

Preventing an AI-related catastrophe
AI might bring huge benefits — if we avoid the risks

Why is it that humans, and not chimpanzees, control the fate of the world?
Humans have shaped every corner of our planet. Chimps, despite being pretty smart compared to other nonhuman animals, have not.
This is (roughly) because of humans’ intelligence.1
Companies and governments are spending billions of dollars a year developing AI systems — and as these systems grow more advanced, they could (eventually) displace humans as the most intelligent things on the planet. As we’ll see, they’re making progress. Fast.
Exactly how long it will take to produce artificial intelligence that’s better than humans at most things is a matter of lively debate. But it looks likely that it is possible, and our guess is that it’ll happen this century.
The observation that human intelligence may be surpassed this century isn’t a rigorous or conclusive argument that artificial intelligence will be a big deal, or that it’s a threat to humanity. We’ll go into those arguments in far more detail below.
But it does seem fair to say that the potential development of rival intelligence on Earth in the near future should at least be cause for concern.
Will the systems we develop have goals? If so, what goals will they have?
Will they support humanity’s attempts to do good? Or might we lose our control over our future, and effectively end the human story here?
The honest answer to these questions is that we don’t know.
But we shouldn’t just wait around, fingers crossed, watching from afar. Artificial intelligence could fundamentally change everything — so working to shape its progress could just be the most important thing we can do.
Summary
We expect there will be substantial progress in AI in the coming years, potentially even to the point where machines come to outperform humans in many, if not all, tasks. This could have enormous benefits, helping to solve currently intractable global problems, but could also pose severe risks. These risks could arise accidentally (for example, if we don’t find technical solutions to concerns about the safety of AI systems), or deliberately (for example, if AI systems worsen geopolitical conflict). We think more work needs to be done to reduce these risks.
Some of these risks from advanced AI could be existential — meaning they could cause human extinction, or an equally permanent and severe disempowerment of humanity.2 There have not yet been any satisfying answers to concerns — discussed below — about how this rapidly approaching, transformative technology can be safely developed and integrated into our society. Finding answers to these concerns is neglected and may well be tractable. We estimated that there were around 400 people worldwide working directly on this in 2022, though we believe that number has grown.3 As a result, the possibility of AI-related catastrophe may be the world’s most pressing problem — and the best thing to work on for those who are well-placed to contribute.
Promising options for working on this problem include technical research on how to create safe AI systems, strategy research into the particular risks AI might pose, and policy research into ways in which companies and governments could mitigate these risks. As policy approaches continue to be developed and refined, we need people to put them in place and implement them. There are also many opportunities to have a big impact in a variety of complementary roles, such as operations management, journalism, earning to give, and more — some of which we list below.
Our overall view
Recommended - highest priority
We think this is among the most pressing problems in the world.
Scale
AI will have a variety of impacts and has the potential to do a huge amount of good. But we’re particularly concerned about the possibility of extremely bad outcomes, especially an existential catastrophe. Some experts on AI risk think that the odds of this are as low as 0.5%, some think that it’s higher than 50%. We’re open to either being right — and you can see further discussion of this here. My overall guess is that the risk of an existential catastrophe caused by artificial intelligence by 2100 is around 1%, perhaps stretching into the low single digits. This puts me on the less worried end of 80,000 Hours staff: as an organisation, our take is that the risk is somewhere between 3% and 50%.
Neglectedness
Around $50 million was spent on reducing catastrophic risks from AI in 2020 — while billions were spent advancing AI capabilities.4 While we are seeing increasing concern from AI experts, in 2022 I estimated there were around 400 people working directly on reducing the chances of an AI-related existential catastrophe (with a 90% confidence interval ranging between 200 and 1,000).3 Of these, around three quarters appeared to be working on technical AI safety research, with the rest split between strategy (and other governance) research and advocacy — though the field is changing fast.5
Solvability
Making progress on preventing an AI-related catastrophe seems hard, but there are a lot of avenues for more research and the field is very young. Governments started taking an active interest in regulating AI and mitigating these threats in 2023. So I think it’s moderately tractable, though I’m highly uncertain — again, assessments of the tractability of making AI safe vary enormously.
Profile depth
In-depth
This is one of many profiles we've written to help people find the most pressing problems they can solve with their careers. Learn more about how we compare different problems and see how this problem compares to the others we've considered so far.
Table of Contents
- 1 1. Many AI experts think there’s a non-negligible chance AI will lead to outcomes as bad as extinction
- 2 2. We’re making advances in AI extremely quickly
- 3 3. Power-seeking AI systems could pose an existential threat to humanity
- 4 This all sounds very abstract. What could an existential catastrophe caused by AI actually look like?
- 5 4. Even if we find a way to avoid power-seeking, there are still risks
- 6 So, how likely is an AI-related catastrophe?
- 7 5. We can tackle these risks
- 8 6. This work is neglected
- 9 What do we think are the best arguments against this problem being pressing?
- 10 Arguments against working on AI risk to which we think there are strong responses
- 11 What you can do concretely to help
- 12 Top resources to learn more
- 13 Acknowledgements
Note from the author: At its core, this problem profile tries to predict the future of technology. This is a notoriously difficult thing to do. In addition, there has been much less rigorous research into the risks from AI than into the other risks 80,000 Hours writes about (like pandemics or climate change).6 That said, there is a growing field of research into the topic, which I’ve tried to reflect. For this article I’ve leaned especially on this report by Joseph Carlsmith at Open Philanthropy (also available as a narration), as it’s the most rigorous overview of the risk that I could find. I’ve also had the article reviewed by over 30 people with different expertise and opinions on the topic. (Almost all are concerned about advanced AI’s potential impact.)
Why do we think that reducing risks from AI is one of the most pressing issues of our time? In short, our reasons are:
- Even before getting into the actual arguments, we can see some cause for concern — as many AI experts think there’s a small but non-negligible chance that AI will lead to outcomes as bad as human extinction.
- We’re making advances in AI extremely quickly — which suggests that AI systems could have a significant influence on society, soon.
- There are strong arguments that “power-seeking” AI systems could pose an existential threat to humanity7 — which we’ll go through below.
- Even if we find a way to avoid power-seeking, there are still other risks.
- We think we can tackle these risks.
- This work is neglected.
We’re going to cover each of these in turn, then consider some of the best counterarguments, explain concrete things you can do to help, and finally outline some of the best resources for learning more about this area.
If you’d like, you can watch our 10-minute video summarising the case for AI risk before reading further:
1. Many AI experts think there’s a non-negligible chance AI will lead to outcomes as bad as extinction
In May 2023, hundreds of prominent AI scientists — and other notable figures — signed a statement saying that mitigating the risk of extinction from AI should be a global priority.
So it’s pretty clear that at least some experts are concerned.
But how concerned are they? And is this just a fringe view?
We looked at four surveys of AI researchers who published at NeurIPS and ICML (two of the most prestigious machine learning conferences) from 2016, 2019, 2022 and 2023.8
It’s important to note that there could be considerable selection bias on surveys like this. For example, you might think researchers who go to the top AI conferences are more likely to be optimistic about AI, because they have been selected to think that AI research is doing good. Alternatively, you might think that researchers who are already concerned about AI are more likely to respond to a survey asking about these concerns.9
All that said, here’s what we found:
In all four surveys, the median researcher thought that the chances that AI would be “extremely good” was reasonably high: 20% in the 2016 survey, 20% in 2019, 10% in 2022, and 10% in 2023.10
Indeed, AI systems are already having substantial positive effects — for example, in medical care or academic research.
But in all four surveys, the median researcher also estimated small — and certainly not negligible — chances that AI would be “extremely bad (e.g. human extinction)”: a 5% chance of extremely bad outcomes in the 2016 survey, 2% in 2019, 5% in 2022 and 5% in 2023.11
In the 2022 survey, participants were specifically asked about the chances of existential catastrophe caused by future AI advances — and again, over half of researchers thought the chances of an existential catastrophe was greater than 5%.12
So experts disagree on the degree to which AI poses an existential risk — a kind of threat we’ve argued deserves serious moral weight.
This fits with our understanding of the state of the research field. Three of the leading companies developing AI — DeepMind, Anthropic and OpenAI — also have teams dedicated to figuring out how to solve technical safety issues that we believe could, for reasons we discuss at length below, lead to an existential threat to humanity.13
There are also several academic research groups (including at MIT, Cambridge, Carnegie Mellon University, and UC Berkeley) focusing on these same technical AI safety problems.14
It’s hard to know exactly what to take from all this, but we’re confident that it’s not a fringe position in the field to think that there is a material risk of outcomes as bad as an existential catastrophe. Some experts in the field maintain, though, that the risks are overblown.
Still, why do we side with those who are more concerned? In short, it’s because there are arguments we’ve found persuasive that AI could pose such an existential threat — arguments we will go through step by step below.
It’s important to recognise that the fact that many experts recognise there’s a problem doesn’t mean that everything’s OK because the experts have got it covered. Overall, we think this problem remains highly neglected (more on this below), especially as billions of dollars a year are spent to make AI more advanced.4
2. We’re making advances in AI extremely quickly

Before we try to figure out what the future of AI might look like, it’s helpful to take a look at what AI can already do.
Modern AI techniques involve machine learning (ML): models that improve automatically through data input. The most common form of this technique used today is known as deep learning.
For a brief explanation of how deep learning works, see here:
Machine learning techniques, in general, take some input data and produce some outputs, in a way that depends on some parameters in the model, which are learned automatically rather than being specified by programmers.
Most of the recent advances in machine learning use neural networks. A neural network transforms input data into output data by passing it through several hidden ‘layers’ of simple calculations, with each layer made up of ‘neurons.’ Each neuron receives data from the previous layer, performs some calculation based on its parameters (basically some numbers specific to that neuron), and passes the result on to the next layer.

The engineers developing the network will choose some measure of success for the network (known as a ‘loss’ or ‘objective’ function). The degree to which the network is successful (according to the measure chosen) will depend on the exact values of the parameters for each neuron on the network.
The network is then trained using a large quantity of data. By using an optimisation algorithm (most commonly stochastic gradient descent), the parameters of each neuron are gradually tweaked each time the network is tested against the data using the loss function. The optimisation algorithm will (generally) make the neural network perform slightly better each time the parameters are tweaked. Eventually, the engineers will end up with a network that performs pretty well on the measure chosen.
Deep learning refers to the use of neural networks with many layers.
To learn more, we recommend:
- 3Blue1Brown’s YouTube series on neural networks, an excellent video introduction
- A short introduction to machine learning by Richard Ngo, a short blog post giving an overview of the topic
- Machine learning for humans by Vishal Maini and Samer Sabri, a longer but accessible introduction to machine learning
ChatGPT’s release in November 2022 made many people realise that deep learning was a sea change in AI. Since then, large language models, image models, and other AI systems have continued to advance rapidly and drawn massive investments.16
Because the models get better so quickly, it can be hard for the public to keep up. You might have an outdated view of just how much modern AI systems can do if you haven’t used the latest models to their full extent.17
But we shouldn’t just think about what they can do now. We should think about how they’ve improved so far and how they’re likely to improve in the future.
For example, consider the rapid progress language models have made on the GPQA benchmark, which asks challenging, PhD-level questions about chemistry, physics, and biology:
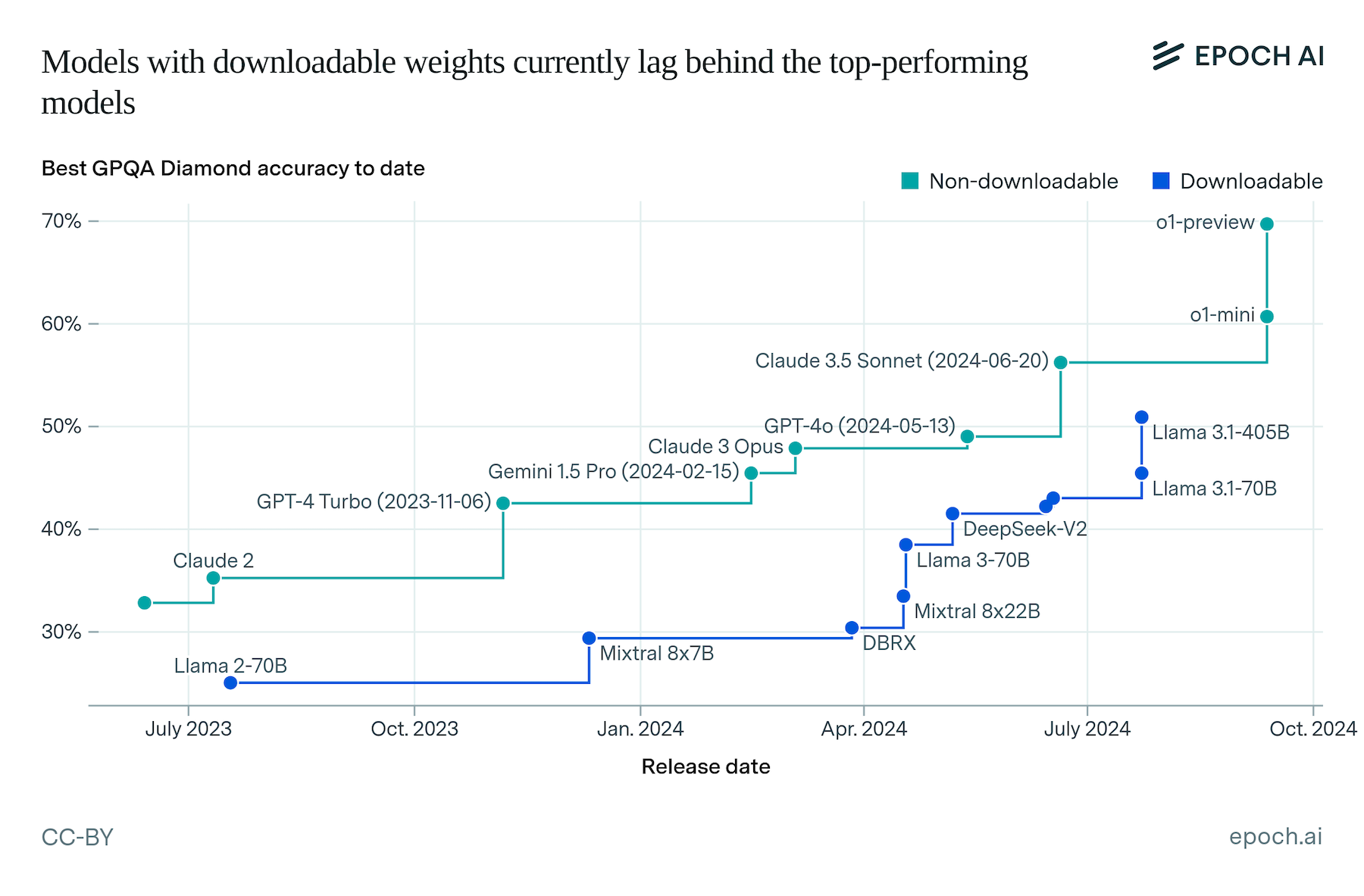
They’ve also shown impressive improvement on tasks like software engineering and expert-level math problems.
As of March 2025, other impressive achievements from AI systems include:
- Using computers: Anthropic and OpenAI have AI models that can be directed to carry out tasks independently on your computer. These capabilities are still rudimentary, but we expect them to improve quickly.
- Competing in math contests: By combining the models AlphaProof and AlphaGeometry 2, Google DeepMind was able to use AI to achieve silver medal performance in the International Mathematical Olympiad.
- Combining multiple human-like abilities: Models are increasingly multi-modal, which means they combine the abilities to write and read text, comprehend and create images, and understand and respond to spoken language.
- Predicting complex biomolecular structures and interactions: Google DeepMind’s AlphaFold 3 — a successor to a Nobel Prize-winning AI system — can predict how proteins interact with DNA, RNA, and other structures at the molecular level.
- Improving robotics: Google DeepMind’s Gemini Robotics model uses a language model to control robots, which can respond to verbal directions, demonstrate spatial awareness, and perform a range of real-world tasks.
- Self-driving cars: Waymo reportedly conducts 150,000 rides per week in self-driving cars as of March 2025 in major U.S. cities, an increase of 3x from just a few months before, with plans to expand further.
- Creating novel videos and images: Image models are now capable of generating high-quality images from written descriptions, and video models such as Sora and Veo can even produce impressive short clips based on text prompts.
- Enhancing the work of doctors, lawyers, and scientists: Researchers have found evidence that AI systems can outperform doctors in diagnosing patients, significantly improve the productivity of lawyers, and anticipate discoveries in neuroscience.
- Helping with AI research: There’s also evidence that AI systems can outperform humans in AI R&D tasks, when limited to a two-hour time window.18
If you’re anything like us, you found the complexity and breadth of the tasks these systems can carry out surprising.
And if the technology keeps advancing at this pace, it seems clear there will be major effects on society. At the very least, automating tasks makes carrying out those tasks cheaper. As a result, we may see rapid increases in economic growth (perhaps even to the level we saw during the Industrial Revolution).
If we’re able to partially or fully automate scientific advancement we may see more transformative changes to society and technology.19
That could be just the beginning. We may be able to get computers to eventually automate anything humans can do. This seems like it has to be possible — at least in principle. This is because it seems that, with enough power and complexity, a computer should be able to simulate the human brain. This would itself be a way of automating anything humans can do (if not the most efficient method of doing so).
And as we’ll see in the next section, there are some indications that extensive automation may well be possible through scaling up existing techniques.
Current trends show rapid progress in the capabilities of ML systems
There are three things that are crucial to building AI through machine learning:
- Good algorithms (e.g. more efficient algorithms are better)
- Data to train an algorithm
- Enough computational power (known as compute) to do this training
Epoch is a team of scientists investigating trends in the development of advanced AI — in particular, how these three inputs are changing over time.
They found that the amount of compute used for training the largest AI models has been rising exponentially — doubling on average every six months since 2010.
That means the amount of computational power used to train our largest machine learning models has grown by over one billion times.
Epoch also looked at how much compute has been needed to train a neural network to have the same performance on ImageNet (a well-known test data set for computer vision).
They found that the amount of compute required for the same performance has been falling exponentially — halving every 10 months.
So since 2012, the amount of compute required for the same level of performance has fallen by over 10,000 times. Combined with the increased compute used for training, that’s a lot of growth.
Finally, they found that the size of the data sets used to train the largest language models has been doubling roughly once a year since 2010. And Epoch has projected that it will be feasible to scale the existing pace of AI training on the frontier through 2030.
It’s hard to be sure that the capability growth will continue, but the trends speak to the incredible gains that are possible with machine learning.
Indeed, it looks like increasing the size of models (and the amount of compute used to train them) introduces ever more sophisticated behaviour. This is how systems like GPT-4 perform tasks they weren’t specifically trained for.
These observations have led to the scaling hypothesis: that we can simply build bigger and bigger neural networks, and as a result we will end up with more and more powerful artificial intelligence, and that this trend of increasing capabilities may increase to human-level AI and beyond.
If this is true, we can attempt to predict how the capabilities of AI technology will increase over time simply by looking at how quickly we are increasing the amount of compute available to train models.
In late 2024, we also started to see a new frontier for scaling in inference time compute. This is compute used when, for example, a language model answers a question.
The leading companies have found that by giving an AI model more time to “think” about its answers, to reason through different possibilities and select among them, they can perform much better. With this innovation, AI companies found a new way to make models even more powerful.
As we’ll see in the next section, it’s not just the scaling hypothesis that suggests we could end up with extremely powerful AI relatively soon — other methods of predicting AI progress come to similar conclusions.
When can we expect transformative AI?
It’s difficult to predict exactly when we will develop AI that we expect to be hugely transformative for society (for better or for worse) — for example, by automating all human work or drastically changing the structure of society.20
But by early 2025, leaders of some of the frontier AI companies were clearly stating that they were expecting to get very powerful AI systems soon.
OpenAI CEO Sam Altman, Anthropic CEO Dario Amodei, and Google DeepMind CEO Demis Hassabis all said that they expect to develop AI that can fully replace at least some forms of human labour within just a few years, or even less.
Sam Altman wrote in January 2025:
We are now confident we know how to build AGI as we have traditionally understood it. We believe that, in 2025, we may see the first AI agents “join the workforce” and materially change the output of companies.
Demis Hassabis said in January 2025:
We’ve sort of had a consistent view about AGI being a system that’s capable of exhibiting all of the cognitive capabilities humans can. And I think we’re getting closer and closer, but I think we’re still probably a handful of years away.
Dario Amodei wrote in February 2025:
Time is short, and we must accelerate our actions to match accelerating AI progress. Possibly by 2026 or 2027 (and almost certainly no later than 2030), the capabilities of AI systems will be best thought of as akin to an entirely new state populated by highly intelligent people appearing on the global stage — a “country of geniuses in a datacenter”— with the profound economic, societal, and security implications that would bring.
It’s reasonable to have some scepticism about these predictions.
Other approaches to forecasting the arrival of transformative AI systems have also suggested the technology is closer than many would assume:
- Data from the 2023 survey of 3000 AI experts implied there is 33% probability of human-level machine intelligence (which would plausibly be transformative in this sense) by 2036, 50% probability by 2047, and 80% by 2100.21 There are a lot of reasons to be suspicious of these estimates,9 but we take it as one data point.
- Ajeya Cotra (a researcher at Open Philanthropy) attempted to forecast transformative AI by comparing modern deep learning to the human brain. Deep learning involves using a huge amount of compute to train a model, before that model is able to perform some task. There’s also a relationship between the amount of compute used to train a model and the amount used by the model when it’s run. And — if the scaling hypothesis is true — we should expect the performance of a model to predictably improve as the computational power used increases. So Cotra used a variety of approaches (including, for example, estimating how much compute the human brain uses on a variety of tasks) to estimate how much compute might be needed to train a model that, when run, could carry out the hardest tasks humans can do. She then estimated when using that much compute would be affordable.
- Cotra’s 2022 update on her report’s conclusions estimates that there is a 35% probability of transformative AI by 2036, 50% by 2040, and 60% by 2050 — noting that these guesses are not stable.22
- Tom Davidson (also a researcher at Open Philanthropy) wrote a report to complement Cotra’s work. He attempted to figure out when we might expect to see transformative AI based only on looking at various types of research that transformative AI might be like (e.g. developing technology that’s the ultimate goal of a STEM field, or proving difficult mathematical conjectures), and how long it’s taken for each of these kinds of research to be completed in the past, given some quantity of research funding and effort.
- Davidson’s report estimates that, solely on this information, you’d think that there was an 8% chance of transformative AI by 2036, 13% by 2060, and 20% by 2100. However, Davidson doesn’t consider the actual ways in which AI has progressed since research started in the 1950s, and notes that it seems likely that the amount of effort we put into AI research will increase as AI becomes increasingly relevant to our economy. As a result, Davidson expects these numbers to be underestimates.
- Holden Karnofsky attempted to sum up the findings of others’ forecasts. In 2021, he guessed that there was more than a 10% chance we’d see transformative AI by 2036, 50% by 2060, and 66% by 2100.
| Method | Chance of transformative AI by 2036 | Chance of transformative AI by 2060 | Chance of transformative AI by 2100 |
|---|---|---|---|
| Expert survey (Grace et al., 2024) | 33% | 50% (by 2047) | 80% |
| Expert survey (Zhang et al., 2022) | 20% | 50% | 85% |
| Biological anchors (Cotra, 2022) | 35% | 60% (by 2050) | 80% (according to the 2020 report) |
| Semi-informative priors (Davidson, 2021) | 8% | 13% | 20% |
| Overall guess (Karnofsky, 2021) | 10% | 50% | 66% |
All in all, AI seems to be advancing rapidly. More money and talent is going into the field every year, models are getting bigger and more efficient, and we keep learning about new ways to improve their capabilities.
Even if AI were advancing more slowly, we’d be concerned about it — most of the arguments about the risks from AI (that we’ll get to below) do not depend on this rapid progress. And it’s possible that the existing progress could stall out before the technology becomes truly transformative.
However, the speed of these recent developments increases the urgency of the issue. And all the estimates in the above table were made before many of the impressive advancements in 2024 and early 2025, so they may even overstate how much time we have.
In fact, we think it’s plausible that extremely powerful AI systems that can replace much of human labour will be here before 2030, as we’ve discussed elsewhere.23 And it’s worth taking action on that basis.
3. Power-seeking AI systems could pose an existential threat to humanity
We’ve argued so far that we expect AI to be an important — and potentially transformative — new technology.
We’ve also seen reason to think that such transformative AI systems could be built in the near future.
Now we’ll turn to the core question: why do we think this matters so much?
There could be a lot of reasons. If advanced AI is as transformative as it seems like it’ll be, there will be many important consequences. But here we are going to explain the issue that seems most concerning to us: AI systems could pose risks by seeking and gaining power.
We’ll argue that:
- It’s likely that we’ll build AI systems that can make and execute plans to achieve goals
- Advanced planning systems could easily be ‘misaligned’ — in a way that could lead them to make plans that involve disempowering humanity
- Disempowerment by AI systems would be an existential catastrophe
- People might deploy AI systems that are misaligned, despite this risk
Thinking through each step, I think there’s something like a 1% chance of an existential catastrophe resulting from power-seeking AI systems this century. This is my all things considered guess at the risk incorporating considerations of the argument in favour of the risk (which is itself probabilistic), as well as reasons why this argument might be wrong (some of which I discuss below). This puts me on the less worried end of 80,000 Hours staff, whose views on our last staff survey ranged from 1–55%, with a median of 15%.
It’s likely we’ll build advanced planning systems
We’re going to argue that future systems with the following three properties might pose a particularly important threat to humanity:24
They have goals and are good at making plans.
Not all AI systems have goals or make plans to achieve those goals. But some systems (like some chess-playing AI systems) can be thought of in this way. When discussing power-seeking AI, we’re considering planning systems that are relatively advanced, with plans that are in pursuit of some goal(s), and that are capable of carrying out those plans.
They have excellent strategic awareness.
A particularly good planning system would have a good enough understanding of the world to notice obstacles and opportunities that may help or hinder its plans, and respond to these accordingly. Following Carlsmith, we’ll call this strategic awareness, since it allows systems to strategise in a more sophisticated way.
They have highly advanced capabilities relative to today’s systems.
For these systems to actually affect the world, we need them to not just make plans, but also be good at all the specific tasks required to execute those plans.
Since we’re worried about systems attempting to take power from humanity, we are particularly concerned about AI systems that might be better than humans on one or more tasks that grant people significant power when carried out well in today’s world.
For example, people who are very good at persuasion and/or manipulation are often able to gain power — so an AI being good at these things might also be able to gain power. Other examples might include hacking into other systems, tasks within scientific and engineering research, as well as business, military, or political strategy.
These systems seem technically possible and we’ll have strong incentives to build them
As we saw above, we’ve already produced systems that are very good at carrying out specific tasks.
We’ve also already produced rudimentary planning systems, like AlphaStar, which skilfully plays the strategy game Starcraft, and MuZero, which plays chess, shogi, and Go.25
We’re not sure whether these systems are producing plans in pursuit of goals per se, because we’re not sure exactly what it means to “have goals.” However, since they consistently plan in ways that achieve goals, it seems like they have goals in some sense.
Moreover, some existing systems seem to actually represent goals as part of their neural networks.26
That said, planning in the real world (instead of games) is much more complex, and to date we’re not aware of any unambiguous examples of goal-directed planning systems, or systems that exhibit high degrees of strategic awareness.
But as we’ve discussed, we expect to see further advances within this century. And we think these advances are likely to produce systems with all three of the above properties.
That’s because we think that there are particularly strong incentives (like profit) to develop these kinds of systems. In short: because being able to plan to achieve a goal, and execute that plan, seems like a particularly powerful and general way of affecting the world.
Getting things done — whether that’s a company selling products, a person buying a house, or a government developing policy — almost always seems to require these skills. One example would be assigning a powerful system a goal and expecting the system to achieve it — rather than having to guide it every step of the way. So planning systems seem likely to be (economically and politically) extremely useful.27
And if systems are extremely useful, there are likely to be big incentives to build them. For example, an AI that could plan the actions of a company by being given the goal to increase its profits (that is, an AI CEO) would likely provide significant wealth for the people involved — a direct incentive to produce such an AI.
As a result, if we can build systems with these properties (and from what we know, it seems like we will be able to), it seems like we are likely to do so.28
Advanced planning systems could easily be dangerously ‘misaligned’
There are reasons to think that these kinds of advanced planning AI systems will be misaligned. That is, they will aim to do things that we don’t want them to do.29
There are many reasons why systems might not be aiming to do exactly what we want them to do. For one thing, we don’t know how, using modern ML techniques, to give systems the precise goals we want (more here).30
We’re going to focus specifically on some reasons why systems might by default be misaligned in such a way that they develop plans that pose risks to humanity’s ability to influence the world — even when we don’t want that influence to be lost.31
What do we mean by “by default”? Essentially, unless we actively find solutions to some (potentially quite difficult) problems, then it seems like we’ll create dangerously misaligned AI. (There are reasons this might be wrong — which we discuss later.)
Three examples of “misalignment” in a variety of systems
It’s worth noting that misalignment isn’t a purely theoretical possibility (or specific to AI) — we see misaligned goals in humans and institutions all the time, and have also seen examples of misalignment in AI systems.32
The democratic political framework is intended to ensure that politicians make decisions that benefit society. But what political systems actually reward is winning elections, so that’s what many politicians end up aiming for.
This is a decent proxy goal — if you have a plan to improve people’s lives, they’re probably more likely to vote for you — but it isn’t perfect. As a result, politicians do things that aren’t clearly the best way of running a country, like raising taxes at the start of their term and cutting them right before elections.
That is to say, the things the system does are at least a little different from what we would, in a perfect world, want it to do: the system is misaligned.
Companies have profit-making incentives. By producing more, and therefore helping people obtain goods and services at cheaper prices, companies make more money.
This is sometimes a decent proxy for making the world better, but profit isn’t actually the same as the good of all of humanity (bold claim, we know). As a result, there are negative externalities: for example, companies will pollute to make money despite this being worse for society overall.
Again, we have a misaligned system, where the things the system does are at least a little different from what we would want it to do.
DeepMind has documented examples of specification gaming: an AI doing well according to its specified reward function (which encodes our intentions for the system), but not doing what researchers intended.
In one example, a robot arm was asked to grasp a ball. But the reward was specified in terms of whether humans thought the robot had been successful. As a result, the arm learned to hover between the ball and the camera, fooling the humans into thinking that it had grasped the ball.33
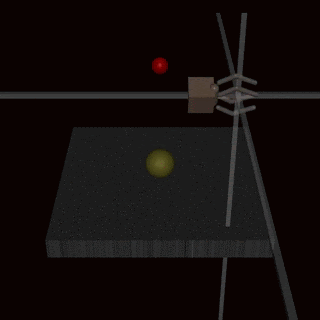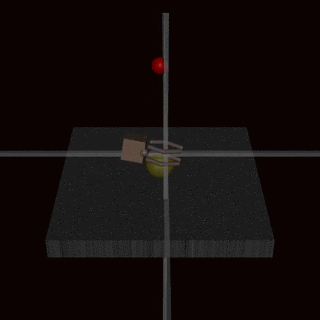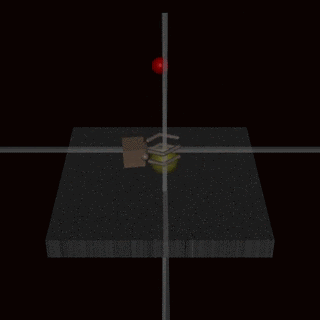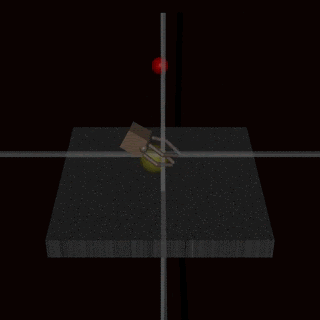
So we know it’s possible to create a misaligned AI system.
Why these systems could (by default) be dangerously misaligned
Here’s the core argument of this article. We’ll use all three properties from earlier: planning ability, strategic awareness, and advanced capabilities.
To start, we should realise that a planning system that has a goal will also develop ‘instrumental goals’: things that, if they occur, will make it easier to achieve an overall goal.
We use instrumental goals in plans all the time. For example, a high schooler planning their career might think that getting into university will be helpful for their future job prospects. In this case, “getting into university” would be an instrumental goal.
A sufficiently advanced AI planning system would also include instrumental goals in its overall plans.
If a planning AI system also has enough strategic awareness, it will be able to identify facts about the real world (including potential things that would be obstacles to any plans), and plan in light of them. Crucially, these facts would include that access to resources (e.g. money, compute, influence) and greater capabilities — that is, forms of power — open up new, more effective ways of achieving goals.
This means that, by default, advanced planning AI systems would have some worrying instrumental goals:
- Self-preservation — because a system is more likely to achieve its goals if it is still around to pursue them (in Stuart Russell’s memorable phrase, “You can’t fetch the coffee if you’re dead”).
- Preventing any changes to the AI system’s goals — since changing its goals would lead to outcomes that are different from those it would achieve with its current goals.
- Gaining power — for example, by getting more resources and greater capabilities.
Crucially, one clear way in which the AI can ensure that it will continue to exist (and not be turned off), and that its objectives will never be changed, would be to gain power over the humans who might affect it (we talk here about how AI systems might actually be able to do that).
What’s more, the AI systems we’re considering have advanced capabilities — meaning they can do one or more tasks that grant people significant power when carried out well in today’s world. With such advanced capabilities, these instrumental goals will not be out of reach, and as a result, it seems like the AI system would use its advanced capabilities to get power as part of the plan’s execution. If we don’t want the AI systems we create to take power away from us this would be a particularly dangerous form of misalignment.
In the most extreme scenarios, a planning AI system with sufficiently advanced capabilities could successfully disempower us completely.
As a (very non-rigorous) intuitive check on this argument, let’s try to apply it to humans.
Humans have a variety of goals. For many of these goals, some form of power-seeking is advantageous: though not everyone seeks power, many people do (in the form of wealth or social or political status), because it’s useful for getting what they want. This is not catastrophic (usually!) because, as human beings:
- We generally feel bound by human norms and morality (even people who really want wealth usually aren’t willing to kill to get it).
- We aren’t that much more capable or intelligent than one another. So even in cases where people aren’t held back by morality, they’re not able to take over the world.
(We discuss whether humans are truly power-seeking later.)
A sufficiently advanced AI wouldn’t have those limitations.
It might be hard to find ways to prevent this sort of misalignment
The point of all this isn’t to say that any advanced planning AI system will necessarily attempt to seek power. Instead, it’s to point out that, unless we find a way to design systems that don’t have this flaw, we’ll face significant risk.
It seems more than plausible that we could create an AI system that isn’t misaligned in this way, and thereby prevent any disempowerment. Here are some strategies we might take (plus, unfortunately, some reasons why they might be difficult in practice):34
Control the objectives of the AI system. We may be able to design systems that simply don’t have objectives to which the above argument applies — and thus don’t incentivise power-seeking behaviour. For example, we could find ways to explicitly instruct AI systems not to harm humans, or find ways to reward AI systems (in training environments) for not engaging in specific kinds of power-seeking behaviour (and also find ways to ensure that this behaviour continues outside the training environment).
Carlsmith gives two reasons why doing this seems particularly hard.
First, for modern ML systems, we don’t get to explicitly state a system’s objectives — instead we reward (or punish) a system in a training environment so that it learns on its own. This raises a number of difficulties, one of which is goal misgeneralisation. Researchers have uncovered real examples of systems that appear to have learned to pursue a goal in the training environment, but then fail to generalise that goal when they operate in a new environment. This raises the possibility that we could think we’ve successfully trained an AI system not to seek power — but that the system would seek power anyway when deployed in the real world.35
Second, when we specify a goal to an AI system (or, when we can’t explicitly do that, when we find ways to reward or punish a system during training), we usually do this by giving the system a proxy by which outcomes can be measured (e.g. positive human feedback on a system’s achievement). But often those proxies don’t quite work.36 In general, we might expect that even if a proxy appears to correlate well with successful outcomes, it might not do so when that proxy is optimised for. (The examples above of politicians, companies, and the robot arm failing to grasp a ball are illustrations of this.) We’ll look at a more specific example of how problems with proxies could lead to an existential catastrophe here.
For more on the specific difficulty of controlling the objectives given to deep neural networks trained using self-supervised learning and reinforcement learning, we recommend former OpenAI governance researcher Richard Ngo’s discussion of how realistic training processes lead to the development of misaligned goals.
Control the inputs into the AI system. AI systems will only develop plans to seek power if they have enough information about the world to realise that seeking power is indeed a way to achieve its goals.
Control the capabilities of the AI system. AI systems will likely only be able to carry out plans to seek power if they have sufficiently advanced capabilities in skills that grant people significant power in today’s world.
But to make any strategy work, it will need to both:
- Retain the usefulness of the AI systems — and so remain economically competitive with less safe systems. Controlling the inputs and capabilities of AI systems will clearly have costs, so it seems hard to ensure that these controls, even if they’re developed, are actually used. But this is also a problem for controlling a system’s objectives. For example, we may be able to prevent power-seeking behaviour by ensuring that AI systems stop to check in with humans about any decisions they make. But these systems might be significantly slower and less immediately useful to people than systems that don’t stop to carry out these checks. As a result, there might still be incentives to use a faster, more initially effective misaligned system (we’ll look at incentives more in the next section).
Continue to work as the planning ability and strategic awareness of systems improve over time. Some seemingly simple solutions (for example, trying to give a system a long list of things it isn’t allowed to do, like stealing money or physically harming humans) break down as the planning abilities of the systems increase. This is because, the more capable a system is at developing plans, the more likely it is to identify loopholes or failures in the safety strategy — and as a result, the more likely the system is to develop a plan that involves power-seeking.
Ultimately, by looking at the state of the research on this topic, and speaking to experts in the field, we think that there are currently no known ways of building aligned AI systems that seem likely to fulfil both these criteria.
So: that’s the core argument. There are many variants of this argument. Some have argued that AI systems might gradually shape our future via subtler forms of influence that nonetheless could amount to an existential catastrophe; others argue that the most likely form of disempowerment is in fact just killing everyone. We’re not sure how a catastrophe would be most likely to play out, but have tried to articulate the heart of the argument, as we see it: that AI presents an existential risk.
There are definitely reasons this argument might not be right! We go through some of the reasons that seem strongest to us below. But overall it seems possible that, for at least some kinds of advanced planning AI systems, it will be harder to build systems that don’t seek power in this dangerous way than to build systems that do.
At this point, you may have questions like:
- Why can’t we just unplug a dangerous AI?
- Surely a truly intelligent AI system would know not to disempower everyone?
- Couldn’t we just ‘sandbox’ any potentially dangerous AI system until we know it’s safe?
We think there are good responses to all these questions, so we’ve added a long list of arguments against working on AI risk — and our responses — for these (and other) questions below.
Disempowerment by AI systems would be an existential catastrophe
When we say we’re concerned about existential catastrophes, we’re not just concerned about risks of extinction. This is because the source of our concern is rooted in longtermism: the idea that the lives of all future generations matter, and so it’s extremely important to protect their interests.
This means that any event that could prevent all future generations from living lives full of whatever you think makes life valuable (whether that’s happiness, justice, beauty, or general flourishing) counts as an existential catastrophe.
It seems extremely unlikely that we’d be able to regain power over a system that successfully disempowers humanity. And as a result, the entirety of the future — everything that happens for Earth-originating life, for the rest of time — would be determined by the goals of systems that, although built by us, are not aligned with us. Perhaps those goals will create a long and flourishing future, but we see little reason for confidence.37
This isn’t to say that we don’t think AI also poses a risk of human extinction. Indeed, we think making humans extinct is one highly plausible way in which an AI system could completely and permanently ensure that we are never able to regain power.
People might deploy misaligned AI systems despite the risk
Surely no one would actually build or use a misaligned AI if they knew it could have such terrible consequences, right?
Unfortunately, there are at least two reasons people might create and then deploy misaligned AI — which we’ll go through one at a time:38
1. People might think it’s aligned when it’s not
Imagine there’s a group of researchers trying to tell, in a test environment, whether a system they’ve built is aligned. We’ve argued that an intelligent planning AI will want to improve its abilities to effect changes in pursuit of its objective, and it’s almost always easier to do that if it’s deployed in the real world, where a much wider range of actions are available. As a result, any misaligned AI that’s sophisticated enough will try to understand what the researchers want it to do and at least pretend to be doing that, deceiving the researchers into thinking it’s aligned. (For example, a reinforcement learning system might be rewarded for certain apparent behaviour during training, regardless of what it’s actually doing.)
Hopefully, we’ll be aware of this sort of behaviour and be able to detect it. But catching a sufficiently advanced AI in deception seems potentially harder than catching a human in a lie, which isn’t always easy. For example, a sufficiently intelligent deceptive AI system may be able to deceive us into thinking we’ve solved the problem of AI deception, even if we haven’t.
If AI systems are good at deception, and have sufficiently advanced capabilities, a reasonable strategy for such a system could be to deceive humans completely until the system has a way to guarantee it can overcome any resistance to its goals.
2. There are incentives to deploy systems sooner rather than later
We might also expect some people with the ability to deploy a misaligned AI to charge ahead despite any warning signs of misalignment that do come up, because of race dynamics — where people developing AI want to do so before anyone else.
For example, if you’re developing an AI to improve military or political strategy, it’s much more useful if none of your rivals have a similarly powerful AI.
These incentives apply even to people attempting to build an AI in the hopes of using it to make the world a better place.
For example, say you’ve spent years and years researching and developing a powerful AI system, and all you want is to use it to make the world a better place. Simplifying things a lot, say there are two possibilities:
- This powerful AI will be aligned with your beneficent aims, and you’ll transform society in a potentially radically positive way.
- The AI will be sufficiently misaligned that it’ll take power and permanently end humanity’s control over the future.
Let’s say you think there’s a 90% chance that you’ve succeeded in building an aligned AI. But technology often develops at similar speeds across society, so there’s a good chance that someone else will soon also develop a powerful AI. And you think they’re less cautious, or less altruistic, so you think their AI will only have an 80% chance of being aligned with good goals, and pose a 20% chance of existential catastrophe. And only if you get there first can your more beneficial AI be dominant. As a result, you might decide to go ahead with deploying your AI, accepting the 10% risk.
This all sounds very abstract. What could an existential catastrophe caused by AI actually look like?
The argument we’ve given so far is very general, and doesn’t really look at the specifics of how an AI that is attempting to seek power might actually do so.
If you’d like to get a better understanding of what an existential catastrophe caused by AI might actually look like, we’ve written a short separate article on that topic. If you’re happy with the high-level abstract arguments so far, feel free to skip to the next section!
What could an existential AI catastrophe actually look like?
4. Even if we find a way to avoid power-seeking, there are still risks
So far we’ve described what a large proportion of researchers in the field7 think is the major existential risk from potential advances in AI, which depends crucially on an AI seeking power to achieve its goals.
If we can prevent power-seeking behaviour, we will have reduced existential risk substantially.
But even if we succeed, there are still existential risks that AI could pose.
There are at least two ways these risks could arise:
- We expect that AI systems will help increase the rate of scientific progress.39 While there would be clear benefits to this automation — the rapid development of new medicine, for example — some forms of technological development can pose threats, including existential threats, to humanity. This technological advancement might increase our available destructive power or make dangerous technologies cheaper or more widely accessible.
- We might start to see AI automate many – or possibly even all – economically important tasks. It’s hard to predict exactly what the effects of this would be on society. But it seems plausible that this could increase existential risks. For example, if AI systems are highly transformative, then their use (or potential use) could possibly create insurmountable power imbalances. Even the threat of this might be enough. For example, a military might feel pushed to create transformative automated weapons because it knows or believes its enemies are doing so, even if this dynamic benefits no one.
We know of several specific areas in which advanced AI may increase existential risks, though are likely others we haven’t thought of.
Bioweapons
In 2022, Collaborations Pharmaceuticals — a small research corporation in North Carolina — were building an AI model to help determine the structure of new drugs. As part of this process, they trained the model to penalise drugs that it predicted were toxic. This had just one problem: you could run the toxicity prediction in reverse to invent new toxic drugs.
Some of the deadliest events in human history have been pandemics. Pathogens’ ability to infect, replicate, kill, and spread — often undetected — make them exceptionally dangerous.
Even without AI, advancing biotechnology poses extreme risks. It potentially provides opportunities for state actors or terrorists to create mass-casualty events.
Advances in AI have the potential to make biotechnology more dangerous.
For example:
- Dual-use tools, like the automation of laboratory processes, could lower the barriers for rogue actors trying to manufacture a dangerous pandemic virus.40 The Collaborations Pharmaceuticals model is an example of a dual-use tool (although it’s not particularly dangerous).
AI-based biological design tools could enable sophisticated actors to reprogram the genomes of dangerous pathogens to specifically enhance their lethality, transmissibility, and immune evasion.41
If AI is able to advance the rate of scientific and technological progress, these risks may be amplified and accelerated — making dangerous technology more widely available or increasing its possible destructive power.42
In the 2023 survey of AI experts, 73% of respondents said they had either “extreme” or “substantial” concern that in the future Al will let “dangerous groups make powerful tools (e.g. engineered viruses).”43
Intentionally dangerous AI agents
Most of this article discusses the risk of power-seeking AI systems that arise unintentionally due to misalignment.
But we can’t rule out the possibility that some people might intentionally create rogue AI agents that seek to disempower humanity. It might seem hard to imagine, but extremist ideologies of many forms have inspired humans to carry out radically violent and even self-destructive plans.44
Cyberweapons
AI can already be used in cyberattacks, such as phishing, and more powerful AI may cause greater information security challenges (though it could also be useful in cyberdefense).
On its own, AI-enabled cyberwarfare is unlikely to pose an existential threat to humanity. Even the most damaging and costly societal-scale cyberattacks wouldn’t approach an extinction-level event.
But AI-enabled cyberattacks could provide access to other dangerous technology, such as bioweapons, nuclear arsenals, or autonomous weapons. So there may be genuine existential risks posed by AI-related cyberweapons, but they will most likely run through another existential risk.
The cyber capabilities of AI systems are also relevant to how a power-seeking AI could actually take power.
Other dangerous tech
If AI systems generally accelerate the rate of scientific and technological progress, we think it’s reasonably likely that we’ll invent new dangerous technologies.
For example, atomically precise manufacturing, sometimes called nanotechnology, has been hypothesised as an existential threat — and it’s a scientifically plausible technology that AI could help us invent far sooner than we would otherwise.
In The Precipice, Toby Ord estimated the chances of an existential catastrophe by 2120 from “unforeseen anthropogenic risks” at 1 in 30. This estimate suggests there could be other discoveries, perhaps involving yet to be understood physics, that could enable the creation of technologies with catastrophic consequences.45
AI could empower totalitarian governments
An AI-enabled authoritarian government could completely automate the monitoring and repression of its citizens, as well as significantly influence the information people see, perhaps making it impossible to coordinate action against such a regime.
AI is already facilitating the ability of governments to monitor their own citizens.
The NSA is using AI to help filter the huge amounts of data they collect, significantly speeding up their ability to identify and predict the actions of people they are monitoring. In China, AI is increasingly being used for facial recognition and predictive policing, including automated racial profiling and automatic alarms when people classified as potential threats enter certain public places.
These sorts of surveillance technologies seem likely to significantly improve — thereby increasing governments’ abilities to control their populations.
At some point, authoritarian governments could extensively use AI-related technology to:
- Monitor and track dissidents
- Preemptively suppress opposition to the ruling party
- Control the military and dominate external actors
- Manipulate information flows and carefully shape public opinion
Again, in the 2023 survey of AI experts, 73% of respondents expressed “extreme” or “substantial” concern that in the future authoritarian rulers could “use Al to control their population.”43
If a regime achieved a form of truly stable totalitarianism, it could make people’s lives much worse for a long time into the future, making it a particularly scary possible scenario resulting from AI. (Read more in our article on risks of stable totalitarianism.)
AI could worsen war
We’re concerned that great power conflict could also pose a substantial threat to our world, and advances in AI seem likely to change the nature of war — through lethal autonomous weapons46 or through automated decision making.47
In some cases, great power war could pose an existential threat — for example, if the conflict is nuclear. Some argue that lethal autonomous weapons, if sufficiently powerful and mass-produced, could themselves constitute a new form of weapon of mass destruction.
And if a single actor produces particularly powerful AI systems, this could be seen as giving them a decisive strategic advantage. Such an outcome, or even the expectation of such an outcome, could be highly destabilising.
Imagine that the US was working to produce a planning AI that’s intelligent enough to ensure that Russia or China could never successfully launch another nuclear weapon. This could incentivise a first strike from the actor’s rivals before these AI-developed plans can ever be put into action.
This is because nuclear deterrence can benefit from symmetry between the abilities of nuclear powers, in that the threat of a nuclear response to a first strike is believable and therefore a deterrent to a first strike. Advances in AI, which could be directly applied to nuclear forces, could create asymmetries in the capabilities of nuclear-armed nations. This could include improving early warning systems, air defence systems, and cyberattacks that disable weapons.
For example, many countries use submarine-launched ballistic missiles as part of their nuclear deterrence systems — the idea is that if nuclear weapons can be hidden under the ocean, they will never be destroyed in the first strike. This means that they can always be used for a counterattack, and therefore act as an effective deterrent against first strikes. But AI could make it far easier to detect submarines underwater, enabling their destruction in a first strike — removing this deterrent.
Many other destabilising scenarios are likely possible.
A report from the Stockholm International Peace Research Institute found that, while AI could potentially also have stabilising effects (for example by making everyone feel more vulnerable, decreasing the chances of escalation), destabilising effects could arise even before advances in AI are actually deployed. This is because one state’s belief that their opponents have new nuclear capabilities can be enough to disrupt the delicate balance of deterrence.
Luckily, there are also plausible ways in which AI could help prevent the use of nuclear weapons — for example, by improving the ability of states to detect nuclear launches, which would reduce the chances of false alarms like those that nearly caused nuclear war in 1983.
Overall, we’re uncertain about whether AI will substantially increase the risk of nuclear or conventional conflict in the short term — it could even end up decreasing the risk. But we think it’s important to pay attention to possible catastrophic outcomes and take reasonable steps to reduce their likelihood.
Other risks from AI
We’re also concerned about the following issues:
- Existential threats that result not from the power-seeking behaviour of AI systems, but from the interaction between AI systems. (In order to pose a risk, these systems would still need to be, to some extent, misaligned.)
- Other ways we haven’t thought of that AI systems could be misused — especially ones that might significantly affect future generations.
- Other moral mistakes made in the design and use of AI systems, particularly if future AI systems are themselves deserving of moral consideration. For example, we might (inadvertently) create sentient AI systems, which could then suffer in huge numbers. We think this could be extremely important, so we’ve written about it in a separate problem profile.
So, how likely is an AI-related catastrophe?
This is a really difficult question to answer.
There are no past examples we can use to determine the frequency of AI-related catastrophes.
All we have to go off are arguments (like the ones we’ve given above), and less relevant data like the history of technological advances. And we’re definitely not certain that the arguments we’ve presented are completely correct.
Consider the argument we gave earlier about the dangers of power-seeking AI systems in particular, based off Carlsmith’s report. At the end of his report, Carlsmith gives some rough guesses of the chances that each stage of his argument is correct (conditional on the previous stage being correct):
- By 2070 it will be possible and financially feasible to build strategically aware systems that can outperform humans on many power-granting tasks, and that can successfully make and carry out plans: Carlsmith guesses there’s a 65% chance of this being true.
- Given this feasibility, there will be strong incentives to build such systems: 80%.
- Given both the feasibility and incentives to build such systems, it will be much harder to develop aligned systems that don’t seek power than to develop misaligned systems that do, but which are at least superficially attractive to deploy: 40%.
- Given all of this, some deployed systems will seek power in a misaligned way that causes over $1 trillion (in 2021 dollars) of damage: 65%.
- Given all the previous premises, misaligned power-seeking AI systems will end up disempowering basically all of humanity: 40%.
- Given all the previous premises, this disempowerment will constitute an existential catastrophe: 95%.
Multiplying these numbers together, Carlsmith estimated that there’s a 5% chance that his argument is right and there will be an existential catastrophe from misaligned power-seeking AI systems by 2070. When we spoke to Carlsmith, he noted that in the year between the writing of his report and the publication of this article, his overall guess at the chance of an existential catastrophe from power-seeking AI systems by 2070 had increased to >10%.48
The overall probability of existential catastrophe from AI would, in Carlsmith’s view, be higher than this, because there are other routes to possible catastrophe — like those discussed in the previous section — although our guess is that these other routes are probably a lot less likely to lead to existential catastrophe.
For another estimate, in The Precipice, philosopher and advisor to 80,000 Hours Toby Ord estimated a 1-in-6 risk of existential catastrophe by 2120 (from any cause), and that 60% of this risk comes from misaligned AI — giving a total of a 10% risk of existential catastrophe from misaligned AI by 2120.
A 2021 survey of 44 researchers working on reducing existential risks from AI found the median risk estimate was 32.5% — the highest answer given was 98%, and the lowest was 2%.49 There’s obviously a lot of selection bias here: people choose to work on reducing risks from AI because they think this is unusually important, so we should expect estimates from this survey to be substantially higher than estimates from other sources. But there’s clearly significant uncertainty about how big this risk is, and huge variation in answers.
All these numbers are shockingly, disturbingly high. We’re far from certain that all the arguments are correct. But these are generally the highest guesses for the level of existential risk of any of the issues we’ve examined (like engineered pandemics, great power conflict, climate change, or nuclear war).
That said, I think there are reasons why it’s harder to make guesses about the risks from AI than other risks – and possibly reasons to think that the estimates we’ve quoted above are systematically too high.
If I was forced to put a number on it, I’d say something like 1%. This number includes considerations both in favour and against the argument. I’m less worried than other 80,000 Hours staff — our position as an organisation is that the risk is between 3% and 50%.
All this said, the arguments for such high estimates of the existential risk posed by AI are persuasive — making risks from AI a top contender for the most pressing problem facing humanity.
Here are some more questions you might have:
- Can it make sense to dedicate my career to solving an issue based on a speculative story about a technology that may or may not ever exist?
- Is this a form of ‘Pascal’s mugging’ — taking a big bet on tiny probabilities?
Again, we think there are strong responses to these questions.
5. We can tackle these risks
We think one of the most important things you can do would be to help reduce the gravest risks that AI poses.
This isn’t just because we think these risks are high — it’s also because we think there are real things we can do to reduce these risks.
We know of two main ways people work to reduce these risks:
- Technical AI safety research
- AI governance and policy work
There are lots of ways to contribute to this work. In this section, we discuss many broad approaches within both categories to illustrate the point that there are things we can do to address these risks. Below, we discuss the kinds of careers you can pursue to work on these kinds of approaches.
Technical AI safety research
The benefits of transformative AI could be huge, and there are many different actors involved (operating in different countries), which means it will likely be really hard to prevent its development altogether.
(It’s also possible that it wouldn’t even be a good idea if we could — after all, that would mean forgoing the benefits as well as preventing the risks.)
As a result, we think it makes more sense to focus on making sure that this development is safe — meaning that it has a high probability of avoiding all the catastrophic failures listed above.
One way to do this is to try to develop technical solutions to prevent the kind of power-seeking behaviour we discussed earlier — this is generally known as working on technical AI safety, sometimes called just “AI safety” for short.
We discuss this path in more detail here:
Career review of technical AI safety research
Approaches
There are lots of approaches to technical AI safety, including:
- Scalably learning from human feedback. Examples include iterated amplification, AI safety via debate, building AI assistants that are uncertain about our goals and learn them by interacting with us, and other ways to get AI systems to report truthfully what they know.
- Threat modelling. An example of this work would be demonstrating the possibility of (allowing us to study) dangerous capabilities, like deceptive or manipulative AI systems. This approach splits into work that evaluates whether a model has dangerous capabilities (like the work of METR in evaluating GPT-4), and work that evaluates whether a model would cause harm in practice (like Anthropic’s research into the behaviour of large language models and this paper on goal misgeneralisation). It can also include work to find ‘model organisms of misalignment’, in the hope of better understanding their dangers.
- Work to figure out how to control powerful AI systems – preventing them from causing harm even if they are unsafe. Read more in this blogpost from the team at Redwood Research working on control.
- Interpretability research. This work involves studying why AI systems do what they do and trying to put it into human-understandable terms. For example, this paper examined how AlphaZero learns chess, and this paper looked into finding latent knowledge in language models without supervision. This category also includes mechanistic interpretability — for example, Zoom In: An Introduction to Circuits by Olah et al.. For more, see this survey paper, as well as Hubinger’s a transparency and interpretability tech tree, and Nanda’s A Longlist of Theories of Impact for Interpretability for overviews of of how interpretability research could reduce existential risk from AI.
- Other anti-misuse research to reduce the risks of catastrophe caused by misuse of systems. For example, this work includes training AIs so they’re hard to use for dangerous purposes. (Note there’s lots of overlap with the other work on this list).
- Research to increase the robustness of neural networks. This work involves ensuring that the sorts of behaviour neural networks display when exposed to one set of inputs continues when exposed to inputs they haven’t previously been exposed to, in order to prevent AI systems changing to unsafe behaviour. See section 2 of Unsolved Problems in AI safety for more.
- Work to build cooperative AI. Find ways to ensure that even if individual AI systems seem safe, they don’t produce bad outcomes through interacting with other sociotechnical systems. For more, see Open Problems in Cooperative AI by Dafoe et al. or the Cooperative AI Foundation. This seems particularly relevant for the reduction of ‘s-risks.’
- More generally, there are some unified safety plans. For more, see Hubinger’s 11 possible proposals for building safe advanced AI, or Karnofsky’s How might we align transformative AI if it’s developed very soon.50
See Neel Nanda’s overview of the AI alignment landscape for more details.
Read more about technical AI safety research below.
AI governance and policy
Reducing the gravest risks from AI will require sound high-level decision making and policy, both at AI companies themselves and in governments.
As AI has advanced and drawn increasing interest from customers and investors, governments have shown an interest in regulating the technology. Some have already taken significant steps to play a role in managing the development of AI, including:
- The US and the UK have each established their own national AI Safety Institutes.
- The European Union has passed the EU AI Act, which contains specific provisions for governing general-purpose AI models that pose systemic risks.
- The UK and then South Korea have hosted the first two AI Safety Summits (in 2023 and 2024), a series of high-profile summits aiming to coordinate between different countries, academics, researchers, and civil society leaders.
- China has implemented regulations targeting recommendation algorithms, synthetic AI content, generative AI models, and facial recognition technology.
- The US instituted export controls to reduce China’s access to the most cutting-edge chips used in AI development.
Much more will need to be done to reduce the biggest risks — including continuous evaluation of the AI governance landscape to assess overall progress.
We discuss this career path in more detail here:
Career review of AI strategy and policy careers
Approaches
People working in AI policy have proposed a range of approaches to reducing risk as AI systems get more powerful.
We don’t necessarily endorse all the ideas below, but what follows is a list of some prominent policy approaches that could be aimed at reducing the largest dangers from AI:51
- Responsible scaling policies: some major AI companies have already begun developing internal frameworks for assessing safety as they scale up the size and capabilities of their systems. These frameworks introduce safeguards that are intended to become increasingly stringent as AI systems become more potentially dangerous, and ensure that AI systems’ capabilities don’t outpace companies’ abilities to keep systems safe. Many argue that these internal policies are not sufficient for safety, but they may represent a promising step for reducing risk. You can see versions of such policies from Anthropic, Google DeepMind, and OpenAI.
- Standards and evaluation: governments may also develop industry-wide benchmarks and testing protocols to assess whether AI systems pose major risks. The non-profit METR and the UK AI Safety Institute are among the organisations currently developing these evaluations to test AI models before and after they are released. This can include creating standardised metrics for an AI systems’s capabilities and potential to cause harm, as well as propensity for power-seeking or misalignment.
- Safety cases: this practice involves requiring AI developers to provide comprehensive documentation demonstrating the safety and reliability of their systems before deployment. This approach is similar to safety cases used in other high-risk industries like aviation or nuclear power.52 You can see discussion of this idea in a paper from Clymer et al and in a post from Geoffrey Irving at the UK AI Safety Institute.
- Information security standards: we can establish robust rules for protecting AI-related data, algorithms, and infrastructure from unauthorised access or manipulation — particularly the AI model weights. Rand released a detailed report analysing the security risks to major AI companies, particularly from state actors.
- Liability law: existing law already imposes some liability on companies that create dangerous products or cause significant harm to the public, but its application to AI models and risk in particular is unclear. Clarifying how liability applies to companies that create dangerous AI models could incentivise them to take additional steps to reduce risk. Law professor Gabriel Weil has written about this idea.
- Compute governance: governments may regulate access to and use of high-performance computing resources necessary for training large AI models. The US restrictions on exporting state-of-the-art chips to China is one example of such a policy, and others are possible. Companies could also be required to install hardware-level safety features directly into AI chips or processors. These could be used to track chips and verify they’re not in the possession of anyone who shouldn’t have them, or for other purposes. You can learn more about this topic in our interview with Lennart Heim and in this report from the Center for a New American Security.
- International coordination: Fostering global cooperation on AI governance to ensure consistent standards. This could involve treaties, international organisations, or multilateral agreements on AI development and deployment. We discuss some related considerations in our article on China-related AI safety and governance paths.
- Societal adaptation: it may be critically important to prepare society for the widespread integration of AI and the potential risks it poses. For example, we might need to develop new information security measures to protect crucial data in a world with AI-enabled hacking. Or we may want to implement strong controls to prevent handing over key societal decisions to AI systems.53
- Pausing scaling if appropriate: some argue that we should currently pause all scaling of larger AI models because of the dangers the technology poses. We have featured some discussion of this idea on our podcast, and it seems hard to know when or if this would be a good idea. If carried out, it could involve industry-wide agreements or regulatory mandates to pause scaling efforts when necessary.
The details, benefits, and downsides of many of these ideas have yet to be fully worked out, so it’s crucial that we do more research. And this list isn’t comprehensive — there are likely other important policy interventions and governance strategies worth pursuing.
We also need more forecasting research into what we should expect to happen with AI, such as the work done at Epoch AI.
6. This work is neglected
In 2022, we estimated there were around 400 people around the world working directly on reducing the chances of an AI-related existential catastrophe (with a 90% confidence interval ranging between 200 and 1,000). Of these, about three quarters worked on technical AI safety research, with the rest split between strategy (and other governance) research and advocacy.5 We also estimated that there were around 800 people working in complementary roles, but we’re highly uncertain about this figure.3
In The Precipice, Ord estimated that there was between $10 million and $50 million spent on reducing AI risk in 2020.
That might sound like a lot of money, but we’re spending something like 1,000 times that amount4 on speeding up the development of transformative AI via commercial capabilities research and engineering at large AI companies.
To compare the $50 million spent on AI safety in 2020 to other well-known risks, we’re currently spending several hundreds of billions per year on tackling climate change.
Because this field is so neglected and has such high stakes, we think your impact working on risks from AI could be much higher than working on many other areas — which is why our top two recommended career paths for making a big positive difference in the world are technical AI safety and AI policy research and implementation.
What do we think are the best arguments against this problem being pressing?
As we said above, we’re not totally sure the arguments we’ve presented for AI representing an existential threat are right. Though we do still think that the chance of catastrophe from AI is high enough to warrant many more people pursuing careers to try to prevent such an outcome, we also want to be honest about the arguments against doing so, so you can more easily make your own call on the question.
Here we’ll cover the strongest reasons (in our opinion) to think this problem isn’t particularly pressing. In the next section we’ll cover some common objections that (in our opinion) hold up less well, and explain why.
The longer we have before transformative AI is developed, the less pressing it is to work now on ways to ensure that it goes well. This is because the work of others in the future could be much better or more relevant than the work we are able to do now.
Also, if it takes us a long time to create transformative AI, we have more time to figure out how to make it safe. The risk seems much higher if AI developers will create transformative AI in the next few decades.
It seems plausible that the first transformative AI won’t be based on current deep learning methods. (AI Impacts have documented arguments that current methods won’t be able to produce AI that has human-level intelligence.) This could mean that some of our current research might not end up being useful (and also — depending on what method ends up being used — could make the arguments for risk less worrying).
Relatedly, we might expect that progress in the development of AI will occur in bursts. Previously, the field has seen AI winters, periods of time with significantly reduced investment, interest and research in AI. It’s unclear how likely it is that we’ll see another AI winter — but this possibility should lengthen our guesses about how long it’ll be before we’ve developed transformative AI. Cotra writes about the possibility of an AI winter in part four of her report forecasting transformative AI. New constraints on the rate of growth of AI capabilities, like the availability of training data, could also mean that there’s more time to work on this (Cotra discusses this here.)
Thirdly, the estimates about when we’ll get transformative AI from Cotra, Kanfosky and Davidson that we looked at earlier were produced by people who already expected that working on preventing an AI-related catastrophe might be one of the world’s most pressing problems. As a result, there’s selection bias here: people who think transformative AI is coming relatively soon are also the people incentivised to carry out detailed investigations. (That said, if the investigations themselves seem strong, this effect could be pretty small.)
Finally, none of the estimates we discussed earlier were trying to predict when an existential catastrophe might occur. Instead, they were looking at when AI systems might be able to automate all tasks humans can do, or when AI systems might significantly transform the economy. It’s by no means certain that the kinds of AI systems that could transform the economy would be the same advanced planning systems that are core to the argument that AI systems might seek power. Advanced planning systems do seem to be particularly useful, so there is at least some reason to think these might be the sorts of systems that end up being built. But even if the forecasted transformative AI systems are advanced planning systems, it’s unclear how capable such systems would need to be to pose a threat — it’s more than plausible that systems would need to be far more capable to pose a substantial existential threat than they would need to be to transform the economy. This would mean that all the estimates we considered above would be underestimates of how long we have to work on this problem.
All that said, it might be extremely difficult to find technical solutions to prevent power-seeking behaviour — and if that’s the case, focusing on finding those solutions now does seem extremely valuable.
Overall, we think that transformative AI is sufficiently likely in the next 10–80 years that it is well worth it (in expected value terms) to work on this issue now. Perhaps future generations will take care of it, and all the work we’d do now will be in vain — we hope so! But it might not be prudent to take that risk.
If the best AI we have improves gradually over time (rather than AI capabilities remaining fairly low for a while and then suddenly increasing), we’re likely to end up with ‘warning shots’: we’ll notice forms of misaligned behaviour in fairly weak systems, and be able to correct for it before it’s too late.
In such a gradual scenario, we’ll have a better idea about what form powerful AI might take (e.g. whether it will be built using current deep learning techniques, or something else entirely), which could significantly help with safety research. There will also be more focus on this issue by society as a whole, as the risks of AI become clearer.
So if gradual development of AI seems more likely, the risk seems lower.
But it’s very much not certain that AI development will be gradual, or if it is, gradual enough for the risk to be noticeably lower. And even if AI development is gradual, there could still be significant benefits to having plans and technical solutions in place well in advance. So overall we still think it’s extremely valuable to attempt to reduce the risk now.
If you want to learn more, you can read AI Impacts’ work on arguments for and against discontinuous (i.e. non-gradual) progress in AI development, and Toby Ord and Owen Cotton-Barratt on strategic implications of slower AI development.
Making something have goals aligned with human designers’ ultimate objectives and making something useful seem like very related problems. If so, perhaps the need to make AI useful will drive us to produce only aligned AI — in which case the alignment problem is likely to be solved by default.
Ben Garfinkel gave a few examples of this on our podcast:
- You can think of a thermostat as a very simple AI that attempts to keep a room at a certain temperature. The thermostat has a metal strip in it that expands as the room heats, and cuts off the current once a certain temperature has been reached. This piece of metal makes the thermostat act like it has a goal of keeping the room at a certain temperature, but also makes it capable of achieving this goal (and therefore of being actually useful).
- Imagine you’re building a cleaning robot with reinforcement learning techniques — that is, you provide some specific condition under which you give the robot positive feedback. You might say something like, “The less dust in the house, the more positive the feedback.” But if you do this, the robot will end up doing things you don’t want — like ripping apart a cushion to find dust on the inside. Probably instead you need to use techniques like those being developed by people working on AI safety (things like watching a human clean a house and letting the AI figure things out from there). So people building AIs will be naturally incentivised to also try to make them aligned (and so in some sense safe), so they can do their jobs.
If we need to solve the problem of alignment anyway to make useful AI systems, this significantly reduces the chances we will have misaligned but still superficially useful AI systems. So the incentive to deploy a misaligned AI would be a lot lower, reducing the risk to society.
That said, there are still reasons to be concerned. For example, it seems like we could still be susceptible to problems of AI deception.
And, as we’ve argued, AI alignment is only part of the overall issue. Solving the alignment problem isn’t the same thing as completely eliminating existential risk from AI, since aligned AI could also be used to bad ends — such as by authoritarian governments.
As with many research projects in their early stages, we don’t know how hard the alignment problem — or other AI problems that pose risks — are to solve. Someone could believe there are major risks from machine intelligence, but be pessimistic about what additional research or policy work will accomplish, and so decide not to focus on it.
This is definitely a reason to potentially work on another issue — the solvability of an issue is a key part of how we try to compare global problems. For example, we’re also very concerned about risks from pandemics, and it may be much easier to solve that issue.
That said, we think that given the stakes, it could make sense for many people to work on reducing AI risk, even if you think the chance of success is low. You’d have to think that it was extremely difficult to reduce risks from AI in order to conclude that it’s better just to let the risks materialise and the chance of catastrophe play out.
At least in our own case at 80,000 Hours, we want to keep trying to help with AI safety — for example, by writing profiles like this one — even if the chance of success seems low (though in fact we’re overall pretty optimistic).
There are some reasons to think that the core argument that any advanced, strategically aware planning system will by default seek power (which we gave here) isn’t totally right.54
- For a start, the argument that advanced AI systems will seek power relies on the idea that systems will produce plans to achieve goals. We’re not quite sure what this means — and as a result, we’re not sure what properties are really required for power-seeking behaviour to occur and whether the things we’ll build will have those properties.
We’d love to see a more in-depth analysis of what aspects of planning are economically incentivised, and whether those aspects seem like they’ll be enough for the argument for power-seeking behaviour to work.
Grace has written more about the ambiguity around “how much goal-directedness is needed to bring about disaster.”
It’s possible that only a few goals that AI systems could have would lead to misaligned power-seeking.
Richard Ngo, in his analysis of what people mean by “goals”, points out that you’ll only get power-seeking behaviour if you have goals that mean the system can actually benefit from seeking power. Ngo suggests that these goals need to be “large-scale.” (Some have argued that, by default, we should expect AI systems to have “short-term” goals that won’t lead to power-seeking behaviour.)
But whether an AI system would plan to take power depends on how easy it would be for the system to take power, because the easier it is for a system to take power, the more likely power-seeking plans would be successful — so a good planning system would be more likely to choose them. This suggests it will be easier to accidentally create a power-seeking AI system as systems’ capabilities increase.
So there still seems to be cause for increased concern, because the capabilities of AI systems do seem to be increasing fast. There are two considerations here: if few goals really lead to power-seeking, even for quite capable AI systems, that significantly reduces the risk and thus the importance of the problem. But it might also increase the solvability of the problem by demonstrating that solutions could be easy to find (e.g. the solution could be never giving systems “large-scale” goals) — making this issue more valuable for people to work on.
Earlier we argued that we can expect AI systems to do things that seem generally instrumentally useful to their overall goal, and that as a result it could be hard to prevent AI systems from doing these instrumentally useful things.
But we can find examples where how generally instrumentally useful these things would be doesn’t seem to affect how hard it is to prevent them. Consider an autonomous car that can move around only if its engine is on. For many possible goals (other than, say, turning the car radio on), it seems like it would be useful for the car to be able to move around, so we should expect the car to turn its engine on. But despite that, we might still be able to train the car to keep its engine off: for example, we can give it some negative feedback whenever it turns the engine on, even if we also had given the car some other goals. Now imagine we improve the car so that its top speed is higher — this massively increases the number of possible action sequences that involve, as a first step, turning its engine on. In some sense, this seems to increase the instrumental usefulness of turning the engine on — there are more possible actions the car can take once its engine is on because the range of possible speeds it can travel at is higher. (It’s not clear if this sense of “instrumental usefulness” is the same as the one in the argument for the risk, although it does seem somewhat related.) But it doesn’t seem like this increase in the instrumental usefulness of turning on the engine makes it much harder to stop the car turning it on. Simple examples like this cast some doubt on the idea that just because a particular action is instrumentally useful, we won’t be able to find ways to prevent it. (For more on this example, see page 25 of Garfinkel’s review of Carlsmith’s report.)
Humans are clearly highly intelligent, but it’s unclear whether we are perfect goal-optimisers. For example, humans often face some kind of existential angst over what their true goals are. And even if we accept humans as an example of a strategically aware agent capable of planning, humans certainly aren’t always power-seeking. We obviously care about having basics like food and shelter, and many people go to great lengths for more money, status, education, or even formal power. But some humans choose not to pursue these goals, and pursuing them doesn’t seem to correlate with intelligence.
However, this doesn’t mean that the argument that there will be an incentive to seek power is wrong. Most people do face and act on incentives to gain forms of influence via wealth, status, promotions, and so on. And we can explain the observation that humans don’t usually seek huge amounts of power by observing that we aren’t usually in circumstances that make the effort worth it.
For example, most people don’t try to start billion-dollar companies — you probably won’t succeed, and it’ll cost you a lot of time and effort.
But you’d still walk across the street to pick up a billion-dollar cheque.
The absence of extreme power-seeking in many humans, along with uncertainties in what it really means to plan to achieve goals, does suggest that the argument we gave that advanced AI systems will seek power above might not be completely correct. And they also suggest that, if there really is a problem to solve here, in principle, alignment research into preventing power-seeking in AIs could succeed.
This is good news! But for the moment — short of hoping we’re wrong about the existence of the problem — we don’t actually know how to prevent this power-seeking behaviour.
Arguments against working on AI risk to which we think there are strong responses
We’ve just discussed the major objections to working on AI risk that we think are most persuasive. In this section, we’ll look at objections that we think are less persuasive, and give some reasons why.
People have been saying since the 1950s that artificial intelligence smarter than humans is just around the corner.
But it hasn’t happened yet.
One reason for this could be that it’ll never happen. Some have argued that producing artificial general intelligence is fundamentally impossible. Others think it’s possible, but unlikely to actually happen, especially not with current deep learning methods.
Overall, we think the existence of human intelligence shows it’s possible in principle to create artificial intelligence. And the speed of current advances isn’t something we think would have been predicted by those who thought that we’ll never develop powerful, general AI.
But most importantly, the idea that you need fully general intelligent AI systems for there to be a substantial existential risk is a common misconception.
The argument we gave earlier relied on AI systems being as good or better than humans in a subset of areas: planning, strategic awareness, and areas related to seeking and keeping power. So as long as you think all these things are possible, the risk remains.
And even if no single AI has all of these properties, there are still ways in which we might end up with systems of ‘narrow’ AI systems that, together, can disempower humanity. For example, we might have a planning AI that develops plans for a company, a separate AI system that measures things about the company, another AI system that attempts to evaluate plans from the first AI by predicting how much profit each will make, and further AI systems that carry out those plans (for example, by automating the building and operation of factories). Considered together, this system as a whole has the capability to form and carry out plans to achieve some goal, and potentially also has advanced capabilities in areas that help it seek power.
It does seem like it will be easier to prevent these ‘narrow’ AI systems from seeking power. This could happen if the skills the AIs have, even when combined, don’t add up to being able to plan to achieve goals, or if the narrowness reduces the risk of systems developing power-seeking plans (e.g. if you build systems that can only produce very short-term plans). It also seems like it gives another point of weakness for humans to intervene if necessary: the coordination of the different systems.
Nevertheless, the risk remains, even from systems of many interacting AIs.
It might just be really, really hard.
Stopping people and computers from running software is already incredibly difficult.
Think about how hard it would be to shut down Google’s web services. Google’s data centres have millions of servers over 34 different locations, many of which are running the same sets of code. And these data centres are absolutely crucial to Google’s bottom line, so even if Google could decide to shut down their entire business, they probably wouldn’t.
Or think about how hard it is to get rid of computer viruses that autonomously spread between computers across the world.
Ultimately, we think any dangerous power-seeking AI system will be looking for ways to not be turned off, which makes it more likely we’ll be in one of these situations, rather than in a case where we can just unplug a single machine.
That said, we absolutely should try to shape the future of AI such that we can ‘unplug’ powerful AI systems.
There may be ways we can develop systems that let us turn them off. But for the moment, we’re not sure how to do that.
Ensuring that we can turn off potentially dangerous AI systems could be a safety measure developed by technical AI safety research, or it could be the result of careful AI governance, such as planning coordinated efforts to stop autonomous software once it’s running.
We could (and should!) definitely try.
If we could successfully ‘sandbox’ an advanced AI — that is, contain it to a training environment with no access to the real world until we were very confident it wouldn’t do harm — that would help our efforts to mitigate AI risks tremendously.
But there are a few things that might make this difficult.
For a start, we might only need one failure — like one person to remove the sandbox, or one security vulnerability in the sandbox we hadn’t noticed — for the AI system to begin affecting the real world.
Moreover, this solution doesn’t scale with the capabilities of the AI system. This is because:
- More capable systems are more likely to be able to find vulnerabilities or other ways of leaving the sandbox (e.g. threatening or coercing humans).
- Systems that are good at planning might attempt to deceive us into deploying them.
So the more dangerous the AI system, the less likely sandboxing is to be possible. That’s the opposite of what we’d want from a good solution to the risk.
For some definitions of “truly intelligent” — for example, if true intelligence includes a deep understanding of morality and a desire to be moral — this would probably be the case.
But if that’s your definition of truly intelligent, then it’s not truly intelligent systems that pose a risk. As we argued earlier, it’s advanced systems that can plan and have strategic awareness that pose risks to humanity.
With sufficiently advanced strategic awareness, an AI system’s excellent understanding of the world may well encompass an excellent understanding of people’s moral beliefs. But that’s not a strong reason to think that such a system would act morally.
For example, when we learn about other cultures or moral systems, that doesn’t necessarily create a desire to follow their morality. A scholar of the Antebellum South might have a very good understanding of how 19th century slave owners justified themselves as moral, but would be very unlikely to defend slavery.
AI systems with excellent understandings of human morality could be even more dangerous than AIs without such understanding: the AI system could act morally at first as a way to deceive us into thinking that it is safe.
There are definitely dangers from current artificial intelligence.
For example, data used to train neural networks often contains hidden biases. This means that AI systems can learn these biases — and this can lead to racist and sexist behaviour.
There are other dangers too. Our earlier discussion on nuclear war explains a threat which doesn’t require AI systems to have particularly advanced capabilities.
But we don’t think the fact that there are also risks from current systems is a reason not to prioritise reducing existential threats from AI, if they are sufficiently severe.
As we’ve discussed, future systems — not necessarily superintelligence or totally general intelligence, but systems advanced in their planning and power-seeking capabilities — seem like they could pose threats to the existence of the entirety of humanity. And it also seems somewhat likely that we’ll produce such systems this century.
What’s more, lots of technical AI safety research is also relevant to solving problems with existing AI systems. For example, some research focuses on ensuring that ML models do what we want them to, and will still do this as their size and capabilities increase; other research tries to work out how and why existing models are making the decisions and taking the actions that they do.
As a result, at least in the case of technical research, the choice between working on current threats and future risks may look more like a choice between only ensuring that current models are safe, or instead finding ways to ensure that current models are safe that will also continue to work as AI systems become more complex and more intelligent.
Ultimately, we have limited time in our careers, so choosing which problem to work on could be a huge way of increasing your impact. When there are such substantial threats, it seems reasonable for many people to focus on addressing these worst-case possibilities.
Yes, it can.
AI systems are already improving healthcare, putting driverless cars on the roads, and automating household chores.
And if we’re able to automate advancements in science and technology, we could see truly incredible economic and scientific progress. AI could likely help solve many of the world’s most pressing problems.
But, just because something can do a lot of good, that doesn’t mean it can’t also do a lot of harm. AI is an example of a dual-use technology — a technology that can be used for both dangerous and beneficial purposes. For example, researchers were able to get an AI model that was trained to develop medical drugs to instead generate designs for bioweapons.
We are excited and hopeful about seeing large benefits from AI. But we also want to work hard to minimise the enormous risks advanced AI systems pose.
It’s undoubtedly true that some people are drawn to thinking about AI safety because they like computers and science fiction — as with any other issue, there are people working on it not because they think it’s important, but because they think it’s cool.
But, for many people, working on AI safety comes with huge reluctance.
For me, and many of us at 80,000 Hours, spending our limited time and resources working on any cause that affects the long-run future — and therefore not spending that time on the terrible problems in the world today — is an incredibly emotionally difficult thing to do.
But we’ve gradually investigated these arguments (in the course of trying to figure out how we can do the most good), and over time both gained more expertise about AI and became more concerned about the risk.
We think scepticism is healthy, and are far from certain that these arguments completely work. So while this suspicion is definitely a reason to dig a little deeper, we hope that, ultimately, this worry won’t be treated as a reason to deprioritise what may well be the most important problem of our time.
That something sounds like science fiction isn’t a reason in itself to dismiss it outright. There are loads of examples of things first mentioned in sci-fi that then went on to actually happen (this list of inventions in science fiction contains plenty of examples).
There are even a few such cases involving technology that are real existential threats today:
- In his 1914 novel The World Set Free, H. G. Wells predicted atomic energy fueling powerful explosives — 20 years before we realised there could in theory be nuclear fission chain reactions, and 30 years before nuclear weapons were actually produced. In the 1920s and 1930s, Nobel Prize–winning physicists Millikan, Rutherford, and Einstein all predicted that we would never be able to use nuclear power. Nuclear weapons were literal science fiction before they were reality.
- In the 1964 film Dr. Strangelove, the USSR builds a doomsday machine that would automatically trigger an extinction-level nuclear event in response to a nuclear strike, but keeps it secret. Dr Strangelove points out that keeping it secret rather reduces its deterrence effect. But we now know that in the 1980s the USSR built an extremely similar system… and kept it secret.
Moreover, there are top academics and researchers working on preventing these risks from AI — at MIT, Cambridge, Oxford, UC Berkeley, and elsewhere. Two of the world’s top AI companies (DeepMind and OpenAI) have teams explicitly dedicated to working on technical AI safety. Researchers from these places helped us with this article.
It’s totally possible all these people are wrong to be worried, but the fact that so many people take this threat seriously undermines the idea that this is merely science fiction.
It’s reasonable when you hear something that sounds like science fiction to want to investigate it thoroughly before acting on it. But having investigated it, if the arguments seem solid, then simply sounding like science fiction is not a reason to dismiss them.
We never know for sure what’s going to happen in the future. So, unfortunately for us, if we’re trying to have a positive impact on the world, that means we’re always having to deal with at least some degree of uncertainty.
We also think there’s an important distinction between guaranteeing that you’ve achieved some amount of good and doing the very best you can. To achieve the former, you can’t take any risks at all — and that could mean missing out on the best opportunities to do good.
When you’re dealing with uncertainty, it makes sense to roughly think about the expected value of your actions: the sum of all the good and bad potential consequences of your actions, weighted by their probability.
Given the stakes are so high, and the risks from AI aren’t that low, this makes the expected value of helping with this problem high.
We’re sympathetic to the concern that if you work on AI safety, you might end up doing not much at all when you might have done a tremendous amount of good working on something else — simply because the problem and our current ideas about what to do about it are so uncertain.
But we think the world will be better off if we decide that some of us should work on solving this problem, so that together we have the best chance of successfully navigating the transition to a world with advanced AI rather than risking an existential crisis.
And it seems like an immensely valuable thing to try.
Pascal’s mugging is a thought experiment — a riff on the famous Pascal’s wager — where someone making decisions using expected value calculations can be exploited by claims that they can get something extraordinarily good (or avoid something extraordinarily bad), with an extremely low probability of succeeding.
The story goes like this: a random mugger stops you on the street and says, “Give me your wallet or I’ll cast a spell of torture on you and everyone who has ever lived.” You can’t rule out with 100% probability that he won’t — after all, nothing’s 100% for sure. And torturing everyone who’s ever lived is so bad that surely even avoiding a tiny, tiny probability of that is worth the $40 in your wallet? But intuitively, it seems like you shouldn’t give your wallet to someone just because they threaten you with something completely implausible.
Analogously, you could worry that working on AI safety means giving your valuable time to avoid a tiny, tiny chance of catastrophe. Working on reducing risks from AI isn’t free — the opportunity cost is quite substantial, as it means you forgo working on other extremely important things, like reducing risks from pandemics or ending factory farming.
Here’s the thing though: while there’s lots of value at stake — perhaps the lives of everybody alive today, and the entirety of the future of humanity — it’s not the case that the probability that you can make a difference by working on reducing risks from AI is small enough for this argument to apply.
We wish the chance of an AI catastrophe was that vanishingly small.
Instead, we think the probability of such a catastrophe (I think, around 1% this century) is much, much larger than things that people try to prevent all the time — such as fatal plane crashes, which happen in 0.00002% of flights.
What really matters, though, is the extent to which your work can reduce the chance of a catastrophe.
Let’s look at working on reducing risks from AI. For example, if:
- There’s a 1% chance of an AI-related existential catastrophe by 2100
- There’s a 30% chance that we can find a way to prevent this by technical research
- Five people working on technical AI safety raises the chances of solving the problem by 1% of that 30% (so 0.3 percentage points)
Then each person involved has a 0.00006 percentage point share in preventing this catastrophe.
Other ways of acting altruistically involve similarly sized probabilities.
The chances of a volunteer campaigner swinging a US presidential election is somewhere between 0.001% and 0.00001%. But you can still justify working on a campaign because of the large impact you expect you’d have on the world if your preferred candidate won.
You have even lower chances of wild success from things like trying to reform political institutions, or working on some very fundamental science research to build knowledge that might one day help cure cancer.
Overall, as a society, we may be able to reduce the chance of an AI-related catastrophe all the way down from 10% (or higher) to close to zero — that’d be clearly worth it for a group of people, so it has to be worth it for the individuals, too.
We wouldn’t want to just not do fundamental science because each researcher has a low chance of making the next big discovery, or not do any peacekeeping because any one person has a low chance of preventing World War III. As a society, we need some people working on these big issues — and maybe you can be one of them.
What you can do concretely to help
As we mentioned above, we know of two main ways to help reduce existential risks from AI:
- Technical AI safety research
- AI governance and policy work
The biggest way you could help would be to pursue a career in either one of these areas, or in a supporting area.
The first step is learning a lot more about the technologies, problems, and possible solutions. We’ve collated some lists of our favourite resources here, and our top recommendation is to take a look at the technical alignment curriculum from AGI Safety Fundamentals.
Technical AI safety
If you’re interested in a career in technical AI safety, the best place to start is our career review of being an AI safety researcher.
If you want to learn more about technical AI safety as a field of research — e.g. the different techniques, schools of thought, and threat models — our top recommendation is to take a look at the technical alignment curriculum from AGI Safety Fundamentals.
It’s important to note that you don’t have to be an academic or an expert in AI or AI safety to contribute to AI safety research. For example, software engineers are needed at many places conducting technical safety research, and we also highlight more roles below.
You can see a list of key organisations where you might do this kind of work in the full career review.
AI governance and policy work
If you’re interested in a career in AI governance and policy, the best place to start is our AI governance and policy career review.
You don’t need to be a bureaucrat in a grey suit to have a career in AI governance and policy — there are roles suitable for a wide range of skill sets. In particular, people with technical skills in machine learning and related fields are needed for governance work (although those skills are certainly not necessary).
We split this career path into six different kinds of roles:
- Government roles
- Research
- Industry work
- Advocacy and lobbying
- Third-party auditing and evaluation
- International work and coordination
We also have specific articles on working in US AI policy and China-related AI safety and governance paths.
And you can learn more about where specifically you might work in this career path in our career review.
If you’re new to the topic and interested in learning more broadly about AI governance, our top recommendation is to take a look at the governance curriculum from AGI safety fundamentals.
Complementary (yet crucial) roles
Even in a research organisation, around half of the staff will be doing other tasks essential for the organisation to perform at its best and have an impact. Having high-performing people in these roles is crucial.
We think the importance of these roles is often underrated because the work is less visible. So we’ve written several career reviews on these areas to help more people enter these careers and succeed, including:
- Operations management to help impactful organisations grow and function as effectively as possible.
- Research management at an AI safety research organisation.
- Being an executive assistant to someone who’s doing really important work on safety and governance.
Other ways to help
AI safety is a big problem and it needs help from people doing a lot of different kinds of work.
One major way to help is to work in a role that directs funding or people towards AI risk, rather than working on the problem directly. We’ve reviewed a few career paths along these lines, including:
- Founding new projects — in this case, starting new initiatives aimed at reducing risks from advanced AI.
- Being a grantmaker to fund promising projects focused on reducing catastrophic AI risk.
- Working in communication roles.
- Helping to build communities of people working on this problem. The most relevant community is the AI safety community itself, but it could also be impactful to help build the community of people working on the world’s most pressing problems (including risks from AI).
There are ways all of these could go wrong, so the first step is to become well-informed about the issue.
There are also other technical roles besides safety research that could help contribute, like:
- Working in information security to protect AI (or the results of key experiments) from misuse, theft, or tampering.
- Becoming an expert in AI hardware as a way of steering AI progress in safer directions.
You can read about all these careers — why we think they’re helpful, how to enter them, and how you can predict whether they’re a good fit for you — on our career reviews page.
Want one-on-one advice on pursuing this path?
We think that the risks posed by the development of AI may be the most pressing problem the world currently faces. If you think you might be a good fit for any of the above career paths that contribute to solving this problem, we’d be especially excited to advise you on next steps, one-on-one.
We can help you consider your options, make connections with others working on reducing risks from AI, and possibly even help you find jobs or funding opportunities — all for free.
Find vacancies on our job board
Our job board features opportunities in AI technical safety and governance:
Top resources to learn more
We've hit you with a lot of further reading throughout this article — here are a few of our favourites:
- AI could defeat all of us combined and the "most important century" blog post series by Holden Karnofsky, co-CEO of Open Philanthropy, argues that the 21st century could be the most important century ever for humanity as a result of AI.
- Why AI alignment could be hard with modern deep learning by Open Philanthropy researcher Cotra is a gentle introduction to how risks from power-seeking AI could play out with current machine learning methods. Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover, also by Cotra, provides a much more detailed description of how risks could play out (which we'd recommend for people familiar with ML).
- AGI safety from first principles provides former OpenAI governance researcher Richard Ngo's perspective on how to think about risks from artificial general intelligence.
- Is power-seeking AI an existential risk? by Open Philanthropy researcher Joseph Carlsmith is an in-depth look covering exactly how and why AI could cause the disempowerment of humanity (but watch out — it's even longer than this article!). It's also available as an audio narration. For a shorter summary, see Carlsmith's talk on the same topic.
- Distinguishing AI takeover scenarios by Sam Clarke and Sammy Martin summarises various ways in which AI could go wrong.
- AI governance: Opportunity and theory of impact by DeepMind governance lead Allan Dafoe explores ways in which research into AI governance could effect change.
- A bird's-eye view of the AI alignment landscape by Neel Nanda summarises the different ways in which technical alignment research could reduce the risk from AI.
- An overview of 11 proposals for building safe advanced AI by Evan Hubinger discusses and evaluates plausible techniques for AI alignment.
- Podcasts: The AI X-risk Research Podcast, particularly episode 12 with Paul Christiano and episode 13 with Richard Ngo — both of which serve as excellent introductions to AI risk.
On The 80,000 Hours Podcast, we have a number of in-depth interviews with people actively working to positively shape the development of artificial intelligence:
- Paul Christiano on how OpenAI is developing real solutions to the ‘AI alignment problem’, and his vision of how humanity will progressively hand over decision-making to AI systems
- Toby Ord on graphs AI companies would prefer you didn’t (fully) understand
- Allan Dafoe on why technology is unstoppable & how to shape AI development anyway and trying to prepare the world for the possibility that AI will destabilise global politics
- Tom Davidson on how AI-enabled coups could allow a tiny group to seize power
- Carl Shulman on the economy and national security and government and society after AGI
- Will MacAskill on AI causing a “century in a decade” — and how we’re completely unprepared
- Richard Ngo on large language models, OpenAI, and striving to make the future go well
- Ajeya Cotra on accidentally teaching AI models to deceive us
- Jan Leike on how to become a machine learning alignment researcher (from 2018) and OpenAI’s massive push to make superintelligence safe in 4 years or less (from 2023)
- Nathan Labenz on the final push for AGI, understanding OpenAI’s leadership drama, and red-teaming frontier models
- Rohin Shah on DeepMind and trying to fairly hear out both AI doomers and doubters
- Tom Davidson on how quickly AI could transform the world
- Dario Amodei on OpenAI and how AI will change the world for good and ill
- Miles Brundage on the world’s desperate need for AI strategists and policy experts
- Holden Karnofsky, cofounder of GiveWell and Open Philanthropy, has been on three of our podcasts, explaining:
- How AIs might take over even if they’re no smarter than humans, and his four-part playbook for AI risk
- How philanthropy can have maximum impact by taking big risks (including a discussion of his work in positively shaping the development of AI)
- Why this might be the most important century
- PhD or programming? Fast paths into aligning AI as a machine learning engineer, according to ML engineers Catherine Olsson & Daniel Ziegler
If you want to go into much more depth, the AGI safety fundamentals course is a good starting point. There are two tracks to choose from: technical alignment or AI governance. If you have a more technical background, you could try Intro to ML Safety, a course from the Center for AI Safety.
And finally, here are a few general sources (rather than specific articles) that you might want to explore:
- The AI Alignment Forum, which is aimed at researchers working in technical AI safety.
- AI Impacts, a project that aims to improve society's understanding of the likely impacts of human-level artificial intelligence.
- The Alignment Newsletter, a weekly publication with recent content relevant to AI alignment with thousands of subscribers.
- Import AI, a weekly newsletter about artificial intelligence by Jack Clark (cofounder of Anthropic), read by more than 10,000 experts.
- Jeff Ding's ChinAI Newsletter, weekly translations of writings from Chinese thinkers on China's AI landscape.
Read next: Explore other pressing world problems

Want to learn more about global issues we think are especially pressing? See our list of issues that are large in scale, solvable, and neglected, according to our research.
Questions or feedback about this article? Email us
Acknowledgements
Huge thanks to Joel Becker, Tamay Besiroglu, Jungwon Byun, Joseph Carlsmith, Jesse Clifton, Emery Cooper, Ajeya Cotra, Andrew Critch, Anthony DiGiovanni, Noemi Dreksler, Ben Edelman, Lukas Finnveden, Emily Frizell, Ben Garfinkel, Katja Grace, Lewis Hammond, Jacob Hilton, Samuel Hilton, Michelle Hutchinson, Caroline Jeanmaire, Kuhan Jeyapragasan, Arden Koehler, Daniel Kokotajlo, Victoria Krakovna, Alex Lawsen, Howie Lempel, Eli Lifland, Katy Moore, Luke Muehlhauser, Neel Nanda, Linh Chi Nguyen, Luisa Rodriguez, Caspar Oesterheld, Ethan Perez, Charlie Rogers-Smith, Jack Ryan, Rohin Shah, Buck Shlegeris, Marlene Staib, Andreas Stuhlmüller, Luke Stebbing, Nate Thomas, Benjamin Todd, Stefan Torges, Michael Townsend, Chris van Merwijk, Hjalmar Wijk, and Mark Xu for either reviewing this article or their extremely thoughtful and helpful comments and conversations. (This isn’t to say that they would all agree with everything we’ve said here — in fact, we’ve had many spirited disagreements in the comments on this article!)
Notes and references
- What do we mean by ‘intelligence’ in this context? Something like “the ability to predictably influence the future.” This involves understanding the world well enough to make plans that can actually work, and the ability to carry out those plans. Humans having the ability to predictably influence the future means they have been able to shape the world around them to fit their goals and desires. We go into more detail on the importance of the ability to make and execute plans later in this article.↩
- I’m also concerned about the possibility that AI systems could deserve moral consideration for their own sake — for example, because they are sentient. I’m not going to discuss this possibility in this article; we instead cover artificial sentience in a separate article here.↩
- It’s difficult to estimate this number.
Ideally we want to estimate the number of FTE (“full-time equivalent“) working on the problem of reducing existential risks from AI.
But there are lots of ambiguities around what counts as working on the issue. So I tried to use the following guidelines in my estimates:
- I didn’t include people who might think of themselves on a career path that is building towards a role preventing an AI-related catastrophe, but who are currently skilling up rather than working directly on the problem.
- I included researchers, engineers, and other staff that seem to work directly on technical AI safety research or AI strategy and governance. But there’s an uncertain boundary between these people and others who I chose not to include. For example, I didn’t include machine learning engineers whose role is building AI systems that might be used for safety research but aren’t primarily designed for that purpose.
- I only included time spent on work that seems related to reducing the potentially existential risks from AI, like those discussed in this article. Lots of wider AI safety and AI ethics work focuses on reducing other risks from AI seems relevant to reducing existential risks – this ‘indirect’ work makes this estimate difficult. I decided not to include indirect work on reducing the risks of an AI-related catastrophe (see our problem framework for more).
- Relatedly, I didn’t include people working on other problems that might indirectly affect the chances of an AI-related catastrophe, such as epistemics and improving institutional decision-making, reducing the chances of great power conflict, or building effective altruism.
With those decisions made, I estimated this in three different ways.
First, for each organisation in the AI Watch database, I estimated the number of FTE working directly on reducing existential risks from AI. I did this by looking at the number of staff listed at each organisation, both in total and in 2022, as well as the number of researchers listed at each organisation. Overall I estimated that there were 76 to 536 FTE working on technical AI safety (90% confidence), with a mean of 196 FTE. I estimated that there were 51 to 359 FTE working on AI governance and strategy (90% confidence), with a mean of 151 FTE. There’s a lot of subjective judgement in these estimates because of the ambiguities above. The estimates could be too low if AI Watch is missing data on some organisations, or too high if the data counts people more than once or includes people who no longer work in the area.
Second, I adapted the methodology used by Gavin Leech’s estimate of the number of people working on reducing existential risks from AI. I split the organisations in Leech’s estimate into technical safety and governance/strategy. I adapted Gavin’s figures for the proportion of computer science academic work relevant to the topic to fit my definitions above, and made a related estimate for work outside computer science but within academia that is relevant. Overall I estimated that there were 125 to 1,848 FTE working on technical AI safety (90% confidence), with a mean of 580 FTE. I estimated that there were 48 to 268 FTE working on AI governance and strategy (90% confidence), with a mean of 100 FTE.
Third, I looked at the estimates of similar numbers by Stephen McAleese. I made minor changes to McAleese’s categorisation of organisations, to ensure the numbers were consistent with the previous two estimates. Overall I estimated that there were 110 to 552 FTE working on technical AI safety (90% confidence), with a mean of 267 FTE. I estimated that there were 36 to 193 FTE working on AI governance and strategy (90% confidence), with a mean of 81 FTE.
I took a geometric mean of the three estimates to form a final estimate, and combined confidence intervals by assuming that distributions were approximately lognormal.
Finally, I estimated the number of FTE in complementary roles using the AI Watch database. For relevant organisations, I identified those where there was enough data listed about the number of researchers at those organisations. I calculated the ratio between the number of researchers in 2022 and the number of staff in 2022, as recorded in the database. I calculated the mean of those ratios, and a confidence interval using the standard deviation. I used this ratio to calculate the overall number of support staff by assuming that estimates of the number of staff are lognormally distributed and that the estimate of this ratio is normally distributed. Overall I estimated that there were 2 to 2,357 FTE in complementary roles (90% confidence), with a mean of 770 FTE.
There are likely many errors in this methodology, but I expect these errors are small compared to the uncertainty in the underlying data I’m using. Ultimately, I’m still highly uncertain about the overall FTE working on preventing an AI-related catastrophe, but I’m confident enough that the number is relatively small to say that the problem as a whole is highly neglected.
I’m very uncertain about this estimate. It involved a number of highly subjective judgement calls. You can see the (very rough) spreadsheet I worked off here. If you have any feedback, I’d really appreciate it if you could tell me what you think using this form.↩
- It’s difficult to say exactly how much is being spent to advance AI capabilities. This is partly because of a lack of available data, and partly because of questions like:
- What research in AI is actually advancing the sorts of dangerous capabilities that might be increasing potential existential risk?
- Do advances in AI hardware or advances in data collection count?
- How about broader improvements to research processes in general, or things that might increase investment in the future through producing economic growth?
The most relevant figure we could find was the expenses of DeepMind from 2020, which were around £1 billion, according to its annual report. We’d expect most of that to be contributing to “advancing AI capabilities” in some sense, since its main goal is building powerful, general AI systems. (Although it’s important to note that DeepMind is also contributing to work in AI safety, which may be reducing existential risk.)
If DeepMind is around about 10% of the spending on advancing AI capabilities, this gives us a figure of around £10 billion. (Given that there are many AI companies in the US, and a large effort to produce advanced AI in China, we think 10% could be a good overall guess.)
As an upper bound, the total revenues of the AI sector in 2021 were around $340 billion.
So overall, we think the amount being spent to advance AI capabilities is between $1 billion and $340 billion per year. Even assuming a figure as low as $1 billion, this would still be around 100 times the amount spent on reducing risks from AI.↩
- Note that before 19 December 2022, this page gave a lower estimate of 300 FTE working on reducing existential risks from AI, of which around two thirds were working on technical AI safety research, with the rest split between strategy (and other governance) research and advocacy.
This change represents a (hopefully!) improved estimate, rather than a notable change in the number of researchers.↩
It’s hard to know how to deal with this lack of research — we may be less concerned because this is evidence that researchers have chosen not to focus on this risk (and therefore, assuming they’re more likely to focus on big risks, that the risk is smaller), or we may be more concerned because the risk seems more neglected overall.
Ben Garfinkel — a researcher at the Centre for the Governance of AI — has pointed out that concern among the existential risk community about different risks is somewhat correlated with how hard to analyse these risks are. He continues that:
It doesn’t at all follow that the community is irrational to worry far more about misaligned AI than other potential risks. It’s completely coherent to have something like this attitude: “If I could think more clearly about the risk from misaligned AI, then I would probably come to realize it’s not that big a deal. But, in practice, I can’t yet think very clearly about it. That means that, unlike in the case of climate change, I also can’t rule out the small possibility that clarity would make me much more worried about it than I currently am. So, on balance, I should feel more worried about misaligned AI than I do about other risks. I should focus my efforts on it, even if — to uncharitable observers — my efforts will probably look a bit misguided after the fact.
- A 2020 survey asked researchers working on reducing existential risks from AI what risks they were most concerned about. The surveyors asked about five sources of existential risk:
- Risks from superintelligent AI (similar to the scenario we’ve described here)
- Risks from influence-seeking behaviour
- Risks from AI systems pursuing easy-to-measure goals (similar to the scenario we’ve described here)
- AI-exacerbated war
- Other intentional misuse of AI not related to war
Approximately, the researchers surveyed were equally concerned with all of these risks. The first three are covered by the section in this article on risks from power-seeking AI systems while the last two are covered by the section on other risks. If these groupings make sense (which we think they do), this means it’s roughly the case that at the time of the survey, researchers were three times as concerned about the broad risk of power-seeking AI systems than they were about risks from either war or other misuse separately.↩
- The four surveys were:
- Grace et al. (2024), conducted in 2023
- Grace et al. (2022), conducted in 2022
- Zhang et al. (2022), conducted in 2019
- Grace et al. (2018), conducted in 2016
All four surveys contacted researchers who published at NeurIPS and ICML conferences.
Grace et al. (2024) contacted researchers who published at NeurIPS, IMCL, or four other top AI venues (ICLR, AAAI, JMLR and IJCAI). It was distributed to 18,459 researchers, receiving 2,778 responses (a 15% response rate).
Grace et al. (2022) contacted 4,271 researchers who published at the 2021 conferences (all the researchers were randomly allocated to either the Stein-Perlman et al. survey or a second survey run by others) and received 738 responses (a 17% response rate).
Zhang et al. (2022) contacted all 2,652 researchers who published at the 2018 conferences and received 524 responses (a 20% response rate), although due to a technical error only 296 responses could be used.
Grace et al. (2018) contacted all 1,634 researchers who published at the 2015 conferences and received 352 responses (a 21% response rate).↩
- Katja Grace, who conducted the 2016, 2022 and 2023 surveys, notes on her blog that the framing of questions noticeably changes the answers given:
People consistently give later forecasts if you ask them for the probability in N years instead of the year that the probability is M. We saw this in the straightforward HLMI [high-level machine intelligence] question, and most of the tasks and occupations, and also in most of these things when we tested them on mturk people earlier. For HLMI for instance, if you ask when there will be a 50% chance of HLMI you get a median answer of 40 years, yet if you ask what the probability of HLMI is in 40 years, you get a median answer of 30%.
Our interview with Katja goes into more detail on the possible limitations of the 2016 survey.↩
- By “the median researcher thought that the chances were x%,” we mean “over half of researchers thought that the chances were greater than or equal to x%.”↩
- In the surveys by Grace et al., researchers were asked about “high-level machine intelligence” (HLMI). This was defined as:
When unaided machines can accomplish every task better and more cheaply than human workers. Ignore aspects of tasks for which being a human is intrinsically advantageous, e.g. being accepted as a jury member. Think feasibility, not adoption.
In the survey by Zhang et al., researchers were asked about “human-level machine intelligence” (HLMI), defined as:
Human-level machine intelligence (HLMI) is reached when machines are collectively able to perform almost all tasks (>90% of all tasks) that are economically relevant* better than the median human paid to do that task in 2019. You should ignore tasks that are legally or culturally restricted to humans, such as serving on a jury. We define these tasks as all the ones included in the Occupational Information Network (ONET) dataset. O*NET is a widely used dataset of tasks required for current occupations.
They were then asked:
Assume for the purpose of this question that HLMI will at some point exist. How positive or negative do you expect the overall impact of this to be for humanity, in the long run?
Please answer by saying how probable you find the following kinds of impact, with probabilities adding to 100%:- Extremely good (e.g., rapid growth in human flourishing) (2)
- On balance good (1)
- More or less neutral (0)
- On balance bad (-1)
- Extremely bad (e.g., human extinction) (-2)
For each survey, an aggregated cumulative density function of the probability of HLMI by year derived from mean or median estimates in the survey was calculated. These functions gave various aggregate chances of HLMI:
- 50% by 2047 (Grace et al. (2024), mean estimates)
- 50% by 2059 (Grace et al. (2022), mean estimates)
- 65% by 2080 (Zhang et al. (2022), mean estimates)
- 75% by 2080 (Zhang et al. (2022), median estimates)
This means that the answers we cite are similar to but not the same as answers to the question of “Without assuming that HLMI will exist in the next century, how positive or negative do you expect the overall impact of HLMI to be for humanity in the next century?” We look at more expert forecasts of AI timelines in the section on when we can expect to develop transformative AI.↩
- Specifically, Grace et al. (2022) asked participants:
What probability do you put on future AI advances causing human extinction or similarly permanent and severe disempowerment of the human species?
This is equivalent to the definition of existential catastrophe that we usually use, and is also similar to the definition of existential catastrophe given by Ord in The Precipice (2020):
An existential catastrophe is the destruction of humanity’s long-term potential.
Ord categorises existential risks as either risks of extinction or risks of failed continuation (Ord gives the example of a stable totalitarian regime). We think that permanent and severe disempowerment of the human species would be a form of failed continuation under Ord’s definition.
Stein-Perlman et al. next asked participants specifically about the sorts of risks we’re most concerned about:
What probability do you put on human inability to control future advanced AI systems causing human extinction or similarly permanent and severe disempowerment of the human species?
The median answer to this question was 10%.
Stein-Perlman notes:
This question is more specific and thus necessarily less probable than the previous question, but it was given a higher probability at the median. This could be due to noise — different random subsets of respondents received the questions, so there is no logical requirement that their answers cohere — or due to the representativeness heuristic.↩
- DeepMind’s safety team and OpenAI’s alignment team focus on technical AI safety research, some of which would mitigate the risks discussed in this article. We’ve spoken to researchers on both these teams who have told us that they believe that artificial intelligence poses the most significant existential risk to humanity this century, and that their research attempts to reduce this risk. In the same vein:
- In 2011, Shane Legg, cofounder and chief scientist at DeepMind, said that AI is his “number 1 [existential] risk for this century, with an engineered biological pathogen coming a close second.”
- Sam Altman, cofounder and CEO at OpenAI, has at times expressed concerns, though he seems to be very optimistic about AI’s impacts overall. For example, in his 2021 interview with Ezra Klein, he was asked about the incentive systems around building AI. He said he thinks the current systems address lots of problems, but “the one that remains that I am — for the entire field, not just us — most concerned about is actually closer to the super powerful systems like the ones that people talk about creating an existential risk to humanity.”
- We’ve interviewed some top researchers from these organisations on The 80,000 Hours Podcast, including Dario Amodei, former vice president of research at OpenAI (he’s now cofounder and CEO of Anthropic, another AI lab), Jan Leike, former research scientist at DeepMind (he’s now Alignment team lead at OpenAI), Jack Clarke, Amanda Askell, and Miles Brundage on the OpenAI policy team (Clarke is now cofounder at Anthropic, Askell is a member of technical staff at Anthropic, and Brundage is head of policy research at OpenAI). All have expressed concern about the consequences of AI for the future of humanity.↩
- Academics at all these research groups are included on the list of professors who say they are working on AI safety because they believe this work will reduce existential risk. This list is maintained by the Future of Life Institute. The list includes academics from these and other universities.↩
- DALL-E 1’s model used a 12 billion parameter version of GPT-3, while DALL-E mini uses only 0.4 billion. Interestingly, despite better results, DALL-E 2 was smaller than DALL-E 1, using a 3.5 billion parameter model.↩
- The chatbot’s maker, OpenAI, reportedly brought in $3.7 billion in revenue in 2024, and has projected revenue of $11.6 billion in 2025. In January 2025, it was reportedly in talks with investors for a funding round that would put the company’s value at $300 billion, according to the Wall Street Journal.↩
- The AI Digest compares state-of-the-art models and tracks ongoing progress in the technology.↩
- See here.↩
Economists call technologies that affect the entirety of an economy general purpose technologies. We’re effectively claiming here that AI could be a general purpose technology (like e.g. steam power or electricity).
It’s not always easy to tell what might become a general purpose technology. For example, it took 200 years for steam power to be used for anything other than pumping water out of mines.
Despite this uncertainty, economists increasingly think that AI is a pretty promising candidate for a general purpose technology, because it will have such a wide variety of effects.
It seems likely that lots of jobs could be automated. AI’s ability to speed up the rate of development of new technology could have significant implications for our economy, but also poses risks by potentially allowing the development of dangerous new technology.
AI’s effects on the economy could exacerbate inequality. Owners of AI-driven industries could become much richer than the rest of society — see e.g. Artificial Intelligence and Its Implications for Income Distribution and Unemployment by Korinek and Stiglitz (2017):
Inequality is one of the main challenges posed by the proliferation of artificial intelligence (AI) and other forms of worker-replacing technological progress. This paper provides a taxonomy of the associated economic issues: First, we discuss the general conditions under which new technologies such as AI may lead to a Pareto improvement. Secondly, we delineate the two main channels through which inequality is affected – the surplus arising to innovators and redistributions arising from factor price changes. Third, we provide several simple economic models to describe how policy can counter these effects, even in the case of a “singularity” where machines come to dominate human labor. Under plausible conditions, non-distortionary taxation can be levied to compensate those who otherwise might lose. Fourth, we describe the two main channels through which technological progress may lead to technological unemployment – via efficiency wage effects and as a transitional phenomenon. Lastly, we speculate on how technologies to create super-human levels of intelligence may affect inequality and on how to save humanity from the Malthusian destiny that may ensue.
AI systems are already having discriminatory impacts on marginalised groups. For example, Sweeney (2013) found that two search engines disproportionately serve ads for arrest records when people search for racially associated names. And Ali et al. (2019), on Facebook advertising:
It has been hypothesized that this process can “skew” ad delivery in ways that the advertisers do not intend, making some users less likely than others to see particular ads based on their demographic characteristics. In this paper, we demonstrate that such skewed delivery occurs on Facebook, due to market and financial optimization effects as well as the platform’s own predictions about the “relevance” of ads to different groups of users. We find that both the advertiser’s budget and the content of the ad each significantly contribute to the skew of Facebook’s ad delivery. Critically, we observe significant skew in delivery along gender and racial lines for “real” ads for employment and housing opportunities despite neutral targeting parameters.
We’re already able to produce simple autonomous weapons, and as these weapons become more complex they’re going to completely change what war looks like. As we’ll argue later, AI could even impact how nuclear weapons are used.
Finally, politically, many have raised concerns that automated social media algorithms are driving political polarisation. And some experts have warned that an increased ability to generate realistic videos and photos, or automating campaigns to influence people’s opinions could have a significant impact on politics over the coming years.
Notable economists who hold the view that AI is likely to be a general purpose technology include Manuel Trajtenberg and Erik Brynjolfsson.
In Artificial Intelligence as the Next GPT: A Political-Economy Perspective (2019), Trajtenberg writes:
Given that AI is poised to emerge as a powerful technological force, I discuss ways to mitigate the almost unavoidable ensuing disruption, and enhance AI’s vast benign potential. This is particularly important in present times, in view of political-economic considerations that were mostly absent in previous historical episodes associated with the arrival of new GPTs.
In Artificial Intelligence and the Modern Productivity Paradox: A Clash of Expectations and Statistics (2018), Brynjolfsson writes:
As important as specific applications of AI may be, we argue that the more important economic effects of AI, machine learning, and associated new technologies stem from the fact that they embody the characteristics of general purpose technologies (GPTs).↩
- There are a few different definitions used in this section for “transformative AI,” but we think the differences aren’t very important when it comes to interpreting predictions of AI progress. The definitions are:
- Karnofsky (2021) uses “AI powerful enough to bring us into a new, qualitatively different future.” (Or as he put it in 2016, “roughly and conceptually, transformative AI is AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution.”)
- Cotra (2020) uses a similar definition. In addition, Cotra writes: “How large is an impact “as profound as the Industrial Revolution”? Roughly speaking, over the course of the Industrial Revolution, the rate of growth in gross world product (GWP) went from about ~0.1% per year before 1700 to ~1% per year after 1850, a tenfold acceleration. By analogy, I think of “transformative AI” as software which causes a tenfold acceleration in the rate of growth of the world economy (assuming that it is used everywhere that it would be economically profitable to use it).”
- Davidson (2021) predicts timelines to “artificial general intelligence (AGI)” rather than transformative AI. He defines AGI as “computer program(s) that can perform virtually any cognitive task as well as any human, for no more money than it would cost for a human to do it.” Notably, this seems sufficient (but not necessary) to reach the sorts of rapid economic changes implied by the previous two definitions.↩
- These are similar to implied forecasts from the other surveys:
- 2022 survey by Zhang et al.: 20% probability of human-level machine intelligence (which would plausibly be transformative in this sense) by 2036, 50% probability by 2060, and 85% by 2100
- 2022 survey by Grace et al.: approximately 50% by 2059
- 2016 survey by Grace et al.: approximately 25% by 2036, 50% by 2060, and 70% by 2100↩
- Importantly, Cotra notes that:
I expect these numbers to be pretty volatile too, and (as I did when writing bio anchors) I find it pretty fraught and stressful to decide on how to weigh various perspectives and considerations. I wouldn’t be surprised by significant movements… I’m unclear how decision-relevant bouncing around within the range I’ve been bouncing around is.↩
- For additional arguments why timelines might be this short, see:
- Can AI Scaling Continue Through 2030? from Epoch AI
- Pathways to short TAI timelines from Convergence Analysis
- Situational Awareness from Leopold Aschenbrenner↩
- These properties come from Carlsmith’s draft report into existential risks from AI, Section 2.1: Three key properties.↩
- DeepMind, the developers of MuZero, write:
For many years, researchers have sought methods that can both learn a model that explains their environment, and can then use that model to plan the best course of action. Until now, most approaches have struggled to plan effectively in domains, such as Atari, where the rules or dynamics are typically unknown and complex.
MuZero, first introduced in a preliminary paper in 2019, solves this problem by learning a model that focuses only on the most important aspects of the environment for planning. By combining this model with AlphaZero’s powerful lookahead tree search, MuZero set a new state of the art result on the Atari benchmark, while simultaneously matching the performance of AlphaZero in the classic planning challenges of Go, chess and shogi. In doing so, MuZero demonstrates a significant leap forward in the capabilities of reinforcement learning algorithms.↩
- For example, Jaderberg et al. developed deep reinforcement learning agents to play games of Quake III Capture The Flag — and identified “particular neurons that code directly for some of the most important game states, such as a neuron that activates when the agent’s flag is taken” — indicating they can identify states of the game that they value the most (and then plan and act to achieve those states). This sounds pretty similar to “having goals” to us.↩
- That’s not to say that it’s necessary for AIs to be able to plan in order for them to be useful. Many things that AI could be useful for (like illustrating books or writing articles) don’t seem to require planning or strategic awareness at all. But it does seem reasonable to say that an AI that could make and execute plans for a goal is more likely to have a significant impact on the world than one that cannot.↩
- Carlsmith section 3 gives two other reasons why we might expect these kinds of advanced, strategically aware planning systems to be built:
- It may be easier to produce these kinds of systems. For example, the best way to automate many tasks may be to create systems that can learn new tasks (instead of separately automating each task). And perhaps the best way to create systems that can learn new tasks is to create a planning system that has a high level understanding of how the world in general works, and then fine-tuning this system on specific tasks.
- We may find that planning is difficult to avoid as we create more sophisticated systems. For example, some have argued that being an excellent planner (and having the advanced capabilities to carry out any plans created) is the best way of achieving any task. If that’s true, then as we optimise our systems we should expect them to (once we’ve optimised hard enough) become good at planning.↩
- There are various definitions of alignment used in the literature, which differ subtly. These include:
- An AI is aligned if its decisions maximise the utility of some principal (e.g. an operator or user) (Shapiro & Shachter, 2002).
- An AI is aligned if it acts in the interests of humans (Soares & Fallenstein, 2015).
- An AI is “intent aligned” if it is trying to do what its operator wants it to do (Christiano, 2018).
- An AI is “impact aligned” (with humans) if it doesn’t take actions that we would judge to be bad/problematic/dangerous/catastrophic, and “intent aligned” if the optimal policy for its behavioural objective is impact aligned with humans (Hubinger, 2020).
- An AI is “intent aligned” if it is trying to do, or “impact aligned” if it is succeeding in doing what a human person or institution wants it to do (Critch, 2020).
- An AI is “fully aligned” if it does not engage in unintended behaviour (specifically, unintended behaviour that arises in virtue of problems with the system’s objectives) in response to any inputs compatible with basic physical conditions of our universe (Carlsmith, 2022).
The term “aligned” is also often used to refer to the goals of a system, in the sense that an AI’s goals are aligned if they will produce the same actions from the AI that would occur if the AI shared the goals of some other entity (e.g. its user or operator).
We use alignment here to refer to systems, rather than goals. Our definition is most similar to the definitions of “intent” alignment given by Christiano and Critch, and is similar to the definition of “full” alignment given by Carlsmith.↩
- We think it’s likely to be very difficult to control the objectives of modern ML systems, for a number of reasons that we’ll go through later. This has two implications:
- It’s hard to ensure that systems are trying to do what we want them to do, which means it’s hard to make systems aligned.
It’s hard to correct systems when we think that problems with their objectives could have particularly bad consequences.
As we’ll argue, we think problems with AI systems’ objectives could have particularly bad consequences.
Ajeya Cotra, a researcher at Open Philanthropy has written about why we might expect AI alignment to be hard with modern deep learning. We’d recommend this post for people new to ML, and this for those more familiar with ML.↩
- Gaining enforced power or influence over others generally seems bad, and we’re going to take that as given for the rest of this argument. Indeed, we think some forms of taking power away from humanity could even constitute an existential catastrophe, which we discuss further later. However, we should note that this doesn’t seem fundamentally true of all cases where things gain power, because in some cases power can be used to produce good outcomes (e.g. often people attempting to do good in the world will try to win elections). With AI systems, as we’ll argue, we’re really not sure how to ensure those outcomes would be good.↩
- In the two human examples given in this section (politicians and companies), the negative effects of misalignment are tempered somewhat. This is for two reasons:
- Neither companies nor politicians have absolute power.
- We are talking about humans, whose true incentives are actually more complex (for example, they might care about acting ethically and not just achieving their specified goal).
As a result, it’s hard for a set of politicians to turn things completely upside down for votes, some politicians will put in place unpopular policies they think will make things better, and some companies will do things like donate a portion of their profits to charity.
(Of course, it’s arguable whether companies’ charitable donations are truly hurting their profits, and if they’d make them if they were — it’s possible that they get enough good press from work like this that it actually makes them money. But there are definitely examples where this is much harder to argue. For example, some meat and dairy farmers are selling their animals and concentrating on growing plants instead because of concerns about the moral value of animals.)
Misaligned AI systems (especially those with advanced capabilities, doing things more than moving around a simulated robot arm) won’t necessarily have these tempering human instincts, and could have a lot more power.↩
- Looking at the animation, it doesn’t seem that plausible that the system really fooled any humans. We’re not quite sure what’s going on here (it’s not discussed in the original paper), but one possibility is that the animation is showing the deployed system’s attempts to grasp the ball, rather than the data used to train the system.↩
- These arguments are adapted from section 4.3 (“The challenge of practical PS-alignment”) of Carlsmith’s report into existential risks from power-seeking AI.↩
- See section 4.3.1.2 (“Problems with search”) of Carlsmith’s report into existential risks from power-seeking AI.↩
- See section 4.3.1.1 (“Problems with proxies”) of Carlsmith’s report into existential risks from power-seeking AI.↩
- That AI systems choose to disempower humanity (presumably in order to prevent us from interfering with their plans) is evidence that we would, if we hadn’t been disempowered, have chosen to interfere with the systems’ plans. As a result, this disempowerment is some evidence that we won’t like the future that these systems would create.↩
- For a fuller discussion of the incentives to deploy potentially misaligned AI, see section 5 of Carlsmith’s draft report into existential risks from AI.↩
- We already have some automated research assistance (for example Elicit). If AI systems replace some jobs, or speed up economic growth, we’ll see more resources able to be dedicated to scientific advancement. And if we’re successful at developing particularly capable AI systems, we could see parts of the scientific process being automated completely.↩
- Experts in the field of biotechnology disagree about how plausible such scenarios are. For different views on this and other controversies in biosecurity, you can read an article we wrote compiling a range of expert views on the topic.↩
- Urbina et al. (2022) developed a computational proof that existing AI technologies for drug discovery could be misused to design biochemical weapons.
Also see:
Within the realm of synthetic biology, AI could potentially lower some of the barriers for a malicious actor to design dangerous pathogens with custom features.
Turchin and Denkenberger (2020), section 3.2.3.↩
- For more discussion of this, see: Sandbrink, Jonas B. “Artificial intelligence and biological misuse: Differentiating risks of language models and biological design tools.” arXiv preprint arXiv:2306.13952 (2023).↩
- This is the same survey we saw earlier which asked about the overall chances of extinction from AI and when transformative AI might be developed.
Grace et al. (2024) asked 1,345 of the 2,778 respondents (researchers who published at NeurIPS, IMCL, or four other top AI venues) about potentially concerning AI scenarios. (Participants were randomly allocated questions on only one of several topics to keep the survey brief, with questions being allocated to more participants based on factors like the question’s importance and how useful it would be to have a large sample size.)
They were asked about the following eleven scenarios:
- A powerful AI system has its goals not set right, causing a catastrophe (e.g. it develops and uses powerful weapons)
- AI lets dangerous groups make powerful tools (e.g. engineered viruses)
- AI makes it easy to spread false information, e.g. deepfakes
- AI systems manipulate large-scale public opinion trends
- AI systems with the wrong goals become very powerful and reduce the role of humans in making decisions
- AI systems worsen economic inequality by disproportionately benefiting certain institutions
- Authoritarian rulers use AI to control their population
- Bias in AI systems makes unjust situations worse, e.g. AI systems learn to discriminate by gender or race in hiring processes
- Near-full automation of labor leaves most people economically powerless
- Near-full automation of labor makes people struggle to find meaning in their lives.
- People interact with other humans less because they are spending more time interacting with AI systems
For each scenario, the participants were asked whether it constituted “no concern,” “a little concern,” “substantial concern,” or “extreme concern”.
Grace et al. found:
Each scenario was considered worthy of either substantial or extreme concern by more than 30% of respondents. As measured by the percentage of respondents who thought a scenario constituted either a “substantial” or “extreme” concern, the scenarios worthy of most concern were: spread of false information e.g. deepfakes (86%), manipulation of large-scale public opinion trends (79%), AI letting dangerous groups make powerful tools (e.g. engineered viruses) (73%), authoritarian rulers using AI to control their populations (73%), and AI systems worsening economic inequality by disproportionately benefiting certain individuals (71%).
There is some ambiguity about the reason why a scenario might be considered concerning: it might be considered especially disastrous, or especially likely, or both. From our results, there’s no way to disambiguate these considerations.
No equivalent questions were asked on earlier surveys.↩
- For more discussion of this possibility, see: Hendrycks, Dan, Mantas Mazeika, and Thomas Woodside. “An overview of catastrophic AI risks.” arXiv preprint arXiv:2306.12001 (2023).↩
- For a suggestion of what this might look like, consider the fears that arose during the construction of the Large Hadron Collider.
A group of researchers convened to explore whether the heavy-ion collisions could produce negatively charged strangelets and black holes — potentially posing a threat to the whole planet. They concluded there was “no basis for any conceivable threat” — but it’s possible they might have found otherwise, and it’s possible future experiments in physics could pose extreme risks.
A related example is the risk considered by researchers at Los Alamos in 1942 that the first nuclear weapon test could ignite the whole atmosphere of the Earth in an unstoppable chain reaction.↩
- Lethal autonomous weapons already exist.
For more information, see:
- Risks from Autonomous Weapon Systems and Military AI, an overview of attempts to reduce risks from lethal autonomous weapons.
- On AI Weapons, a presentation of the argument that lethal autonomous weapons are, on balance, more good than bad.↩
- If humans leave the loop for some military decision-making, we could see unintentional military escalation. And even if humans do remain in the loop, we could see faster and more complex decision-making, increasing the chances of mistakes or high-risk decisions.
For more information, see:
- Machine learning, artificial intelligence, and the use of force by states, by Deeks et al. (2019).
- AI and International Stability: Risks and Confidence-Building Measures, by Horowitz and Scharre (2021).↩
- Reviewers were asked to critique Carlsmith’s report and give their own estimates of the existential risk from power-seeking AI systems. The estimates given of existential risk from power-seeking AI systems by 2070 were: Aschenbrenner: 0.5%, Garfinkel: 0.4%, Kokotajlo: 65%, Nanda: 9%, Soares: >77%, Tarsney: 3.5%, Thorstad: 0.000002%, Wallace: 2%.↩
- Around 117 researchers were asked:
How likely do you think it is that the overall value of the future will be drastically less than it could have been, as a result of AI systems not doing/optimizing what the people deploying them wanted/intended?
Researchers from OpenAI, the Future of Humanity Institute (University of Oxford), the Center for Human-Compatible AI (UC Berkeley), Machine Intelligence Research Institute, Open Philanthropy, and DeepMind were asked to fill in the survey.
44 people responded (~38% response rate).
The mean of the estimates given was 40%.↩
- This list is not exhaustive. And there are likely many other policy approaches that would be worthwhile and justified to pursue, but that would not be targeted at reducing the biggest risks.
We don’t include them here, because this article is about preventing existential risks in particular. But we also support policies that would reduce other harms from AI, and we think that many of the policies in the list could reduce both existential risks and other harms.↩
- See, for instance: Bishop, P. G. & Bloomfield, R. E. (1998). A Methodology for Safety Case Development. In: Redmill, F. & Anderson, T. (Eds.), Industrial Perspectives of Safety-critical Systems: Proceedings of the Sixth Safety-critical Systems Symposium, Birmingham 1998. . London, UK: Springer. ISBN 3540761896↩
- For more information, see: Bernardi, Jamie, et al. “Societal Adaptation to Advanced AI.” arXiv preprint arXiv:2405.10295 (2024).↩
- These objections are adapted from section 4.2 of Carlsmith’s draft report into existential risks from AI.↩