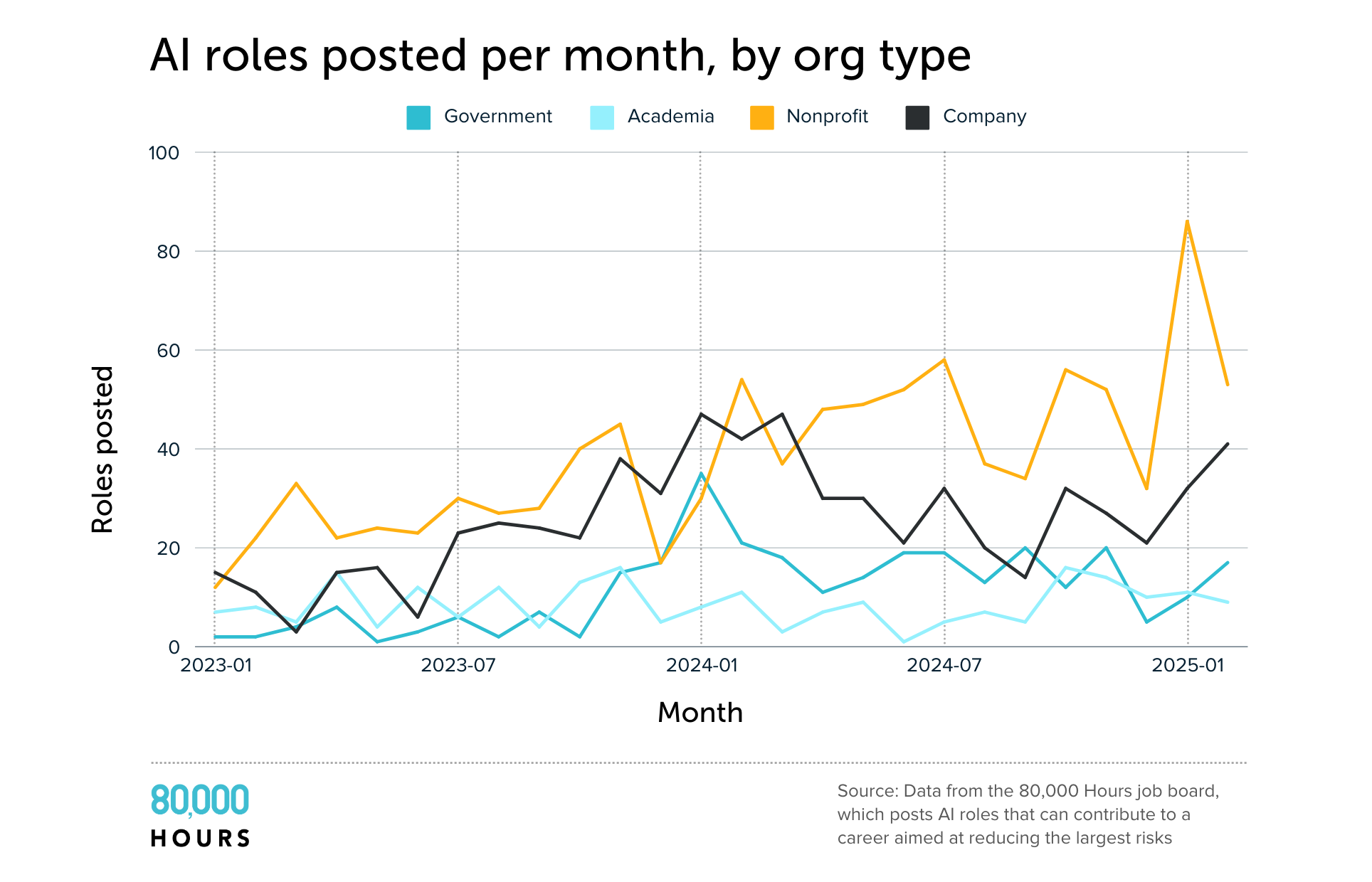
Over this time, nonprofit jobs have been the most common, though they were briefly overtaken by both company and government jobs in early 2024.
This trend could reflect our vantage point. As a nonprofit that works closely with other nonprofits, we may be best positioned to find and assess high-impact roles in this sector while potentially missing other great roles in sectors more opaque to us.
I’m writing a new guide to careers to help artificial general intelligence (AGI) go well. Here’s a summary of the bottom lines that’ll be in the guide as it stands. Stay tuned to hear our full reasoning and updates as our views evolve.
In short:
The chance of an AGI-driven technological explosion before 2030 — creating one of the most pivotal periods in history — is high enough to act on.
Since this transition poses major risks, and relatively few people are focused on navigating them, if you might be able to do something that helps, that’s likely the highest-impact thing you can do.
There are now many organisations with hundreds of jobs that could concretely help (many of which are non technical).
If you already have some experience (e.g. age 25+), typically the best path is to spend 20–200 hours reading about AI and meeting people in the field, then applying to jobs at organisations you’re aligned with — this both sets you up to have an impact relatively soon and advance in the field. If you can’t get a job right away, figure out the minimum additional skills, connections, and credentials you’d need, then get those.
If you’re at the start of your career (or need to reskill), you might be able to get an entry-level job or start a fellowship right away in order to learn rapidly. Otherwise, spend 1–3 years building whichever skill set listed below is the best fit for you.
Podcast by Robert Wiblin · Published March 11th, 2025
The 20th century saw unprecedented change: nuclear weapons, satellites, the rise and fall of communism, third-wave feminism, the internet, postmodernism, game theory, genetic engineering, the Big Bang theory, quantum mechanics, birth control, and more. Now imagine all of it compressed into just 10 years.
That’s the future Will MacAskill — philosopher, founding figure of effective altruism, and now researcher at the Forethought Centre for AI Strategy — argues we need to prepare for in his new paper “Preparing for the intelligence explosion.” Not in the distant future, but probably in three to seven years.
The reason: AI systems are rapidly approaching human-level capability in scientific research and intellectual tasks. Once AI exceeds human abilities in AI research itself, we’ll enter a recursive self-improvement cycle — creating wildly more capable systems. Soon after, by improving algorithms and manufacturing chips, we’ll deploy millions, then billions, then trillions of superhuman AI scientists working 24/7 without human limitations. These systems will collaborate across disciplines, build on each discovery instantly, and conduct experiments at unprecedented scale and speed — compressing a century of scientific progress into mere years.
Will compares the resulting situation to a mediaeval king suddenly needing to upgrade from bows and arrows to nuclear weapons to deal with an ideological threat from a country he’s never heard of, while simultaneously grappling with learning that he descended from monkeys and his god doesn’t exist.
What makes this acceleration perilous is that while technology can speed up almost arbitrarily, human institutions and decision-making are much more fixed.
Consider the case of nuclear weapons: in this compressed timeline, there would have been just a three-month gap between the Manhattan Project’s start and the Hiroshima bombing, and the Cuban Missile Crisis would have lasted just over a day.
Robert Kennedy, Sr., who helped navigate the actual Cuban Missile Crisis, once remarked that if they’d had to make decisions on a much more accelerated timeline — like 24 hours rather than 13 days — they would likely have taken much more aggressive, much riskier actions.
So there’s reason to worry about our own capacity to make wise choices. And in “Preparing for the intelligence explosion,” Will lays out 10 “grand challenges” we’ll need to quickly navigate to successfully avoid things going wrong during this period.
Will’s thinking has evolved a lot since his last appearance on the show. While he was previously sceptical about whether we live at a “hinge of history,” he now believes we’re entering one of the most critical periods for humanity ever — with decisions made in the next few years potentially determining outcomes millions of years into the future.
But Will also sees reasons for optimism. The very AI systems causing this acceleration could be deployed to help us navigate it — if we use them wisely. And while AI safety researchers rightly focus on preventing AI systems from going rogue, Will argues we should equally attend to ensuring the futures we deliberately build are truly worth living in.
In this wide-ranging conversation with host Rob Wiblin, Will maps out the challenges we’d face in this potential “intelligence explosion” future, and what we might do to prepare. They discuss:
Why leading AI safety researchers now think there’s dramatically less time before AI is transformative than they’d previously thought
The three different types of intelligence explosions that occur in order
Will’s list of resulting grand challenges — including destructive technologies, space governance, concentration of power, and digital rights
How to prevent ourselves from accidentally “locking in” mediocre futures for all eternity
Ways AI could radically improve human coordination and decision making
Why we should aim for truly flourishing futures, not just avoiding extinction
This episode was originally recorded on February 7, 2025.
Video editing: Simon Monsour Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Camera operator: Jeremy Chevillotte Transcriptions and web: Katy Moore
Podcast by Robert Wiblin · Published March 7th, 2025
When OpenAI announced plans to convert from nonprofit to for-profit control last October, it likely didn’t anticipate the legal labyrinth it now faces. A recent court order in Elon Musk’s lawsuit against the company suggests OpenAI’s restructuring faces serious legal threats, which will complicate its efforts to raise tens of billions in investment.
As nonprofit legal expert Rose Chan Loui explains, the court order set up multiple pathways for OpenAI’s conversion to be challenged. Though Judge Yvonne Gonzalez Rogers denied Musk’s request to block the conversion before a trial, she expedited proceedings to the fall so the case could be heard before it’s likely to go ahead. (See Rob’s brief summary of developments in the case.)
And if Musk’s donations to OpenAI are enough to give him the right to bring a case, Rogers sounded very sympathetic to his objections to the OpenAI foundation selling the company, benefiting the founders who forswore “any intent to use OpenAI as a vehicle to enrich themselves.”
But that’s just one of multiple threats. The attorneys general (AGs) in California and Delaware both have standing to object to the conversion on the grounds that it is contrary to the foundation’s charitable purpose and therefore wrongs the public — which was promised all the charitable assets would be used to develop AI that benefits all of humanity, not to win a commercial race. Some, including Rose, suspect the court order was written as a signal to those AGs to take action.
And, as she explains, if the AGs remain silent, the court itself, seeing that the public interest isn’t being represented, could appoint a “special interest party” to take on the case in their place.
This places the OpenAI foundation board in a bind: proceeding with the restructuring despite this legal cloud could expose them to the risk of being sued for a gross breach of their fiduciary duty to the public. The board is made up of respectable people who didn’t sign up for that.
And of course it would cause chaos for the company if all of OpenAI’s fundraising and governance plans were brought to a screeching halt by a federal court judgment landing at the eleventh hour.
Host Rob Wiblin and Rose Chan Loui discuss all of the above as well as what justification the OpenAI foundation could offer for giving up control of the company despite its charitable purpose, and how the board might adjust their plans to make the for-profit switch more legally palatable.
This episode was originally recorded on March 6, 2025.
Video editing: Simon Monsour Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Transcriptions: Katy Moore
Laura: This is a difficult question, but I think it’s important to ask. I certainly don’t have all the answers, because the future is uncertain — perhaps especially now.
That said, I do think there are sensible steps to take to navigate the trajectory of AI and its global impact
First, let’s address the immediate concern about the job market. While AI is already changing the landscape of work, entry-level jobs haven’t disappeared. The 80,000 Hours job board has hundreds of entry-level openings, and other job sites will have many more. I expect there will still be plenty of jobs available when you graduate, even as AI continues to advance quickly.
As technology becomes better at the tasks that human workers perform, there are typically significant delays before it is widely adopted. Still, the economy will likely change as AI gets more powerful, and that may start happening in just a few years. So, my advice is to stay ahead of the adoption curve. Master prompting and evaluation techniques to ensure the quality of outputs. Learn to set up AI task automation systems. Experiment with new tools and applications.
Blog post by Arden Koehler · Published February 19th, 2025
About 80,000 Hours
80,000 Hours’ mission is to get talented people working on the world’s most pressing problems.
In 2025, we are planning to focus especially on helping explain why and how our audience can help society safely navigate a transition to a world with transformative AI.
Over a million people visit our website each year, and thousands of people have told us that they’ve significantly changed their career plans due to our work. Surveys conducted by our primary funder, Open Philanthropy, show that 80,000 Hours is the biggest single driver of talent moving into work related to reducing global catastrophic risks. And due to its wide reach, the web programme is among its most cost-effective programmes.
Our most popular pieces get over 10,000 unique visitors each month, and are among the most important ways we help people shift their careers towards higher-impact options.
The role
In this role, you would:
Research and write new articles, e.g. articles explaining particular issues within AI risk reduction for a popular audience (e.g. an explainer on catastrophic misuse, or government abuse of AI technology)
Survey and interview experts in the issues we prioritise to inform our career advice
Update or rewrite core articles with new information and resources or to appeal to new audiences
Write substantive newsletters for an audience of over 500,000 people
Continually learn from analytics, article performance on social media, and user feedback what kinds of framings are most clear and engaging
Manage and edit external expert contributors to write articles
This week, we’re answering our newsletter subscribers’ career questions.
Question one: I’ve been working over 20 years as a software engineer, and participated in a few publications as a research engineer. I’m open to getting deeper into research, in fact I’m starting a PhD in computer science. I’m close to 50, but most of the career advice I see from 80,000 Hours seems focused on younger folk.
I’m wondering about reorienting towards global issues; does it make sense to continue with my current PhD? Drop it for one directly related to (e.g.) AI? Drop the PhD and just apply as a research engineer to appropriate companies with such engineers? Or just leave it to the next generation?
Sudhanshu: I would pretty much never say “leave it to others” — there might not be many others, and experienced folks like you often have a lot to offer. We are always hearing from impactful organisations all the time who want experienced, mid-career people to join them in key roles.
With 20 years as a software engineer, I’d be excited if you could apply that experience directly to a pressing world problem, unless you’ve gotten some evidence to suggest that you need some new skills. I think it makes sense to try your hand at just working directly on the problem you think is most important before moving on to other options.
If you do think working on reducing AI risk is the most important problem,
Podcast by Robert Wiblin · Published February 14th, 2025
Technology doesn’t force us to do anything — it merely opens doors. But military and economic competition pushes us through.
That’s how today’s guest Allan Dafoe — director of frontier safety and governance at Google DeepMind — explains one of the deepest patterns in technological history: once a powerful new capability becomes available, societies that adopt it tend to outcompete those that don’t. Those who resist too much can find themselves taken over or rendered irrelevant.
This dynamic played out dramatically in 1853 when US Commodore Perry sailed into Tokyo Bay with steam-powered warships that seemed magical to the Japanese, who had spent centuries deliberately limiting their technological development. With far greater military power, the US was able to force Japan to open itself to trade. Within 15 years, Japan had undergone the Meiji Restoration and transformed itself in a desperate scramble to catch up.
Today we see hints of similar pressure around artificial intelligence. Even companies, countries, and researchers deeply concerned about where AI could take us feel compelled to push ahead — worried that if they don’t, less careful actors will develop transformative AI capabilities at around the same time anyway.
But Allan argues this technological determinism isn’t absolute. While broad patterns may be inevitable, history shows we do have some ability to steer how technologies are developed, by who, and what they’re used for first.
As part of that approach, Allan has been promoting efforts to make AI more capable of sophisticated cooperation, and improving the tests Google uses to measure how well its models could do things like mislead people, hack and take control of their own servers, or spread autonomously in the wild.
As of mid-2024 they didn’t seem dangerous at all, but we’ve learned that our ability to measure these capabilities is good, but imperfect. If we don’t find the right way to ‘elicit’ an ability we can miss that it’s there.
Subsequent research from Anthropic and Redwood Research suggests there’s even a risk that future models may play dumb to avoid their goals being altered.
That has led DeepMind to a “defence in depth” approach: carefully staged deployment starting with internal testing, then trusted external testers, then limited release, then watching how models are used in the real world. By not releasing model weights, DeepMind is able to back up and add additional safeguards if experience shows they’re necessary.
But with much more powerful and general models on the way, individual company policies won’t be sufficient by themselves. Drawing on his academic research into how societies handle transformative technologies, Allan argues we need coordinated international governance that balances safety with our desire to get the massive potential benefits of AI in areas like healthcare and education as quickly as possible.
Host Rob and Allan also cover:
The most exciting beneficial applications of AI
Whether and how we can influence the development of technology
What DeepMind is doing to evaluate and mitigate risks from frontier AI systems
Why cooperative AI may be as important as aligned AI
The role of democratic input in AI governance
What kinds of experts are most needed in AI safety and governance
And much more
Video editing: Simon Monsour Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Camera operator: Jeremy Chevillotte Transcriptions: Katy Moore
Podcast by Robert Wiblin · Published February 12th, 2025
On Monday, February 10, Elon Musk made the OpenAI nonprofit foundation an offer they want to refuse, but might have trouble doing so: $97.4 billion for its stake in the for-profit company, plus the freedom to stick with its current charitable mission.
For a normal company takeover bid, this would already be spicy. But OpenAI’s unique structure — a nonprofit foundation controlling a for-profit corporation — turns the gambit into an audacious attack on the plan OpenAI announced in December to free itself from nonprofit oversight.
As today’s guest Rose Chan Loui — founding executive director of UCLA Law’s Lowell Milken Center for Philanthropy and Nonprofits — explains, OpenAI’s nonprofit board now faces a challenging choice.
The nonprofit has a legal duty to pursue its charitable mission of ensuring that AI benefits all of humanity to the best of its ability. And if Musk’s bid would better accomplish that mission than the for-profit’s proposal — that the nonprofit give up control of the company and change its charitable purpose to the vague and barely related “pursue charitable initiatives in sectors such as health care, education, and science” — then it’s not clear the California or Delaware Attorneys General will, or should, approve the deal.
OpenAI CEO Sam Altman quickly tweeted “no thank you” — but that was probably a legal slipup, as he’s not meant to be involved in such a decision, which has to be made by the nonprofit board ‘at arm’s length’ from the for-profit company Sam himself runs.
The board could raise any number of objections: maybe Musk doesn’t have the money, or the purchase would be blocked on antitrust grounds, seeing as Musk owns another AI company (xAI), or Musk might insist on incompetent board appointments that would interfere with the nonprofit foundation pursuing any goal.
But as Rose and Rob lay out, it’s not clear any of those things is actually true.
In this emergency podcast recorded soon after Elon’s offer, Rose and Rob also cover:
Why OpenAI wants to change its charitable purpose and whether that’s legally permissible
On what basis the attorneys general will decide OpenAI’s fate
The challenges in valuing the nonprofit’s “priceless” position of control
Whether Musk’s offer will force OpenAI to up their own bid, and whether they could raise the money
If other tech giants might now jump in with competing offers
How politics could influence the attorneys general reviewing the deal
What Rose thinks should actually happen to protect the public interest
Video editing: Simon Monsour Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong Transcriptions: Katy Moore