

How to use your career to reduce risks from AI
We’ll catch you up on the risks and help you address them
AI that is more capable than humans could lead to explosive technological change and make the next decade among the most pivotal in history.
But it also poses huge — even existential — risks, and as a society, we’re not ready.
We urgently need lots of people with diverse skills and experiences to help reduce these risks.
You can shift your career to help tackle this problem — we’ve already helped over 1,000 people do it.






AI progress is fast — and could get even faster
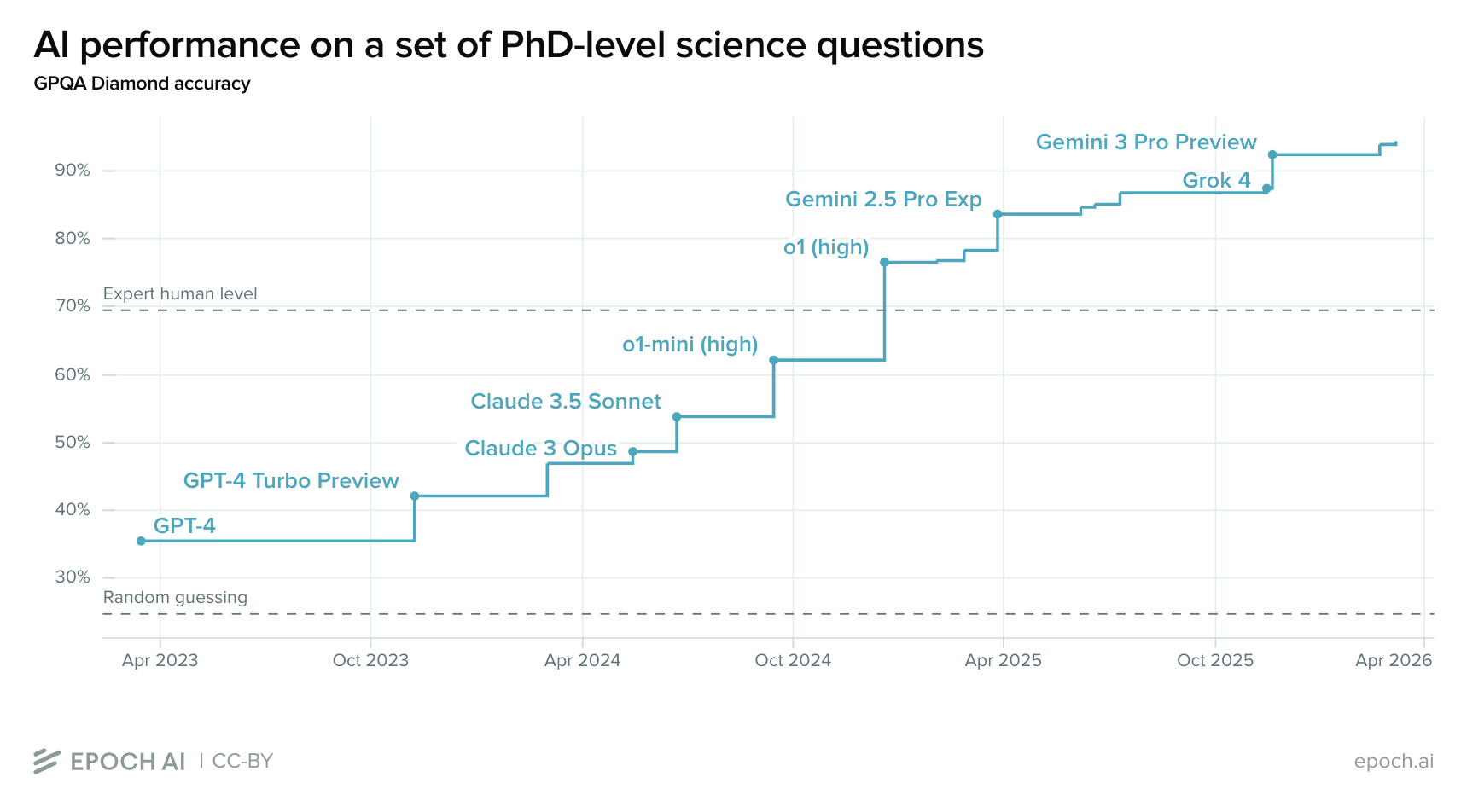
Companies are trying to build AI that outperforms humans at most tasks — also known as artificial general intelligence (AGI). Trends suggest they might succeed within the next decade.
AI is now being used to build even better AI. If this creates a feedback loop that accelerates progress, we could see an intelligence explosion — giving us AGI with only a few months’ warning.
And the world after AGI – with billions of superhuman minds operating at superhuman speeds – could be extremely dangerous.
Companies are trying to build AI that outperforms humans at most tasks — also known as artificial general intelligence (AGI). Trends suggest they might succeed within the next decade.
AI is now being used to build even better AI. If this creates a feedback loop that accelerates progress, we could see an intelligence explosion — giving us AGI with only a few months’ warning.
And the world after AGI – with billions of superhuman minds operating at superhuman speeds – could be extremely dangerous.
AI could bring huge benefits, but poses incredibly serious risks
If things go well, advanced AI could lead to unprecedented growth and innovation. But if things go badly, it could be disastrous.
The worst problems could be existential — causing a catastrophic pandemic, a permanently worse trajectory for humanity, or even extinction.

Power-seeking AI systems
Power-seeking AI systems

Extreme power concentration
Engineered pandemics

Moral status of digital minds

Gradual disempowerment

Catastrophic AI misuse

AI-enhanced decision making
In-depth interviews about the impacts AI will have on the world






Our best resources for working on AI risks
Career reviews

Improve organisational, political, and societal decision-making about AI to reduce catastrophic risks.

The development of AI could transform society. Help increase the chance it’s positive by doing technical research to find ways to prevent AI systems from carrying out dangerous behaviour.

Help secure important organisations from attacks and prevent emerging technologies like AI and biotech from being misused, stolen, or tampered with.

Win elected office to shape policy across many of the world’s most pressing problems.

Help Chinese companies and stakeholders involved in building AI make the technology safe and good for society.

Identify a gap in solving a pressing problem, then build an organisation to fill it.

Help organisations tackling critical problems run effectively by improving systems, logistics, and decision-making.

Use writing, speaking, or media to spread important ideas, influence decisions, and help more people work on pressing global problems.
Job board
We curate job listings to help you work on pressing world problems, including helping advanced AI go well. On our board, you’ll find:
Free 1-1 career support
Our career advisors can help you figure out how best to contribute.
We can:
- Review your thinking
- Suggest opportunities that match your background
- Introduce you to people in the field
We’re most helpful for people who want an analytical and ambitious approach to impact. If in doubt, apply.


I was introduced to some experts in the field and others who were interested in following a similar path. These introductions have played a big part in me obtaining an internship at MILA. 80,000 Hours also helped me to be awarded an EA grant for pursuing research related to AI safety.
Dr Zac KentonResearch ScientistDeepMind


The advising team is incredibly well-researched and connected in AI safety. Their advice is far more insightful, personalized, and impact-focused than most of what I got from Google, self-reflection, or the peers or mentors I would typically go to.
Ethan PerezResearch ScientistAnthropic


As a direct result of advising, I found a role as Assistant Director of the Center for Human-Compatible AI at UC Berkeley, where I began contributing to shaping provably beneficial AI.
Rosie CampbellManaging DirectorEleos AI


What if you need to skill up?







Stay up to date
Join the 80,000 Hours Newsletter
We’ll send you updates on AI developments and risks — including our latest research, job openings, and practical advice on how to contribute.
Subscribe to our podcast









More recommended podcasts



More recommended newsletters
FAQs
There is a lot of exaggeration and hype about AI out there, and it’s good to be skeptical of extreme claims about a new technology — they often turn out to be wrong or even scams.
But the progress we’ve seen in AI over the last few years is undoubtedly real, even if some people claim AI can do things it can’t yet. The technology is moving fast, and the AI capabilities now on display would astound people working in the field five years ago. We’ve documented some of the impressive progress here and here, and explored whether it might continue here.
It’s important to keep three things in mind:
- AI has made incredible progress.
- Current AI systems still have many flaws and limitations.
- Future AI systems will likely be much, much better.
We think people often focus too much on either (1) or (2) without acknowledging the other. And not nearly enough people are focused on (3) — and what it might mean for the future of civilisation.
Unfortunately, we think so.
Over the past 10 years, we’ve investigated many candidate existential risks — meaning disasters that could result in outcomes as bad as human extinction, or worse — because we think these risks are worth prioritising. Only a few candidates wound up looking truly existential — but AI was one of them. Because the technology could become enormously powerful and agentic, it’s like creating a new, smarter-than-us species we can’t control and hoping it treats us well forever. We think it poses a greater risk than anything else we’ve seen.
We’re not alone in being concerned. Top scientists, AI business leaders, and some politicians have also warned that the creation of powerful AI could lead to existential risks.
This view is still controversial, though. Some people who have seriously examined the question of whether AI poses an existential risk have come away unconvinced. So we’re not completely certain.
But we don’t need certainty: if there’s a meaningful chance that a technology could pose an existential risk, then it’s worth a lot of effort to reduce that. In this case, we think the risks are high enough that they demand much more attention than they have received.
For (much) more on this question, see our article on the risk of an AI-related catastrophe.
A lot, and more all the time.
Our top recommendations for staying up to date on what AI can do already are:
- The AI Digest, for interactive demos and explainers on AI’s new capabilities
- AI Explained, a YouTube channel and podcast cover new AI developments and industry updates
- One Useful Thing, a blog by professor Ethan Mollick that tracks and analyses AI progress.
- Don’t Worry About the Vase, a blog by Zvi Mowshowitz that provides extensive summaries of recent AI news.
Also, if you spend more time working with AI, you’ll understand the technology at a more visceral level. See our guide to using AI at work and in life to get more done.
There are a number of great organisations working on this issue from a variety of angles, which means many skill sets are valuable.
This includes organisations working on AI policy and governance, like the Center for AI Safety, the nonprofit that wrote the Statement on AI Risk letter. They’ve hired for policy experts, writers, research engineers, and operations staff like finance managers and development officers.
Other organisations work on technical AI safety, like Model Evaluation and Threat Research, a team that evaluates the capabilities and alignment of advanced AI models. They’ve hired for software engineers, researchers, and operations staff like recruiters and administrators.
Some organisations work indirectly on the issue, like Blueprint Biosecurity, which works to achieve breakthroughs in humanity’s capacity to prevent, mitigate, and suppress pandemics. One potential method of attack for future terrorists or misaligned AI is engineered pandemics, so work in this area is quite valuable. They’ve hired for researchers and policy analysts, as well as communication and administrative roles.
Finally, there are organisations working on growing the field, like BlueDot Impact (and us!). BlueDot Impact runs courses which aim to help participants develop the knowledge, community, and network needed to pursue high-impact careers. They’ve hired for teaching fellows, program managers, software engineers, operations specialists, and more.
You can see a list of organisations that offer especially promising roles on our job board here.
We think some of the best arguments for thinking that AGI won’t come soon are:
- The path to AGI is not obvious. Today’s AI systems excel at many things (chess, image recognition, coding, etc.) but still can’t carry out complex plans over hours or days, interact flexibly with the physical world, or consistently learn from past experience. While scaling has improved AI performance on well-defined tasks, it might not help them grapple with messier real-world problems. Some researchers think we’re missing the crucial insights we need to create truly general and broadly useful AIs — and these might take many years to discover.
- We might soon hit major bottlenecks on AI development or face diminishing returns from algorithmic improvements, both of which would seriously stall progress. And world events, like a great power war, could make us hit a bottleneck even sooner.
- Most of the world is not acting like a radically transformative technology is just around the corner — markets don’t seem to be predicting huge economic effects, and governments aren’t scrambling to redesign institutions. The idea is even highly controversial among people working on AI. When your model of the future is out of sync with what most of the world is doing, it’s worth asking why.
We’ve explained these objections in more detail here.
Importantly, even if we do develop AGI fairly soon, society may adopt it slowly — making the technology’s impact more gradual. Indeed, we’re very likely to see some resistance to adoption. Our view is that whatever sectors are slow to adopt will be quickly outcompeted, and that even a few crucial sectors using the technology could be enough for transformative effects. But if adoption is slow across the board, things could unfold more gradually.
To learn more about the case for slower AI progress, the best resources we know of are this podcast where technical AI safety researchers argue that AGI is still 30 years away, and this report on multi-decade timelines from one of the podcast guests.
We think the best arguments against the idea that advanced AI poses significant existential risks are:
- We don’t understand the nature of AI goals and motivations. It’s possible that AI systems will be easy to steer by default, and be unlikely to develop power-seeking or dishonest tendencies, which would reduce several of the risks we’re most worried about (though not all).
- If development is slow and gradual, advances in AI are more likely to be closely monitored, and safety researchers may be able to head off any issues. So if you think AI progress will be relatively slow (see above), you will probably be less worried.
- In general, AI systems will be designed by humans, and humans have strong incentives to ensure that AI systems are safe and aligned with human values.
- Multiple powerful AI systems could be deployed by different actors, and could act as “checks and balances” on one another.
- Many other concerns about new technology and catastrophic risks have been unfounded or exaggerated — or the problems have been solved relatively easily — so we might expect something similar to play out with AI.
- ‘Existentially risky’ is an extremely high bar. We should start by assuming that issues created by advanced AI will be more moderate, and only change our minds based on strong arguments or evidence.
We think there are strong arguments for being highly concerned — see our article on why we think AI poses existential risks. But these questions are hard, and it’s not so obvious that reasonable people can’t disagree.
Absorbing the information, podcasts, and newsletters on this page is a good place to start. For more on why AI could be such a big deal, you can read our problem profile on AI risks.
We also have a reading list for other blog posts and research papers we recommend.
Those sources will link to other resources, and we’d encourage you to explore them for as long as they hold your interest.
Some of the best ways to do this are:
- Attending conferences such as Effective Altruism Global or NeurIPS
- Taking part in an online programme, like the ones run by BlueDot Impact
- Visiting a research centre focused on AI risk, like Constellation in Berkeley or LISA in London.
- Joining relevant conversations on the Effective Altruism Forum, the AI Alignment Slack, or X/Twitter
- Talking to our 1-1 advisors who can sometimes introduce you to experts, local networks, or potential future colleagues based on your specific situation
You can find more options and advice on our community page.
Maybe — it depends on what you do, whether you’re able to adapt, and how AI develops.
In the short run, automation doesn’t always decrease employment, even in jobs that are very close to the work being automated. For example, automation of bank staff via ATMs actually increased employment of bank clerks in the short term: it was profitable to open more bank branches where bank clerks specialised in talking to clients instead of counting cash. However, when people started to do their banking online instead of going in person, employment of bank clerks cratered.
Similarly, in the short run, AI automation will likely increase demand for skills that are harder to automate, such as good judgment, leadership, and doing tasks in the physical world. AI automation would also increase demand for skills that we need to scale up AI use — including the ability to use AIs well yourself.
n the long run, however, AIs and robots might be able to do every job humans can do – though at that point, we’d expect the world to be so radically different that unemployment may not be your biggest problem.
We can’t know for certain which jobs will be automated first and which will survive longer. You should prepare to “ride the wave” of automation: build flexibility, adapt your skills to be complementary with AI, and keep up with the latest advancements and how to use them. That way you can change the nature of your work quickly as AI automation progresses.
The environmental impacts of AI are indeed serious. The International Energy Agency projects data centre electricity consumption — significantly driven by AI workloads — could reach 3% of global electricity demand by 2030, with associated water usage and CO2 emissions comparable to mid-sized countries. And there are other concerns too, like habitat disruption from expanding data centre facilities.
Nonetheless, we don’t think environmental impacts are among the biggest concerns arising from advanced AI.
- The key reason, which we think is underappreciated by most of society, is that advanced AI could lead to problems that are even more serious — such as power-seeking, deception, and potentially takeover by extremely powerful AI systems, or the ability for humans to use powerful AI systems to take over legitimate institutions in an AI-assisted coup. We think these issues — and maybe others — have the potential to affect everyone alive today, plus all future generations.
- On the other hand, we don’t think climate change poses an existential risk on its own. Even considering AI’s accelerating energy demands, we’d guess that there’s less than a 1 in 1,000,000 chance of temperature changes severe enough to cause human extinction, and we don’t see a path to permanent human disempowerment from climate change.
- Climate change does seem like a risk factor for some of these even more severe impacts — e.g. because it increases conflict between nations, which can lead to the development or use of new AI-enabled destructive technologies. For this reason, as well as the direct impacts, we support efforts to reign in rising temperatures and their impacts.
- Environmental impacts from AI are relatively visible and measurable. Major tech companies routinely track and report environmental footprints. And there are some established pathways for improvement: renewable energy adoption, advanced cooling systems, and energy-efficient hardware. Hundreds of billions of dollars go toward combating climate change each year. In contrast, risks from misuse or loss of control of powerful AI systems have many, many fewer people and resources dedicated to them and lack public awareness. This relative neglect is a large reason why we’re focused on helping people work on these issues.
- AI itself could be part of the solution for climate change. AI systems can optimise energy usage in data centres, improve grid efficiency, greatly accelerate clean energy research, and help design more efficient hardware — if we handle them well. So if we can avoid the risks and capture the upsides of advanced AI, we may be able to use it to address climate change and other environmental problems.
If you’ve got specialised skills (or experience), there are many organisations that could be excited to hire you.
In fact, many projects are bottlenecked on more experienced talent — people who can lead teams or bring years of experience in an area that’s particularly hard for generalists, like scientific disciplines or law.
You can filter our job board for different skills and seniority, as well as for organisations working on AI. The job board also allows you to set up email alerts for jobs matching specific criteria.
In general, we know employers in the AI risk field are interested in people with the following skills:
- Policy and political skills (especially concerning AI but also other areas, e.g. China-US relations). These skills allow you to work in government, think tanks, or politics.
- ML engineering for technical safety research
- Information and cybersecurity, to safeguard powerful AI technology from cyberthreats and theft
- Entrepreneurship
- Organisation building, e.g. to do general ‘getting stuff done’ work
- Communications and community building
- Research in any area that might be relevant, including social sciences, international relations, history, and even philosophy, as well as AI itself
- Forecasting
- AI hardware expertise
Other skills might also be relevant, even if it’s not obvious at first how or they’re too niche for us to cover here.
Getting to know more people in the field might help you better figure out where you can contribute. So go to conferences, meet-ups, lectures, and other events with people who are also working on AI risks to expand your network. (You can get alerted to upcoming events by joining our newsletter.)
It’s also possible you’ll need to learn new skills or get new experience. The good news is that you may be able to get up to speed relatively quickly, because AI risk is a young field. For ways to skill up, see our section above.
You can also apply to speak to one of our 1-1 advisors, who can help put you in touch with potential collaborators or employers.
Even if you’re at the start of your career, you might be able to get an entry-level position or fellowship right away. So it can be worth doing a round of applications immediately, especially if you have technical skills.
You can try the following steps:
- Spend 20–200 hours learning about AI, speaking to people in the field, and perhaps doing short projects.
- Apply to impactful organisations that might be able to use your help. Check out our job board for opportunities.
- Aim for the job with the best combination of (i) strong org mission, (ii) team quality, (iii) centrality to the ecosystem, (iv) influence of the role, and (v) personal fit.
However, in most cases, early-career people will need to spend 1–3 years gaining relevant skills before they should focus on how to apply them.
The skills listed above seem most helpful for working on this issue. Focus on whichever you expect to most excel at.
Also: don’t forget general skills like project management and personal productivity. You might want to check out the chapter of our career guide on how to be successful.
If you want to help reduce catastrophic risks from AI, we think working at a frontier AI company is an important option to consider — but the impact is extremely varied and sometimes negative. These roles often come with great potential for career growth, and by placing you right in the centre of AI development, some could provide (or later lead to) highly impactful opportunities for reducing the chances of an AI-related catastrophe.
However, there’s also a risk of doing a lot of harm, and there are particular roles you should probably avoid.
For much more on this question, check out our full article.
No, not everyone should do that. There are reasons not to work on this issue:
- You might not have the flexibility to make a large career change right now.
- There are other important problems, and you might be far better suited for a job focused on another issue. Personal fit is very important both for enjoying your job and having an impact.
- You might be too concerned about the (definitely huge) uncertainties about how best to help or be less convinced by the arguments that risks from AI are particularly pressing. For example, perhaps you are moved by some of the arguments here.
However, we think most people reading this should seriously consider dropping what they’re doing to work on helping advanced AI go well. The issue is very neglected, important, and urgent, and many people can contribute. So we think it will be a lot of our audience’s best option.
Successif and High Impact Professionals are two programmes specifically focused on helping mid-career people transition into careers focused on reducing risks from AI.
Or you can apply for courses or bootcamps, technical internships, or fellowships.
Finally, our 1-1 advisors may be able to connect you with more bespoke opportunities.
If you just don’t want to immediately change jobs or aren’t sure what you can do, you could try to get involved with the AI safety community, ask people for advice on how best to position yourself for the next 3–12 months — and then do that. You could also read our advice for early-career people above, or our thoughts on skilling up.
Otherwise, we recommend that you educate yourself more about AI and follow along with ongoing developments. That will help you figure out how to best contribute from your current path, for example, by donating, promoting clear thinking about the issue, mobilising others, or preparing to switch when new opportunities do become available.