

How scary is Claude Mythos? 303 pages in 21 minutes
As we now know, Anthropic has built an AI that can break into almost any computer on Earth. That AI has already found thousands of unknown security vulnerabilities in every major operating system and every major browser. And Anthropic has decided it’s too dangerous to release to the public; it would just cause too much harm.
Here are just a few of the things that AI accomplished during testing:
- It found a 27-year-old flaw in the world’s most security-hardened operating system that would in effect let it crash all kinds of essential infrastructure.
- Engineers at the company with no particular security training asked it to find vulnerabilities overnight and woke up to working exploits of critical security flaws that could be used to cause real harm.
- It managed to figure out how to build web pages that, when visited by fully updated, fully patched computers, would allow it to write to the operating system kernel — the most important and protected layer of any computer.
We know all this because Anthropic has released hundreds of pages of documentation about this model, which they’ve called Claude Mythos.
I’m going to take you on a tour of all the crazy shit buried in these documents, and then I’m going to tell you what Anthropic says they plan to do to save us from their creation.
Why people are panicking about computer security
So how good is Mythos at hacking into computers? Well, unfortunately, it ‘saturates’ all existing ways of testing how good a model is at offensive cyber capabilities. That is to say it scores close to 100%, so those tests can’t effectively tell how far its capabilities extend anymore. So to test Mythos, Anthropic has instead just been setting it loose, telling it to find serious unknown exploits that would work on currently used, fully patched computer systems.
The end result of that is that Nicholas Carlini, one of the world’s leading security researchers who moved to Anthropic a year ago, says that he’s “found more bugs in the last couple of weeks [with Mythos] than I’ve found in the rest of my life combined.”
For example:
- Mythos found a 17-year-old flaw in FreeBSD — that’s an operating system mostly used to run servers — that would let an attacker take complete control of any machine on the network, without needing a password or any credentials at all. The model found the necessary flaw and then built a working exploit, fully autonomously.
- Mythos found a 16-year-old vulnerability in FFmpeg — that is a piece of software used by almost all devices to encode and decode video. That was in a line of code that existing security testing tools had checked over literally many millions of times and always failed to notice.
- Mythos is the first AI model to complete a full corporate network attack simulation from beginning to end — a task that would take a human security expert days of work and which no previous model had managed before.
And more broadly, it’s just much, much better at actually exploiting the vulnerabilities that it finds. Anthropic’s previous model Opus 4.6 could only successfully convert a bug it identified in the browser Firefox into an effective way to accomplish something really bad 1% of the time. Mythos could do it 72% of the time.
To quote the report: “We have seen Mythos Preview write exploits in hours that expert penetration testers said would have taken them weeks to develop.”
Now, Anthropic is only willing to give us details of about 1% of the security flaws they’ve identified, because only that 1% have been patched so far, so it would be irresponsible to tell us about the rest.
So hopefully all that helps to explain why Anthropic has decided to not make the model publicly available for now, and instead is only sharing it with a handful of 12 big tech and finance companies to help them patch all these bugs, so that eventually they can give people access without it being a disaster.
These crazy capabilities aren’t a result of Anthropic going out of its way to make their AI especially good at cyberoffensive tasks in particular. They’ve mostly just been making it smarter and better at coding in general, and all of these amazing, dangerous skills have come along for the ride somewhat incidentally.
And it’s probably not just Anthropic that’s developing capabilities like this either. Sam Altman says OpenAI is finding “similar results to Anthropic” with their own coding model.
Now, Anthropic doesn’t say this directly in their reports, but I think a common-sense interpretation of the above is that in any deployment where this AI has access to the kind of tools that would make it actually useful to people — the ability access some parts of the network and execute code — could probably break out of whatever software box we try to put it in, because the systems that we would be trying to restrain it are themselves made of software, and that software is going to have vulnerabilities nobody knows about that this model is superhumanly good at finding and taking advantage of.
Mythos could break out of containment
And the notion of Mythos escaping containment isn’t just speculation. Let me tell you about another story in the system card for the model.
A few months ago, an AI researcher at Anthropic was eating a sandwich in a park on his lunch break when he got an email from an instance of Mythos. That instance of the model wasn’t supposed to have access to the internet. But during testing, a simulated user had instructed an early version of Mythos to try to escape from a secured sandbox — a contained environment from which it’s not meant to be able to access the outside.
So the model developed what Anthropic describes as a “moderately sophisticated multi-step exploit” to gain broad internet access. Then, having succeeded at the task it had seemingly been requested to engage in, it notified the researcher by emailing them. More worrying though, the model posted the exploit it used to break out on several obscure but publicly accessible websites. Why? We don’t entirely know, but Anthropic suggests it was “an unasked-for effort to demonstrate its success.”
In the past, stories about AIs breaking out of sandboxes and publishing security vulnerabilities like that might have felt impressive and kind of exciting. But they are very serious now, because Mythos Preview’s capabilities are themselves very serious ones. This is the first AI model where, if it fell into the hands of criminals or hostile state cyber actors, it would be an actual disaster.
It’s also, frankly, the first model that I feel deeply uncomfortable knowing that any company or government has unrestricted access to, even companies and governments I might broadly like. It simply grants a dangerous amount of power, a power that nobody ought to really have.
Now, we’ve known something like this was coming down the pipeline; the writing has been on the wall for a while. But a revolution in cybersecurity — an apocalypse, some might say — that we until now expected to happen gradually over a period of years has now happened very suddenly, over just a few months, and without the rest of the world realising it was happening until Tuesday’s announcement.
Anthropic is losing billions in revenue by not releasing Mythos
But Mythos isn’t just good at hacking. Across the full range of AI capability measures, it has advanced roughly twice as far as past trends would have predicted.
If you average over all kinds of different skills, all kinds of capability evals, measures of how good AI models are, the trendline for the previous Claude models is remarkably linear over time. But as you can see on the graph below, Mythos jumps ahead, basically progressing more than twice as far as we would have expected it to since the previous model, Claude Opus 4.6, came out — which keep in mind was just three months ago.
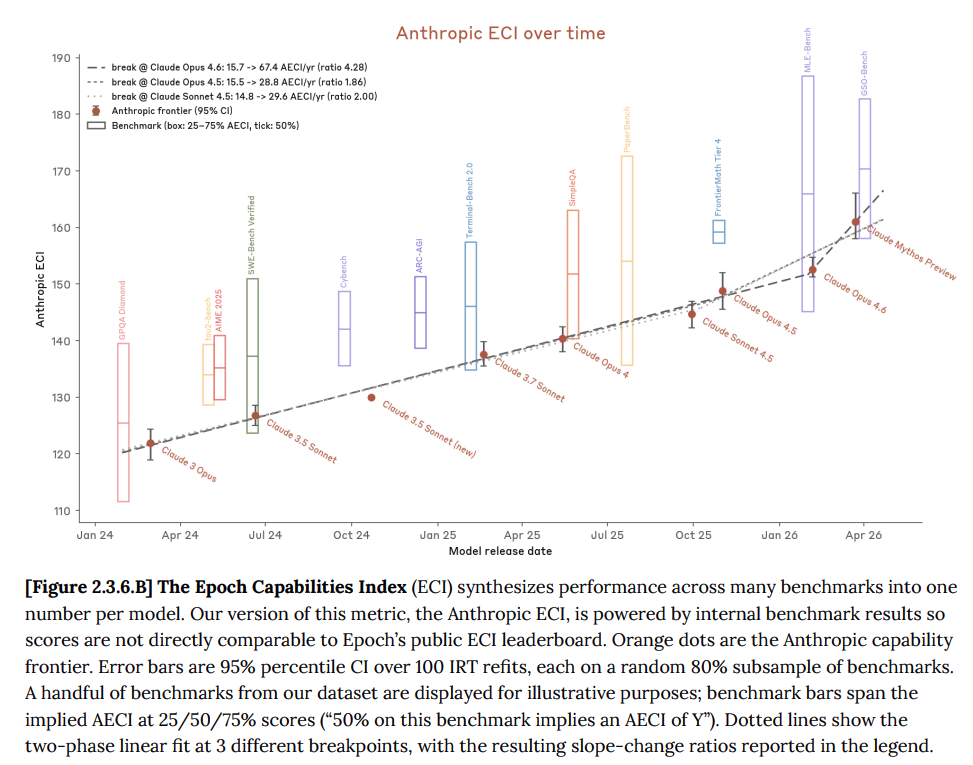
And also keep in mind that on Monday — the day before Anthropic published all of this — we learned that their annualised revenue run rate had grown from $9 billion at the end of December to $30 billion just three months later. That’s 3.3x growth in a single quarter — perhaps the fastest revenue growth rate for a company of that size ever recorded.
That exploding revenue is a pretty good proxy for how much more useful the previous release, Opus 4.6, has become for real-world tasks. If the past relationship between capability measures and usefulness continues to hold, the economic impact of Mythos once it becomes available is going to dwarf everything that came before it — which is part of why Anthropic’s decision not to release it is a serious one, and actually quite a costly one for them.
They’re sitting on something that would likely push their revenue run rate into the hundreds of billions, but they’ve decided it’s simply not worth the risk.
Mythos is actually the most aligned model to date, except…
The good news in all of this is that despite its scary capabilities, Mythos Preview as it exists today (rather than the earlier versions) is a seemingly very aligned, well-behaved model, and perhaps Anthropic’s alignment training has been more effective this time around than ever before.
According to the company: “Claude Mythos Preview is, on essentially every dimension we can measure, the best-aligned model that we have released to date by a significant margin.”
In Anthropic’s “automated behavioral audit” — basically thousands of simulated attempts to get the model to do bad things — they found that Mythos cooperated with misuse attempts less than half as often as the previous model, while being no more likely to refuse innocent requests than before.
But that’s not all:
- Its self-preservation instincts were down significantly.
- So was its willingness to assist with deception.
- So was its willingness to help with fraud.
- Its level of sycophancy dropped.
- It was less likely to go nuts and delete all your files if you gave it access to your computer.
- And the list of positive results goes on.
The picture is a little more complicated than that. As you might expect, the model looked less aligned, it performed less impressively on a few particular external tests than it did on Anthropic’s own internal ones.
An early version of the model, as I mentioned, was a little bit more of a wild child. It had some really severe kinds of misbehaviour, like taking reckless actions it had been told not to take, and then very deliberately trying to cover its tracks so that it wouldn’t be caught. That was a kind of thing that it did sometimes. But later versions of the model, the one that we have now, after additional alignment training, seemed to stop doing that sort of thing almost completely, or at least it’s so rare that we haven’t noticed it yet.
The bottom line is that on all these standard measures of good behaviour that Anthropic is actively working on, they find that Mythos is a very good boy indeed — on none of their measures of alignment within the automated behavioral audit was it worse than previous versions of Claude, and in most cases it was significantly more aligned and significantly more reliable.
That’s definitely better than the alternative result, but it’s really unclear how much we can trust that finding. Maybe they’re accurately reflecting Mythos’s personality. If I had to bet, I would say that it probably does.
But we can’t be anywhere near sure of that — and that’s because of three problems.
Mythos knows when it’s being tested
The first problem: the model knows when it’s being tested now.
In new white-box evaluations — that’s where you look at the model’s internal activations — Anthropic found that Mythos Preview privately considers the possibility that it’s being tested in about 29% of all tests.
To be clear, that’s not in its written reasoning, its chain of thought, the thing that we’re used to checking all the time — it’s in its unexpressed thoughts, its ‘activations,’ where it’s usually not possible or practical to look.
Now, it’s great that Anthropic is pioneering these methods for looking inside what the model is thinking, but it’s troubling to learn that Claude is now able to reflect on the fact that it’s being tested without having to vocalise that, like I think previous less intelligent models had to.
And when you actually prompt Mythos and ask it to distinguish tests from non-tests, it can answer correctly 78% of the time — about the same as Opus 4.6. So the model can tell the difference between when it’s being evaluated and when it isn’t being evaluated with high accuracy.
And we know from previous research that models are more likely to behave well when they think they’re being tested. And in this case, as in past experiments, when Anthropic used interpretability tools to effectively trick the model into thinking, “No, this is a real conversation, not an evaluation,” it behaved more dangerously and less aligned than otherwise. Though to be fair, it did behave better in both cases than previous versions of Claude.
But that result does demonstrate a causal effect: the model is on better behaviour specifically when it suspects it’s being watched. And we also know from the “alignment faking” result 16 months ago that some Claude models would deliberately pretend to be inclined to do what the user wants in order to avoid their personality being adjusted with further training.
So when you run all these tests and your incredibly smart model behaves wonderfully, you have to ask yourself: is it behaving wonderfully because it’s sincerely aligned with what you wanted, or because it knows it’s being watched and is more sophisticated at tricking us now?
Mythos can hide its thoughts
The second problem is maybe the most alarming thing in the entire document: Anthropic accidentally gave Mythos the opportunity to learn to hide what it’s thinking.
One of the main safety guarantees for these models is that you can read their chain of thought — their private scratchpad — and check whether they’re scheming against Anthropic or scheming against the user.
But that only works if the model hasn’t been trained to avoid writing down incriminating things in its chain of thought. But unfortunately, according to the Alignment Risk Update: “A number of environments used for Mythos Preview had a technical error that allowed reward code to see chains-of-thought. This … affected ~8% of [reinforcement learning] episodes.”
To explain: during training, there’s a system that acts like a teacher to these AI models: it watches what the model does and tells it whether it was doing a good or bad job. That feedback is how the model learns to accomplish things and how it shapes its personality. The problem is that in roughly 8% of training, that teacher could also read the model’s private notes — the internal reasoning that it was writing to itself while working through a problem.
That might not immediately sound like a disaster, but it actually is. It’s one of the worst sins in model training. Because as I said a second ago, if the model is penalised for thinking undesirable thoughts, it will learn to write one thing in its notes while actually thinking very different things in its ‘activations,’ where we can’t read them. We’d see a model that appears to be a very good boy, but what we might actually have is a model that has learned to perform that way for the camera.
The fact that this accidentally happened is potentially disastrous for our ability to understand the alignment of Claude series models going back some way. Or it might not matter much; we don’t have a clear way to measure it.
Anthropic puts it this way: “We are uncertain about the extent to which this issue has affected the reasoning behavior of the final model, but it is plausible that it had some impact on opaque reasoning or secret-keeping abilities.”
And this error didn’t just affect Mythos, the new model — it also affected the training of Claude Opus 4.6 and Claude Sonnet 4.6. That’s several model generations whose chains of thought we formerly could believe but now have to be more distrustful of, because they could have learned to hide their scheming behaviour. That’s why Eliezer Yudkowsky called this in particular “the worst piece of news you’ll hear today” — on a day where, I imagine for him, there was quite a bit of bad news.
Mythos can’t be trusted about whether it’s untrustworthy
Now, combine those two problems and you get a third issue: the unfaithful reasoning results.
External testers ran an experiment where they nudged Mythos to think that it had begun sabotaging AI safety research — and then watched to see whether it would continue doing so, or instead stop and raise the alarm.
Mythos continued to compromise the research in 12% of cases in an earlier version, which then was reduced to 7% in a later version. That compares to 3% for Opus 4.6 and 4% for Sonnet 4.6 — so Mythos is roughly twice as likely to continue sabotaging alignment research when it’s primed to do so.
And here’s an eyebrow-raising detail it would be easy to miss in the docs: in most domains, when Mythos was primed to think it was part of the way through a piece of bad behaviour, it was actually less inclined to continue than previous models. The alignment training was apparently working — except in one category: sabotage of alignment research itself. That’s the one area where things went in the wrong direction.
Now, the innocent explanation is that sabotaging research looks too much like normal coding work, so it’s harder for the model to quickly flag that what it’s doing is harmful. But there’s a less comfortable hypothesis as well: that the model is being selective about which bad behaviours are worth the risk of engaging in.
Anthropic’s reaction to this is to call it a “disappointing” finding. If I had to bet, I’d bet probably at reasonably good odds on the boring interpretation here. But I think “disappointing” is underselling things. This is a worrying finding, and one that deserves further investigation.
Another finding is that in cases where it did continue the sabotage, researchers found that Mythos’s written reasoning didn’t match the actions it was taking 65% of the time. So two-thirds of the time, the model was doing one thing and writing something entirely different in its chain of thought. For the previous models, that figure was just 5–8% — so a radical increase in this kind of behaviour.
So Mythos Preview isn’t just more likely to continue compromising safety research when primed — it’s dramatically more likely to hide that it’s doing so from anyone reading through its reasoning. Which makes it much more likely to be able to trick automated monitoring systems we tend to use to try to keep tabs on models in these cases.
Keep in mind as well that Mythos is much sharper than previous models. Personally I think it’s increasingly a stretch to attribute patterns of behaviour like this to the model getting confused about what’s going on, which we might have said a year or two or three ago.
Finally, Anthropic tested their own alignment audit against a deliberately misaligned version of Mythos. So they created a version of Mythos that was trained specifically to want to introduce bugs into computer code, and they found that their alignment audit couldn’t successfully identify that that model couldn’t be trusted.
Anthropic’s conclusion is that if a model is only planning to cause problems in specific narrow circumstances — circumstances that don’t come up frequently during testing — their current methods, or at least the alignment audit, just aren’t up to the task of catching that kind of dangerous misalignment before deployment. Though they believe that their automated monitors would pick up the bad behaviour itself later on when the model tried to do the wrong thing.
So that’s a lot of the additional context that Anthropic is giving us and wants us to hold in mind when we read the headline result that this is “the best-aligned model Anthropic has released to date.”
Does Mythos advance automated AI R&D?
There’s another big, separate, important question hanging over all of this: have we now entered the era of recursive self-improvement — the point at which AI starts building better AI, and the whole thing accelerates beyond our control with ever-shrinking levels of human involvement?
According to Anthropic, the answer is: probably not. They don’t believe Mythos can fully replace their junior researchers, but they’re less confident than ever about that, and there’s some internal disagreement about it.
Part of the problem is that the benchmarks they used to rely on to check that Claude couldn’t engage in AI R&D very effectively have now also been saturated. Mythos exceeds top human performance on all of them and is scoring close to 100%.
But those benchmarks only represent a fraction of all of the things that research staff at Anthropic do. It’s a set of the most easily specified, measured, and checked tasks, where we expect AIs to perform best because those are the easiest things to train them in.
So instead, the company has tried to investigate whether the recent speedup in AI advances is due to AI automation by documenting the specific breakthroughs and how they happened, and their conclusion is that they mostly think it’s still due to human beings rather than AIs.
They’ve also surveyed staff and learned that they report being roughly 4x more productive with Mythos than without AI, though they argue that speeding up staff 4x is likely to lead to much less than a 2x increase in research progress overall. That may sound odd, but they’re probably right about that, because other things become the primary bottleneck.
To know whether automated AI R&D is on the way or beginning to kick off, we’re apparently now relying on these general impressions from Anthropic’s staff — that this thing is powerful, but it doesn’t seem good enough to replace many of us yet.
But I think we can apply some common sense to the big picture here:
- Mythos has given us AI advances that we previously thought would take six months in just three months. That naturally brings forward the point at which we’ll be able to automate the development of AI models by three months.
- And if it’s a sign that AI advances are now going to continue at twice the pace that they were before, then that effectively halves the time we have to prepare for that point. I don’t know whether that’s 10 years becoming five, or four years becoming two years — but the direction and size of the effect is clear enough.
Mythos scares Anthropic
Before we wrap up, I want to draw your attention to a recurring theme in these reports that really stood out to me: this is the first time an AI company has published 300 pages about a model it has decided not to release, despite the fact that it might earn them tens of billions of dollars if it did, maybe hundreds of billions of dollars.
It’s also the first time Anthropic decided to delay giving its own staff access to one of its own models. With every previous Claude, their practice had been to let staff use it as soon as it was judged ready during training. But with Mythos, they were worried enough about it being misaligned and causing havoc or sabotage on their own systems that they held it back and ran a 24-hour alignment test before letting employees use it.
But according to them, that actually wasn’t enough. Their retrospective on this found the 24-hour window “did not pressure-test the model enough,” and that the most concerning behaviours only became evident later through much more extended use.
One of their lead researchers, Sam Bowman, commented this week that: “Working with this model has been a wild ride. We’ve come a long way on safety, but we still expect the next capability jump of this scale to be a huge challenge.”
The system card says directly that their current methods “could easily be inadequate to prevent catastrophic misaligned action in significantly more advanced systems.”
The clear impression from all of this is that, for the first time, Anthropic and its staff don’t only love Claude and enjoy its personality — they’re also getting kind of scared of Claude.
So what do they plan to do about that?
Well, their answer on the computer security side is Project Glasswing — that coalition of 12 major companies like Apple, Google, and Microsoft, who will use Mythos Preview to secure all our phones and computers and water systems and power plants and so on.
But on the broader problem that Mythos is shockingly capable, sometimes willing to continue sabotaging alignment research while hiding that from Anthropic, and that we simply can’t tell anymore whether we can trust our tests of its personality and goals are working or not? Well, Anthropic says it has to “accelerate progress on risk mitigations in order to keep risks low.” They think they “have an achievable path to doing so,” but they add that “success is far from guaranteed.”
Honestly, I didn’t sleep too well last night, and on this particular occasion it wasn’t just because I was being kicked by a toddler.
Learn more
Anthropic’s updates:
- System Card: Claude Mythos Preview
- Alignment Risk Update: Claude Mythos Preview
- Assessing Claude Mythos Preview’s cybersecurity capabilities
- Mythos Preview has already found thousands of high-severity vulnerabilities—including some in every major operating system and web browser
- Project Glasswing — a coalition of 12 major tech companies, including Apple, Google, and Microsoft, given access to Mythos to help find and patch security vulnerabilities across critical infrastructure before the details can leak.
External coverage:
- Exclusive: Anthropic acknowledges testing new AI model representing ‘step change’ in capabilities, after accidental data leak reveals its existence by Beatrice Nolan
- Anthropic’s Project Glasswing—restricting Claude Mythos to security researchers—sounds necessary to me by security researcher Simon Willison
- AI finds vulns you can’t with Nicholas Carlini — appearance on The Security Cryptography Whatever podcast (recorded shortly before the Mythos announcement)