US policy master’s degrees



Our new book, a ridiculously in-depth guide to a fulfilling career, is out May 2026. Preorder now

The idea this week: switching careers can be terrifying — but it can also be the key to finding more satisfying and impactful work.
Trust me — I’ve tested my fit for at least four different career paths before landing where I am now. After a first job in teaching, I explored:
When I graduated from university with a degree in philosophy, I didn’t know what to do next, but I knew I wanted to find a job that helped others and wasn’t harmful. I looked for roles at nonprofits nearby and ended up getting hired at a special education school.
I loved many parts of the job and the students I worked with, but when the opportunity arose to get my master’s in special education, I realised I didn’t envision spending my whole career in the field. I had gotten involved with local vegan advocacy and an effective altruism group, and I was curious if there were even more impactful opportunities I could pursue with my career.
I once thought that most of my impact would come through donating — but a lot of the people I was talking to were discussing the idea that career choice could be even more impactful than charitable giving (especially since teaching wasn’t particularly lucrative in my case).

In today’s episode, host Luisa Rodriguez interviews economist Michael Webb of DeepMind, the British Government, and Stanford about how AI progress is going to affect people’s jobs and the labour market.
They cover:
If you’d like to work with Michael on his new org to radically accelerate how quickly people acquire expertise in critical cause areas, he’s now hiring! Check out Quantum Leap’s website.
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript.
Producer and editor: Keiran Harris
Audio Engineering Lead: Ben Cordell
Technical editing: Simon Monsour and Milo McGuire
Additional content editing: Katy Moore and Luisa Rodriguez
Transcriptions: Katy Moore

In today’s episode, host Luisa Rodriguez interviews the head of research at Our World in Data — Hannah Ritchie — on the case for environmental optimism.
They cover:
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript.
Producer and editor: Keiran Harris
Audio Engineering Lead: Ben Cordell
Technical editing: Milo McGuire and Dominic Armstrong
Additional content editing: Katy Moore and Luisa Rodriguez
Transcriptions: Katy Moore

The idea this week: how I learned a lot about my skills by testing my fit for operations work.
Like a lot of students, I spent much of my final year at university unsure what to do next. Should I pursue further studies, start out on a career path, or something else?
I was excited about having an impact with my career, and I thought I might be a good fit for policy work — which seemed like a way I could contribute to solving pressing world problems. I figured this would involve further studies, so I looked into applying for graduate school.
But I was probably deferring too much to my sense of what others thought would be high-impact work, rather than figuring out how I could best contribute over the course of my career. I ended up doing the 80,000 Hours career planning worksheet — and it helped me to generate a longer list of options and questions.
It pointed me toward something I hadn’t considered: doing something that would help me test my fit for lots of different kinds of work.

In July, OpenAI announced a new team and project: Superalignment. The goal is to figure out how to make superintelligent AI systems aligned and safe to use within four years, and the lab is putting a massive 20% of its computational resources behind the effort.
Today’s guest, Jan Leike, is Head of Alignment at OpenAI and will be co-leading the project. As OpenAI puts it, “…the vast power of superintelligence could be very dangerous, and lead to the disempowerment of humanity or even human extinction. … Currently, we don’t have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue.”
Given that OpenAI is in the business of developing superintelligent AI, it sees that as a scary problem that urgently has to be fixed. So it’s not just throwing compute at the problem — it’s also hiring dozens of scientists and engineers to build out the Superalignment team.
Plenty of people are pessimistic that this can be done at all, let alone in four years. But Jan is guardedly optimistic. As he explains:
Honestly, it really feels like we have a real angle of attack on the problem that we can actually iterate on… and I think it’s pretty likely going to work, actually. And that’s really, really wild, and it’s really exciting. It’s like we have this hard problem that we’ve been talking about for years and years and years, and now we have a real shot at actually solving it. And that’d be so good if we did.
Jan thinks that this work is actually the most scientifically interesting part of machine learning. Rather than just throwing more chips and more data at a training run, this work requires actually understanding how these models work and how they think. The answers are likely to be breakthroughs on the level of solving the mysteries of the human brain.
The plan, in a nutshell, is to get AI to help us solve alignment. That might sound a bit crazy — as one person described it, “like using one fire to put out another fire.”
But Jan’s thinking is this: the core problem is that AI capabilities will keep getting better and the challenge of monitoring cutting-edge models will keep getting harder, while human intelligence stays more or less the same. To have any hope of ensuring safety, we need our ability to monitor, understand, and design ML models to advance at the same pace as the complexity of the models themselves.
And there’s an obvious way to do that: get AI to do most of the work, such that the sophistication of the AIs that need aligning, and the sophistication of the AIs doing the aligning, advance in lockstep.
Jan doesn’t want to produce machine learning models capable of doing ML research. But such models are coming, whether we like it or not. And at that point Jan wants to make sure we turn them towards useful alignment and safety work, as much or more than we use them to advance AI capabilities.
Jan thinks it’s so crazy it just might work. But some critics think it’s simply crazy. They ask a wide range of difficult questions, including:
In today’s interview host Rob Wiblin puts these doubts to Jan to hear how he responds to each, and they also cover:
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer and editor: Keiran Harris
Audio Engineering Lead: Ben Cordell
Technical editing: Simon Monsour and Milo McGuire
Additional content editing: Katy Moore and Luisa Rodriguez
Transcriptions: Katy Moore

The idea this week: AI governance careers present some of the best opportunities to change the world for the better that we’ve found.
Last week, US Senator Richard Blumenthal gave a stark warning during a subcommittee hearing on artificial intelligence.
He’s become deeply concerned about the potential for an “intelligence device out of control, autonomous, self-replicating, potentially creating diseases, pandemic-grade viruses, or other kinds of evils — purposely engineered by people, or simply the result of mistakes, no malign intention.”
We’ve written about these kinds of dangers — potentially rising to the extreme of an extinction-level event — in our problem profile on preventing an AI-related catastrophe.
“These fears need to be addressed, and I think can be addressed,” the senator continued. “I’ve come to the conclusion that we need some kind of regulatory agency.”
And the senator from Connecticut isn’t the only one:

Back in 2007, Holden Karnofsky cofounded GiveWell, where he sought out the charities that most cost-effectively helped save lives. He then cofounded Open Philanthropy, where he oversaw a team making billions of dollars’ worth of grants across a range of areas: pandemic control, criminal justice reform, farmed animal welfare, and making AI safe, among others. This year, having learned about AI for years and observed recent events, he’s narrowing his focus once again, this time on making the transition to advanced AI go well.
In today’s conversation, Holden returns to the show to share his overall understanding of the promise and the risks posed by machine intelligence, and what to do about it. That understanding has accumulated over around 14 years, during which he went from being sceptical that AI was important or risky, to making AI risks the focus of his work.
(As Holden reminds us, his wife is also the president of one of the world’s top AI labs, Anthropic, giving him both conflicts of interest and a front-row seat to recent events. For our part, Open Philanthropy is 80,000 Hours’ largest financial supporter.)
One point he makes is that people are too narrowly focused on AI becoming ‘superintelligent.’ While that could happen and would be important, it’s not necessary for AI to be transformative or perilous. Rather, machines with human levels of intelligence could end up being enormously influential simply if the amount of computer hardware globally were able to operate tens or hundreds of billions of them, in a sense making machine intelligences a majority of the global population, or at least a majority of global thought.
As Holden explains, he sees four key parts to the playbook humanity should use to guide the transition to very advanced AI in a positive direction: alignment research, standards and monitoring, creating a successful and careful AI lab, and finally, information security.
In today’s episode, host Rob Wiblin interviews return guest Holden Karnofsky about that playbook, as well as:
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris
Audio Engineering Lead: Ben Cordell
Technical editing: Simon Monsour and Milo McGuire
Transcriptions: Katy Moore

The idea this week: thinking about which world problem is most pressing may matter more than you realise.
I’m an advisor for 80,000 Hours, which means I talk to a lot of thoughtful people who genuinely want to have a positive impact with their careers. One piece of advice I consistently find myself giving is to consider working on pressing world problems you might not have explored yet.
Should you work on climate change or AI risk? Mitigating antibiotic resistance or preventing bioterrorism? Preventing disease in low-income countries or reducing the harms of factory farming?
Your choice of problem area can matter a lot. But I think a lot of people under-invest in building a view of which problems they think are most pressing.
I think there are three main reasons for this:
1. They think they can’t get a job working on a certain problem, so the argument that it’s important doesn’t seem relevant.
I see this most frequently with AI. People think that they don’t have aptitude or interest in machine learning, so they wouldn’t be able to contribute to mitigating catastrophic risks from AI.

In Oppenheimer, scientists detonate a nuclear weapon despite thinking there’s some ‘near zero’ chance it would ignite the atmosphere, putting an end to life on Earth. Today, scientists working on AI think the chance their work puts an end to humanity is vastly higher than that.
In response, some have suggested we launch a Manhattan Project to make AI safe via enormous investment in relevant R&D. Others have suggested that we need international organisations modelled on those that slowed the proliferation of nuclear weapons. Others still seek a research slowdown by labs while an auditing and licencing scheme is created.
Today’s guest — journalist Ezra Klein of The New York Times — has watched policy discussions and legislative battles play out in DC for 20 years. Like many people he has also taken a big interest in AI this year, writing articles such as “This changes everything.” In his first interview on the show in 2021, he flagged AI as one topic that DC would regret not having paid more attention to.
So we invited him on to get his take on which regulatory proposals have promise, and which seem either unhelpful or politically unviable.
Out of the ideas on the table right now, Ezra favours a focus on direct government funding — both for AI safety research and to develop AI models designed to solve problems other than making money for their operators. He is sympathetic to legislation that would require AI models to be legible in a way that none currently are — and embraces the fact that that will slow down the release of models while businesses figure out how their products actually work.
By contrast, he’s pessimistic that it’s possible to coordinate countries around the world to agree to prevent or delay the deployment of dangerous AI models — at least not unless there’s some spectacular AI-related disaster to create such a consensus. And he fears attempts to require licences to train the most powerful ML models will struggle unless they can find a way to exclude and thereby appease people working on relatively safe consumer technologies rather than cutting-edge research.
From observing how DC works, Ezra expects that even a small community of experts in AI governance can have a large influence on how the the US government responds to AI advances. But in Ezra’s view, that requires those experts to move to DC and spend years building relationships with people in government, rather than clustering elsewhere in academia and AI labs.
In today’s brisk conversation, Ezra and host Rob Wiblin cover the above as well as:
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris
Audio Engineering Lead: Ben Cordell
Technical editing: Milo McGuire
Transcriptions: Katy Moore

This is Part 3 of an updated version of a classic three-part series of 80,000 Hours blog posts. You can also read updated versions of Part 1 and Part 2. You can still read the original version of the series published in 2012.
It’s fair to say working as a doctor does not look that great so far. In general, the day-to-day work of medicine has had a relatively minor role in why people are living longer and healthier now than they did historically. When we try and quantify the benefit of someone becoming a doctor, the figure gets lower the better the method of estimation and already is low enough such that a 40-year medical career somewhere like the UK would be on a rough par with giving $20,000 dollars to a GiveWell top charity in terms of saving lives.
Yet there is more to say. The tools we have used to arrive at estimates are general, so they are estimating something like the impact of the modal, median, or typical medical career. There are doctors who have plainly done much more good than my estimates of the impact of a typical doctor.
So, what could a doctor do to really save a lot of lives?
Doing doctoring better
What about just being really, really good? Even if the typical doctor’s work makes a worthwhile — but modest and fairly replaceable — contribution,
This is Part 2 of an updated version of a classic three-part series of 80,000 Hours blog posts. You can also read updated versions of Part 1 and Part 3. You can still read the original version of the series published in 2012.
In the last post, we saw that although the reasons people live longer and healthier now have more to do with higher living standards than more medical care, medicine still plays a part. If you try and quantify how much medicine contributes to our increased longevity and health, then divide that amount by the number of doctors providing it, you get an estimate that a UK doctor saves ~70 lives over the course of their career.
Yet this won’t be a good model of how much good you would actually do if you became a doctor in the UK.
For one thing, the relationship between more doctors and better health is non-linear. Here’s a scatterplot for each country with doctors per capita on the x-axis and DALYs per capita on the y-axis (since you ‘gain’ DALYs for dying young or being sick, less is better):
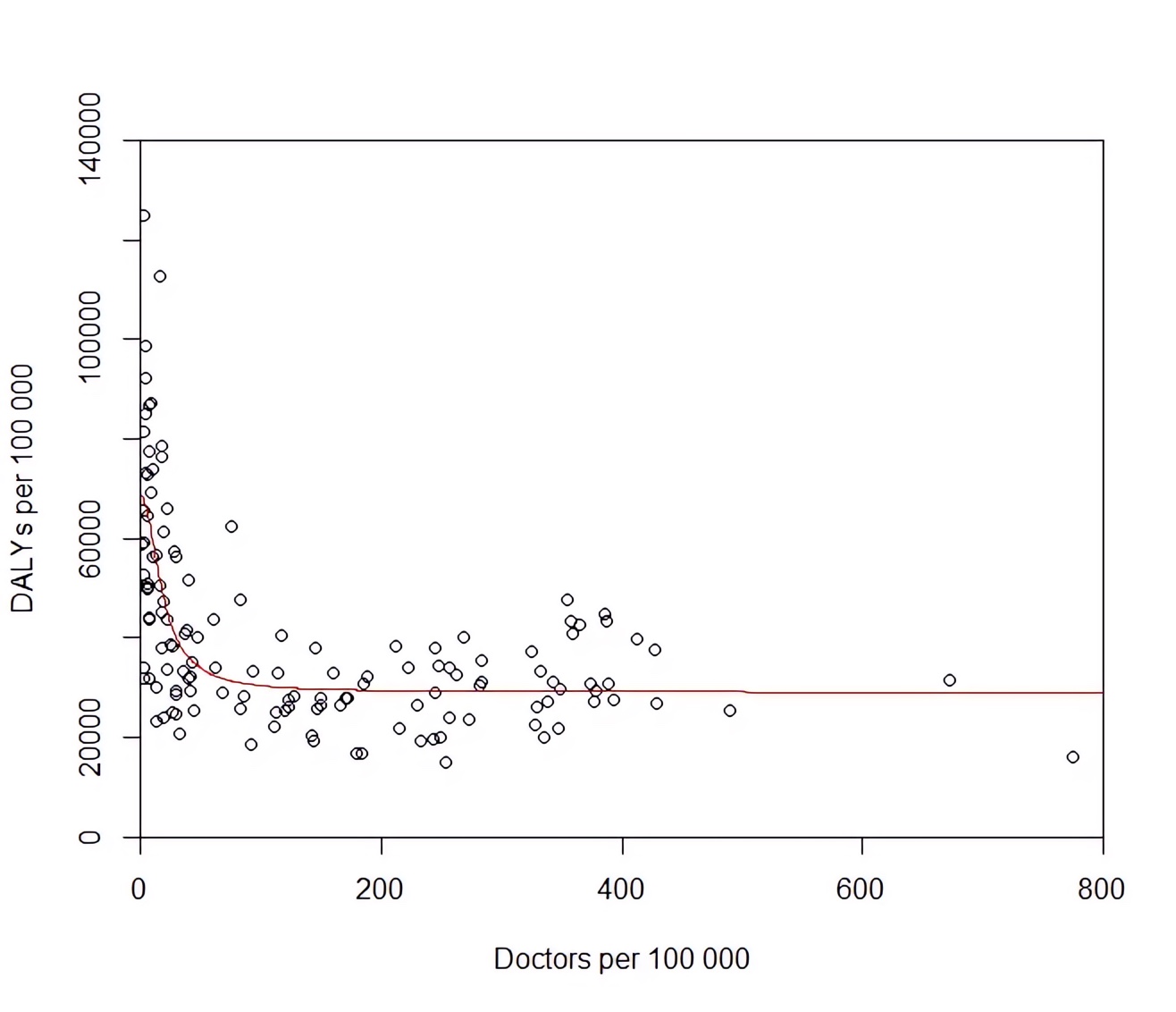
The association shows an initial steep decline between 0–50 doctors per 100,000 people, then levels off abruptly and is basically flat when you get to physician densities in richer countries (e.g. the UK has 300 doctors per 100,000 people). Assuming this is causation rather than correlation (more on that later),

This is Part 1 of an updated version of a classic three-part series of 80,000 Hours blog posts. You can also read updated versions of Part 2 and Part 3. You can still read the original version of the series published in 2012.
Doctors have a reputation as do-gooders. So when I was a 17-year-old kid wanting to make a difference, it seemed like a natural career path. I wrote this on my medical school application:
I want to study medicine because of a desire I have to help others, and so the chance of spending a career doing something worthwhile I can’t resist. Of course, Doctors [sic] don’t have a monopoly on altruism, but I believe the attributes I have lend themselves best to medicine, as opposed to all the other work I could do instead.
They still let me in.
When I show this to others in medicine, I get a mix of laughs and groans of recognition. Most of them wrote something similar. The impression I get from senior doctors who have to read this stuff is they see it a bit like a toddler zooming around on their new tricycle: a mostly endearing (if occasionally annoying) work in progress. Season them enough with the blood, sweat, and tears of clinical practice, and they’ll generally turn out as wiser, perhaps more cantankerous, but ultimately humane doctors.
Yet more important than me being earnest — and even me being trite — was that I was wrong.

In this episode of 80k After Hours, Luisa Rodriguez and Hannah Boettcher discuss various approaches to therapy, and how to use them in practice — focusing specifically on people trying to have a big impact.
They cover:
Who this episode is for:
Who this episode isn’t for:
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris
Audio Engineering Lead: Ben Cordell
Technical editing: Dominic Armstrong
Content editing: Katy Moore, Luisa Rodriguez, and Keiran Harris
Transcriptions: Katy Moore
“Gershwin – Rhapsody in Blue, original 1924 version” by Jason Weinberger is licensed under creative commons

In today’s episode, host Luisa Rodriguez interviews the Head of Policy at the Centre for the Governance of AI — Markus Anderljung — about all aspects of policy and governance of superhuman AI systems.
They cover:
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris
Audio Engineering Lead: Ben Cordell
Technical editing: Simon Monsour and Milo McGuire
Transcriptions: Katy Moore

A new great power war could be catastrophic for humanity — but there are meaningful ways to reduce the risk.
We’re now in the 17th month of the war in Ukraine. But at the start, it was hard to foresee it would last this long. Many expected Russian troops to take Ukraine’s capital, Kyiv, in weeks. Already, more than 100,000 people, including civilians, have been killed and over 300,000 more injured. Many more will die before the war ends.
The sad and surprising escalation of the war shows why international conflict remains a major global risk. I explain why working to lower the danger is a potentially high-impact career choice in a new problem profile on great power war.
As Russia’s disastrous invasion demonstrates, it’s hard to predict how much a conflict will escalate. Most wars remain relatively small, but a few will become terrifyingly large. US officials estimate about 70,000 Russian and Ukrainian soldiers have died in battle so far. That means this war is already worse than 80% of all the wars humanity has experienced in the last 200 years.
But the worst wars humanity has fought are hundreds of times larger than the war in Ukraine currently is. World War II killed 66 million people, for example — perhaps the single deadliest event in human history.
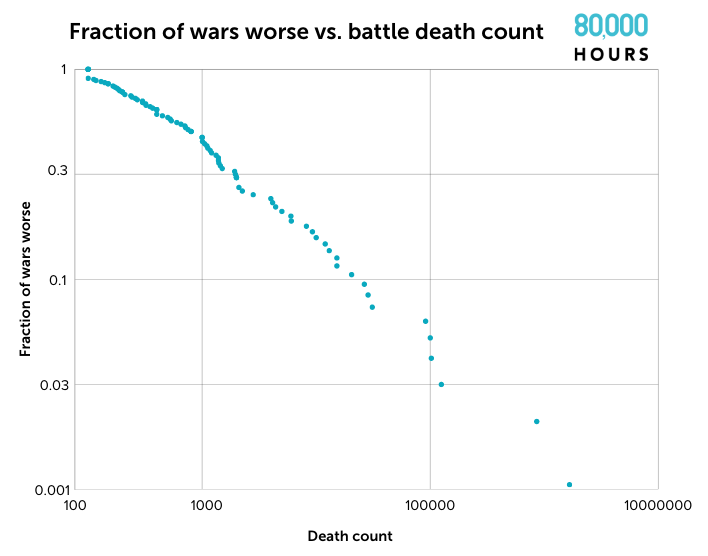
Author’s figure. See the data here.

As AI advances ever more quickly, concerns about potential misuse of highly capable models are growing. From hostile foreign governments and terrorists to reckless entrepreneurs, the threat of AI falling into the wrong hands is top of mind for the national security community.
With growing concerns about the use of AI in military applications, the US has banned the export of certain types of chips to China.
But unlike the uranium required to make nuclear weapons, or the material inputs to a bioweapons programme, computer chips and machine learning models are absolutely everywhere. So is it actually possible to keep dangerous capabilities out of the wrong hands?
In today’s interview, Lennart Heim — who researches compute governance at the Centre for the Governance of AI — explains why limiting access to supercomputers may represent our best shot.
As Lennart explains, an AI research project requires many inputs, including the classic triad of compute, algorithms, and data.
If we want to limit access to the most advanced AI models, focusing on access to supercomputing resources — usually called ‘compute’ — might be the way to go. Both algorithms and data are hard to control because they live on hard drives and can be easily copied. By contrast, advanced chips are physical items that can’t be used by multiple people at once and come from a small number of sources.
According to Lennart, the hope would be to enforce AI safety regulations by controlling access to the most advanced chips specialised for AI applications. For instance, projects training ‘frontier’ AI models — the newest and most capable models — might only gain access to the supercomputers they need if they obtain a licence and follow industry best practices.
We have similar safety rules for companies that fly planes or manufacture volatile chemicals — so why not for people producing the most powerful and perhaps the most dangerous technology humanity has ever played with?
But Lennart is quick to note that the approach faces many practical challenges. Currently, AI chips are readily available and untracked. Changing that will require the collaboration of many actors, which might be difficult, especially given that some of them aren’t convinced of the seriousness of the problem.
Host Rob Wiblin is particularly concerned about a different challenge: the increasing efficiency of AI training algorithms. As these algorithms become more efficient, what once required a specialised AI supercomputer to train might soon be achievable with a home computer.
By that point, tracking every aggregation of compute that could prove to be very dangerous would be both impractical and invasive.
With only a decade or two left before that becomes a reality, the window during which compute governance is a viable solution may be a brief one. Top AI labs have already stopped publishing their latest algorithms, which might extend this ‘compute governance era’, but not for very long.
If compute governance is only a temporary phase between the era of difficult-to-train superhuman AI models and the time when such models are widely accessible, what can we do to prevent misuse of AI systems after that point?
Lennart and Rob both think the only enduring approach requires taking advantage of the AI capabilities that should be in the hands of police and governments — which will hopefully remain superior to those held by criminals, terrorists, or fools. But as they describe, this means maintaining a peaceful standoff between AI models with conflicting goals that can act and fight with one another on the microsecond timescale. Being far too slow to follow what’s happening — let alone participate — humans would have to be cut out of any defensive decision-making.
Both agree that while this may be our best option, such a vision of the future is more terrifying than reassuring.
Lennart and Rob discuss the above as well as:
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris
Audio mastering: Milo McGuire, Dominic Armstrong, and Ben Cordell
Transcriptions: Katy Moore

Governments, foundations, and individuals spend large amounts of effort and money to improve the world. However, a lot more research could be done to help figure out how to use it best.
Global priorities research can take many forms, using techniques from economics, philosophy, maths, and social science to help people and organisations choose which global problems they should spend their limited resources on, in order to improve the world as much as possible.

The idea this week: getting rejected from jobs can be crushing — but learning how to deal with rejection productively is an incredibly valuable skill.
I’ve been rejected many, many times. In 2015, I applied to ten PhD programs and was rejected from nine. After doing a summer internship with GiveWell in 2016, I wasn’t offered a full-time role. In 2017, I was rejected by J-PAL, IDinsight, and Founders Pledge (among others). Around the same time, I was so afraid of being rejected by Open Philanthropy, I dropped out of their hiring round.
I now have what I consider a dream job at 80,000 Hours: I get to host a podcast about the world’s most pressing problems and how to solve them. But before getting a job offer from 80,000 Hours in 2020, I got rejected by them for a role in 2018. That rejection hurt the most.
I still remember compulsively checking my phone after my work trial to see if 80,000 Hours had made me an offer. And I still remember waking up at 5:00 AM, checking my email, and finding the kind and well-written — but devastating — rejection: “Unfortunately we don’t think the role is the right fit right now.”
And I remember being so sad that I took a five-hour bus ride to stay with a friend so I wouldn’t have to be alone.

Can there be a more exciting and strange place to work today than a leading AI lab? Your CEO has said they’re worried your research could cause human extinction. The government is setting up meetings to discuss how this outcome can be avoided. Some of your colleagues think this is all overblown; others are more anxious still.
Today’s guest — machine learning researcher Rohin Shah — goes into the Google DeepMind offices each day with that peculiar backdrop to his work.
He’s on the team dedicated to maintaining ‘technical AI safety’ as these models approach and exceed human capabilities: basically that the models help humanity accomplish its goals without flipping out in some dangerous way. This work has never seemed more important.
In the short-term it could be the key bottleneck to deploying ML models in high-stakes real-life situations. In the long-term, it could be the difference between humanity thriving and disappearing entirely.
For years Rohin has been on a mission to fairly hear out people across the full spectrum of opinion about risks from artificial intelligence — from doomers to doubters — and properly understand their point of view. That makes him unusually well placed to give an overview of what we do and don’t understand. He has landed somewhere in the middle — troubled by ways things could go wrong, but not convinced there are very strong reasons to expect a terrible outcome.
Today’s conversation is wide-ranging and Rohin lays out many of his personal opinions to host Rob Wiblin, including:
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris
Audio mastering: Milo McGuire, Dominic Armstrong, and Ben Cordell
Transcriptions: Katy Moore