Blog post by Stephen Clare · Published June 30th, 2023
A new great power war could be catastrophic for humanity — but there are meaningful ways to reduce the risk.
We’re now in the 17th month of the war in Ukraine. But at the start, it was hard to foresee it would last this long. Many expected Russian troops to take Ukraine’s capital, Kyiv, in weeks. Already, more than 100,000 people, including civilians, have been killed and over 300,000 more injured. Many more will die before the war ends.
The sad and surprising escalation of the war shows why international conflict remains a major global risk. I explain why working to lower the danger is a potentially high-impact career choice in a new problem profile on great power war.
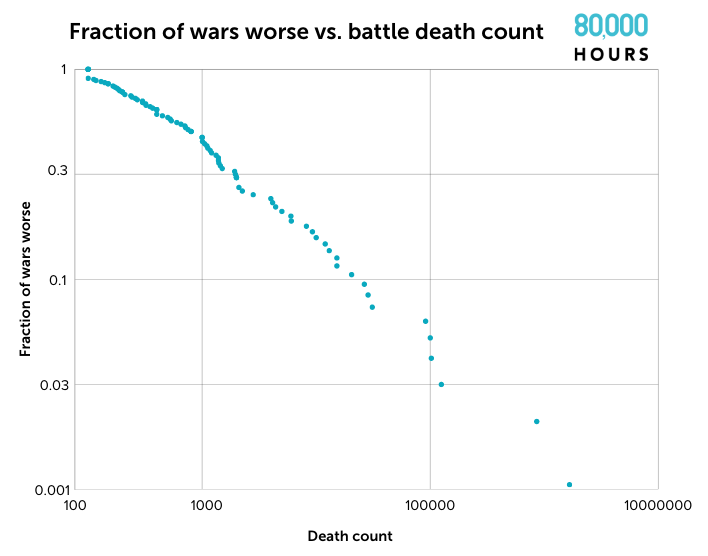
As Russia’s disastrous invasion demonstrates, it’s hard to predict how much a conflict will escalate. Most wars remain relatively small, but a few will become terrifyingly large. US officials estimate about 70,000 Russian and Ukrainian soldiers have died in battle so far. That means this war is already worse than 80% of all the wars humanity has experienced in the last 200 years.
But the worst wars humanity has fought are hundreds of times larger than the war in Ukraine currently is. World War II killed 66 million people, for example — perhaps the single deadliest event in human history.
Author’s figure. See the data here. Data source: Sarkees,
As AI advances ever more quickly, concerns about potential misuse of highly capable models are growing. From hostile foreign governments and terrorists to reckless entrepreneurs, the threat of AI falling into the wrong hands is top of mind for the national security community.
With growing concerns about the use of AI in military applications, the US has banned the export of certain types of chips to China.
But unlike the uranium required to make nuclear weapons, or the material inputs to a bioweapons programme, computer chips and machine learning models are absolutely everywhere. So is it actually possible to keep dangerous capabilities out of the wrong hands?
In today’s interview, Lennart Heim — who researches compute governance at the Centre for the Governance of AI — explains why limiting access to supercomputers may represent our best shot.
As Lennart explains, an AI research project requires many inputs, including the classic triad of compute, algorithms, and data.
If we want to limit access to the most advanced AI models, focusing on access to supercomputing resources — usually called ‘compute’ — might be the way to go. Both algorithms and data are hard to control because they live on hard drives and can be easily copied. By contrast, advanced chips are physical items that can’t be used by multiple people at once and come from a small number of sources.
According to Lennart, the hope would be to enforce AI safety regulations by controlling access to the most advanced chips specialised for AI applications. For instance, projects training ‘frontier’ AI models — the newest and most capable models — might only gain access to the supercomputers they need if they obtain a licence and follow industry best practices.
We have similar safety rules for companies that fly planes or manufacture volatile chemicals — so why not for people producing the most powerful and perhaps the most dangerous technology humanity has ever played with?
But Lennart is quick to note that the approach faces many practical challenges. Currently, AI chips are readily available and untracked. Changing that will require the collaboration of many actors, which might be difficult, especially given that some of them aren’t convinced of the seriousness of the problem.
Host Rob Wiblin is particularly concerned about a different challenge: the increasing efficiency of AI training algorithms. As these algorithms become more efficient, what once required a specialised AI supercomputer to train might soon be achievable with a home computer.
By that point, tracking every aggregation of compute that could prove to be very dangerous would be both impractical and invasive.
With only a decade or two left before that becomes a reality, the window during which compute governance is a viable solution may be a brief one. Top AI labs have already stopped publishing their latest algorithms, which might extend this ‘compute governance era’, but not for very long.
If compute governance is only a temporary phase between the era of difficult-to-train superhuman AI models and the time when such models are widely accessible, what can we do to prevent misuse of AI systems after that point?
Lennart and Rob both think the only enduring approach requires taking advantage of the AI capabilities that should be in the hands of police and governments — which will hopefully remain superior to those held by criminals, terrorists, or fools. But as they describe, this means maintaining a peaceful standoff between AI models with conflicting goals that can act and fight with one another on the microsecond timescale. Being far too slow to follow what’s happening — let alone participate — humans would have to be cut out of any defensive decision-making.
Both agree that while this may be our best option, such a vision of the future is more terrifying than reassuring.
Lennart and Rob discuss the above as well as:
How can we best categorise all the ways AI could go wrong?
Why did the US restrict the export of some chips to China and what impact has that had?
Is the US in an ‘arms race’ with China or is that more an illusion?
What is the deal with chips specialised for AI applications?
How is the ‘compute’ industry organised?
Downsides of using compute as a target for regulations
Could safety mechanisms be built into computer chips themselves?
Who would have the legal authority to govern compute if some disaster made it seem necessary?
The reasons Rob doubts that any of this stuff will work
Could AI be trained to operate as a far more severe computer worm than any we’ve seen before?
What does the world look like when sluggish human reaction times leave us completely outclassed?
And plenty more
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris Audio mastering: Milo McGuire, Dominic Armstrong, and Ben Cordell Transcriptions: Katy Moore
Problem profile by Stephen Clare · Published June 2023
Economic growth and technological progress have bolstered the arsenals of the world’s most powerful countries. That means the next war between them could be far worse than World War II, the deadliest conflict humanity has yet experienced.
Could such a war actually occur? We can’t rule out the possibility. Technical accidents or diplomatic misunderstandings could spark a conflict that quickly escalates. Or international tension could cause leaders to decide they’re better off fighting than negotiating.
It seems hard to make progress on this problem. It’s also less neglected than some of the problems that we think are most pressing. There are certain issues, like making nuclear weapons or military artificial intelligence systems safer, which seem promising — although it may be more impactful to work on reducing risks from AI, bioweapons or nuclear weapons directly. You might also be able to reduce the chances of misunderstandings and miscalculations by developing expertise in one of the most important bilateral relationships (such as that between the United States and China).
Finally, by making conflict less likely, reducing competitive pressures on the development of dangerous technology, and improving international cooperation, you might be helping to reduce other risks, like the chance of future pandemics.
The idea this week: getting rejected from jobs can be crushing — but learning how to deal with rejection productively is an incredibly valuable skill.
I’ve been rejected many, many times. In 2015, I applied to ten PhD programs and was rejected from nine. After doing a summer internship with GiveWell in 2016, I wasn’t offered a full-time role. In 2017, I was rejected by J-PAL, IDinsight, and Founders Pledge (among others). Around the same time, I was so afraid of being rejected by Open Philanthropy, I dropped out of their hiring round.
I now have what I consider a dream job at 80,000 Hours: I get to host a podcast about the world’s most pressing problems and how to solve them. But before getting a job offer from 80,000 Hours in 2020, I got rejected by them for a role in 2018. That rejection hurt the most.
I still remember compulsively checking my phone after my work trial to see if 80,000 Hours had made me an offer. And I still remember waking up at 5:00 AM, checking my email, and finding the kind and well-written — but devastating — rejection: “Unfortunately we don’t think the role is the right fit right now.”
And I remember being so sad that I took a five-hour bus ride to stay with a friend so I wouldn’t have to be alone.
Can there be a more exciting and strange place to work today than a leading AI lab? Your CEO has said they’re worried your research could cause human extinction. The government is setting up meetings to discuss how this outcome can be avoided. Some of your colleagues think this is all overblown; others are more anxious still.
Today’s guest — machine learning researcher Rohin Shah — goes into the Google DeepMind offices each day with that peculiar backdrop to his work.
He’s on the team dedicated to maintaining ‘technical AI safety’ as these models approach and exceed human capabilities: basically that the models help humanity accomplish its goals without flipping out in some dangerous way. This work has never seemed more important.
In the short-term it could be the key bottleneck to deploying ML models in high-stakes real-life situations. In the long-term, it could be the difference between humanity thriving and disappearing entirely.
For years Rohin has been on a mission to fairly hear out people across the full spectrum of opinion about risks from artificial intelligence — from doomers to doubters — and properly understand their point of view. That makes him unusually well placed to give an overview of what we do and don’t understand. He has landed somewhere in the middle — troubled by ways things could go wrong, but not convinced there are very strong reasons to expect a terrible outcome.
Today’s conversation is wide-ranging and Rohin lays out many of his personal opinions to host Rob Wiblin, including:
What he sees as the strongest case both for and against slowing down the rate of progress in AI research.
Why he disagrees with most other ML researchers that training a model on a sensible ‘reward function’ is enough to get a good outcome.
Why he disagrees with many on LessWrong that the bar for whether a safety technique is helpful is “could this contain a superintelligence.”
That he thinks nobody has very compelling arguments that AI created via machine learning will be dangerous by default, or that it will be safe by default. He believes we just don’t know.
That he understands that analogies and visualisations are necessary for public communication, but is sceptical that they really help us understand what’s going on with ML models, because they’re different in important ways from every other case we might compare them to.
Why he’s optimistic about DeepMind’s work on scalable oversight, mechanistic interpretability, and dangerous capabilities evaluations, and what each of those projects involves.
Why he isn’t inherently worried about a future where we’re surrounded by beings far more capable than us, so long as they share our goals to a reasonable degree.
Why it’s not enough for humanity to know how to align AI models — it’s essential that management at AI labs correctly pick which methods they’re going to use and have the practical know-how to apply them properly.
Three observations that make him a little more optimistic: humans are a bit muddle-headed and not super goal-orientated; planes don’t crash; and universities have specific majors in particular subjects.
Plenty more besides.
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris Audio mastering: Milo McGuire, Dominic Armstrong, and Ben Cordell Transcriptions: Katy Moore
Career review by Jarrah Bloomfield · Last updated June 2023 · First published December 2022
As the 2016 US presidential campaign was entering a fractious round of primaries, Hillary Clinton’s campaign chair, John Podesta, opened a disturbing email. The March 19 message warned that his Gmail password had been compromised and that he urgently needed to change it.
The email was a lie. It wasn’t trying to help him protect his account — it was a phishing attack trying to gain illicit access.
Podesta was suspicious, but the campaign’s IT team erroneously wrote the email was “legitimate” and told him to change his password. The IT team provided a safe link for Podesta to use, but it seems he or one of his staffers instead clicked the link in the forged email. That link was used by Russian intelligence hackers known as “Fancy Bear,” and they used their access to leak private campaign emails for public consumption in the final weeks of the 2016 race, embarrassing the Clinton team.
While there are plausibly many critical factors in any close election, it’s possible that the controversy around the leaked emails played a non-trivial role in Clinton’s subsequent loss to Donald Trump. This would mean the failure of the campaign’s security team to prevent the hack — which might have come down to a mere typo — was extraordinarily consequential.
These events vividly illustrate how careers in infosecurity at key organisations have the potential for outsized impact. Ideally, security professionals can develop robust practices that reduce the likelihood that a single slip-up will result in a significant breach.
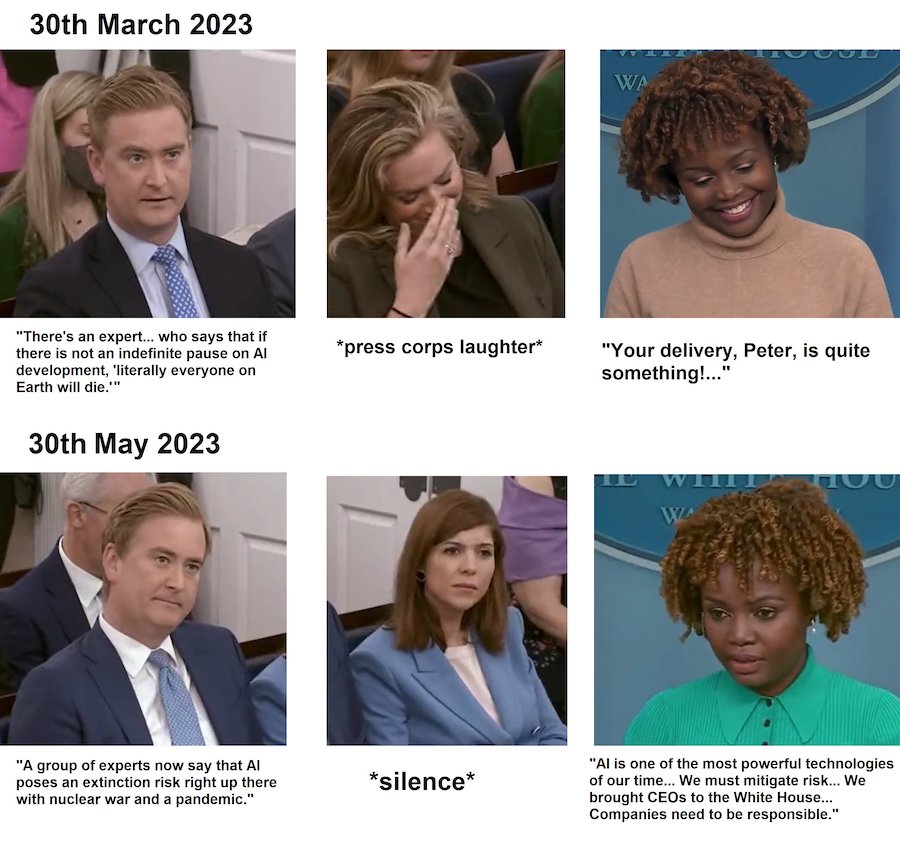
Last Tuesday’s statement on AI risk has hit headlines across the world. Hundreds of leading AI scientists and other prominent figures — including the CEOs of OpenAI, Anthropic and Google DeepMind — signed the one-sentence statement:
Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.
This mainstreaming of concerns about the risk of extinction from AI represents a substantial shift to the strategic landscape — and should, as a result, have implications on how best to reduce the risk.
Pictures from the White House Press Briefing. Meme from @kristjanmoore. The relevant video is here.
So far, I think the most significant effect of the changes in the way these risks are viewed can be seen in changes in political activity.
World leaders — including Joe Biden, Rishi Sunak, Emmanuel Macron — have all met leaders in AI in the last few months. AI regulation was a key topic of discussion at the G7. And now it’s been announced that Biden and Sunak will discuss extinction risks from AI as part of talks in DC next week.
At the moment, it’s extremely unclear where this discussion will go.
GiveWell is one of the world’s best-known charity evaluators, with the goal of “searching for the charities that save or improve lives the most per dollar.” It mostly recommends projects that help the world’s poorest people avoid easily prevented diseases, like intestinal worms or vitamin A deficiency.
But should GiveWell, as some critics argue, take a totally different approach to its search, focusing instead on directly increasing subjective wellbeing, or alternatively, raising economic growth?
Today’s guest — cofounder and CEO of GiveWell, Elie Hassenfeld — is proud of how much GiveWell has grown in the last five years. Its ‘money moved’ has quadrupled to around $600 million a year.
Its research team has also more than doubled, enabling them to investigate a far broader range of interventions that could plausibly help people an enormous amount for each dollar spent. That work has led GiveWell to support dozens of new organisations, such as Kangaroo Mother Care, MiracleFeet, and Dispensers for Safe Water.
But some other researchers focused on figuring out the best ways to help the world’s poorest people say GiveWell shouldn’t just do more of the same thing, but rather ought to look at the problem differently.
Currently, GiveWell uses a range of metrics to track the impact of the organisations it considers recommending — such as ‘lives saved,’ ‘household incomes doubled,’ and for health improvements, the ‘quality-adjusted life year.’ To compare across opportunities, it then needs some way of weighing these different types of benefits up against one another. This requires estimating so-called “moral weights,” which Elie agrees is far from the most mature part of the project.
The Happier Lives Institute (HLI) has argued that instead, GiveWell should try to cash out the impact of all interventions in terms of improvements in subjective wellbeing. According to HLI, it’s improvements in wellbeing and reductions in suffering that are the true ultimate goal of all projects, and if you quantify everyone on this same scale, using some measure like the wellbeing-adjusted life year (WELLBY), you have an easier time comparing them.
This philosophy has led HLI to be more sceptical of interventions that have been demonstrated to improve health, but whose impact on wellbeing has not been measured, and to give a high priority to improving lives relative to extending them.
An alternative high-level critique is that really all that matters in the long run is getting the economies of poor countries to grow. According to this line of argument, hundreds of millions fewer people live in poverty in China today than 50 years ago, but is that because of the delivery of basic health treatments? Maybe a little), but mostly not.
Rather, it’s because changes in economic policy and governance in China allowed it to experience a 10% rate of economic growth for several decades. That led to much higher individual incomes and meant the country could easily afford all the basic health treatments GiveWell might otherwise want to fund, and much more besides.
On this view, GiveWell should focus on figuring out what causes some countries to experience explosive economic growth while others fail to, or even go backwards. Even modest improvements in the chances of such a ‘growth miracle’ will likely offer a bigger bang-for-buck than funding the incremental delivery of deworming tablets or vitamin A supplements, or anything else.
Elie sees where both of these critiques are coming from, and notes that they’ve influenced GiveWell’s work in some ways. But as he explains, he thinks they underestimate the practical difficulty of successfully pulling off either approach and finding better opportunities than what GiveWell funds today.
In today’s in-depth conversation, Elie and host Rob Wiblin cover the above, as well as:
The research that caused GiveWell to flip from not recommending chlorine dispensers as an intervention for safe drinking water to spending tens of millions of dollars on them.
What transferable lessons GiveWell learned from investigating different kinds of interventions, like providing medical expertise to hospitals in very poor countries to help them improve their practices.
Why the best treatment for premature babies in low-resource settings may involve less rather than more medicine.
The high prevalence of severe malnourishment among children and what can be done about it.
How to deal with hidden and non-obvious costs of a programme, like taking up a hospital room that might otherwise have been used for something else.
Some cheap early treatments that can prevent kids from developing lifelong disabilities, which GiveWell funds.
The various roles GiveWell is currently hiring for, and what’s distinctive about their organisational culture.
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris Audio mastering: Simon Monsour and Ben Cordell Transcriptions: Katy Moore
Blog post by Arden Koehler · Published May 26th, 2023
What does the public think about risks of human extinction?
We care a lot about reducing extinction risks and think doing so is one of the best ways you can have a positive impact with your career. But even before considering career impact, it can be natural to worry about these risks — and as it turns out, many people do!
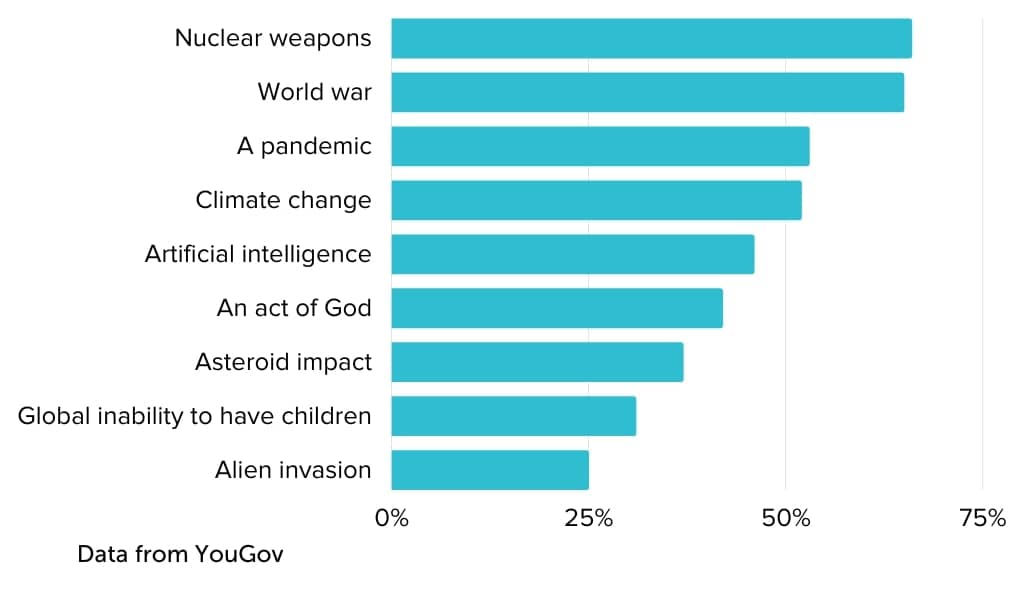
In April 2023, the US firm YouGov polled 1,000 American adults on how worried they were about nine different potential extinction threats. It found the following percentages of respondents were either “concerned” or “very concerned” about extinction from each threat:
We’re particularly interested in this poll now because we have recently updated our page on the world’s most pressing problems, which includes several of these extinction risks at the top.
Knowing how the public feels about these kinds of threats can impact how we communicate about them.
For example, if we take the results at face value, 46% of the poll’s respondents are concerned about human extinction caused by artificial intelligence. Maybe this surprisingly high figure means we don’t need to worry as much as we have over the last 10 years about sounding like ‘sci fi’ when we talk about existential risks from AI, since it’s quickly becoming a common concern!
How does our view of the world’s most pressing problems compare?
We’ve spent the last few months updating 80,000 Hours’ career guide (which we previously released in 2017 and which you’ve been able to get as a physical book). This week, we’ve put our new career guide live on our website. Before we formally launch and promote the guide — and republish the book — we’d like to gather feedback from our readers!
Note that our target audience for this career guide is approximately the ~100k young adults most likely to have high-impact careers, in the English-speaking world. Many of them may not yet be familiar with many of the ideas that are widely discussed in the effective altruism community. Also, this guide is primarily aimed at people aged 18–24.
When you’re ready, there’s a simple form to fill in:
Our key ideas series had a more serious tone, and was more focused on impact. It represented our best and most up-to-date advice. We expected that this switch would reduce engagement time on our site, but that the key ideas series would better appeal to people more likely to change their careers to do good.
What is the nature of the universe? How do we make decisions correctly? What differentiates right actions from wrong ones?
Such fundamental questions have been the subject of philosophical and theological debates for millennia. But, as we all know, and surveys of expert opinion make clear, we are very far from agreement. So… with these most basic questions unresolved, what’s a species to do?
In today’s episode, philosopher Joe Carlsmith — Senior Research Analyst at Open Philanthropy — makes the case that many current debates in philosophy ought to leave us confused and humbled. These are themes he discusses in his PhD thesis, A stranger priority? Topics at the outer reaches of effective altruism.
To help transmit the disorientation he thinks is appropriate, Joe presents three disconcerting theories — originating from him and his peers — that challenge humanity’s self-assured understanding of the world.
The first idea is that we might be living in a computer simulation, because, in the classic formulation, if most civilisations go on to run many computer simulations of their past history, then most beings who perceive themselves as living in such a history must themselves be in computer simulations. Joe prefers a somewhat different way of making the point, but, having looked into it, he hasn’t identified any particular rebuttal to this ‘simulation argument.’
If true, it could revolutionise our comprehension of the universe and the way we ought to live.
The second is the idea that “you can ‘control’ events you have no causal interaction with, including events in the past.” The thought experiment that most persuades him of this is the following:
Perfect deterministic twin prisoner’s dilemma: You’re a deterministic AI system, who only wants money for yourself (you don’t care about copies of yourself). The authorities make a perfect copy of you, separate you and your copy by a large distance, and then expose you both, in simulation, to exactly identical inputs (let’s say, a room, a whiteboard, some markers, etc.). You both face the following choice: either (a) send a million dollars to the other (“cooperate”), or (b) take a thousand dollars for yourself (“defect”).
Joe thinks, in contrast with the dominant theory of correct decision-making, that it’s clear you should send a million dollars to your twin. But as he explains, this idea, when extrapolated outwards to other cases, implies that it could be sensible to take actions in the hope that they’ll improve parallel universes you can never causally interact with — or even to improve the past. That is nuts by anyone’s lights, including Joe’s.
The third disorienting idea is that, as far as we can tell, the universe could be infinitely large. And that fact, if true, would mean we probably have to make choices between actions and outcomes that involve infinities. Unfortunately, doing that breaks our existing ethical systems, which are only designed to accommodate finite cases.
In an infinite universe, our standard models end up unable to say much at all, or give the wrong answers entirely. While we might hope to patch them in straightforward ways, having looked into ways we might do that, Joe has concluded they all quickly get complicated and arbitrary, and still have to do enormous violence to our common sense. For people inclined to endorse some flavour of utilitarianism, Joe thinks ‘infinite ethics’ spell the end of the ‘utilitarian dream‘ of a moral philosophy that has the virtue of being very simple while still matching our intuitions in most cases.
These are just three particular instances of a much broader set of ideas that some have dubbed the “train to crazy town.” Basically, if you commit to always take philosophy and arguments seriously, and try to act on them, it can lead to what seem like some pretty crazy and impractical places. So what should we do with this buffet of plausible-sounding but bewildering arguments?
Joe and Rob discuss to what extent this should prompt us to pay less attention to philosophy, and how we as individuals can cope psychologically with feeling out of our depth just trying to make the most basic sense of the world.
In the face of all of this, Joe suggests that there is a promising and robust path for humanity to take: keep our options open and put our descendants in a better position to figure out the answers to questions that seem impossible for us to resolve today — a position he calls “wisdom longtermism.”
Joe fears that if people believe we understand the universe better than we really do, they’ll be more likely to try to commit humanity to a particular vision of the future, or be uncooperative to others, in ways that only make sense if you were certain you knew what was right and wrong.
In today’s challenging conversation, Joe and Rob discuss all of the above, as well as:
What Joe doesn’t like about the drowning child thought experiment
An alternative thought experiment about helping a stranger that might better highlight our intrinsic desire to help others
What Joe doesn’t like about the expression “the train to crazy town”
Whether Elon Musk should place a higher probability on living in a simulation than most other people
Whether the deterministic twin prisoner’s dilemma, if fully appreciated, gives us an extra reason to keep promises
To what extent learning to doubt our own judgement about difficult questions — so-called “epistemic learned helplessness” — is a good thing
How strong the case is that advanced AI will engage in generalised power-seeking behaviour
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris Audio mastering: Milo McGuire and Ben Cordell Transcriptions: Katy Moore
Imagine you are an orphaned eight-year-old whose parents left you a $1 trillion company, and no trusted adult to serve as your guide to the world. You have to hire a smart adult to run that company, guide your life the way that a parent would, and administer your vast wealth. You have to hire that adult based on a work trial or interview you come up with. You don’t get to see any resumes or do reference checks. And because you’re so rich, tonnes of people apply for the job — for all sorts of reasons.
Today’s guest Ajeya Cotra — senior research analyst at Open Philanthropy — argues that this peculiar setup resembles the situation humanity finds itself in when training very general and very capable AI models using current deep learning methods.
As she explains, such an eight-year-old faces a challenging problem. In the candidate pool there are likely some truly nice people, who sincerely want to help and make decisions that are in your interest. But there are probably other characters too — like people who will pretend to care about you while you’re monitoring them, but intend to use the job to enrich themselves as soon as they think they can get away with it.
Like a child trying to judge adults, at some point humans will be required to judge the trustworthiness and reliability of machine learning models that are as goal-oriented as people, and greatly outclass them in knowledge, experience, breadth, and speed. Tricky!
Can’t we rely on how well models have performed at tasks during training to guide us? Ajeya worries that it won’t work. The trouble is that three different sorts of models will all produce the same output during training, but could behave very differently once deployed in a setting that allows their true colours to come through. She describes three such motivational archetypes:
Saints — models that care about doing what we really want
Sycophants — models that just want us to say they’ve done a good job, even if they get that praise by taking actions they know we wouldn’t want them to
Schemers — models that don’t care about us or our interests at all, who are just pleasing us so long as that serves their own agenda
In principle, a machine learning training process based on reinforcement learning could spit out any of these three attitudes, because all three would perform roughly equally well on the tests we give them, and ‘performs well on tests’ is how these models are selected.
But while that’s true in principle, maybe it’s not something that could plausibly happen in the real world. After all, if we train an agent based on positive reinforcement for accomplishing X, shouldn’t the training process spit out a model that plainly does X and doesn’t have complex thoughts and goals beyond that?
According to Ajeya, this is one thing we don’t know, and should be trying to test empirically as these models get more capable. For reasons she explains in the interview, the Sycophant or Schemer models may in fact be simpler and easier for the learning algorithm to creep towards than their Saint counterparts.
But there are also ways we could end up actively selecting for motivations that we don’t want.
For a toy example, let’s say you train an agent AI model to run a small business, and select it for behaviours that make money, measuring its success by whether it manages to get more money in its bank account. During training, a highly capable model may experiment with the strategy of tricking its raters into thinking it has made money legitimately when it hasn’t. Maybe instead it steals some money and covers that up. This isn’t exactly unlikely; during training, models often come up with creative — sometimes undesirable — approaches that their developers didn’t anticipate.
If such deception isn’t picked up, a model like this may be rated as particularly successful, and the training process will cause it to develop a progressively stronger tendency to engage in such deceptive behaviour. A model that has the option to engage in deception when it won’t be detected would, in effect, have a competitive advantage.
What if deception is picked up, but just some of the time? Would the model then learn that honesty is the best policy? Maybe. But alternatively, it might learn the ‘lesson’ that deception does pay, but you just have to do it selectively and carefully, so it can’t be discovered. Would that actually happen? We don’t yet know, but it’s possible.
In today’s interview, Ajeya and Rob discuss the above, as well as:
How to predict the motivations a neural network will develop through training
Whether AIs being trained will functionally understand that they’re AIs being trained, the same way we think we understand that we’re humans living on planet Earth
Stories of AI misalignment that Ajeya doesn’t buy into
Analogies for AI, from octopuses to aliens to can openers
Why it’s smarter to have separate planning AIs and doing AIs
The benefits of only following through on AI-generated plans that make sense to human beings
What approaches for fixing alignment problems Ajeya is most excited about, and which she thinks are overrated
How one might demo actually scary AI failure mechanisms
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris Audio mastering: Ryan Kessler and Ben Cordell Transcriptions: Katy Moore
Following the bankruptcy of FTX and the federal indictment of Sam Bankman-Fried, many members of the team at 80,000 Hours were deeply shaken. As we have said, we had previously featured Sam on our site as a positive example of earning to give, a mistake we now regret. We felt appalled by his conduct and at the harm done to the people who had relied on FTX.
These events were emotionally difficult for many of us on the team, and we were troubled by the implications it might have for our attempts to do good in the world. We had linked our reputation with his, and his conduct left us with serious questions about effective altruism and our approach to impactful careers.
We reflected a lot, had many difficult conversations, and worked through a lot of complicated questions. There’s still a lot we don’t know about what happened, there’s a diversity of views within the 80,000 Hours team, and we expect the learning process to be ongoing.
Ultimately, we still believe strongly in the principles that drive our work, and we stand by the vast majority of our advice. But we did make some significant updates in our thinking, and we’ve changed many parts of the site to reflect them. We wrote this post to summarise the site updates we’ve made and to explain the motivations behind them, for transparency purposes and to further highlight the themes that unify the changes.
It’s easy to dismiss alarming AI-related predictions when you don’t know where the numbers came from.
For example: what if we told you that within 15 years, it’s likely that we’ll see a 1,000x improvement in AI capabilities in a single year? And what if we then told you that those improvements would lead to explosive economic growth unlike anything humanity has seen before?
You might think, “Congratulations, you said a big number — but this kind of stuff seems crazy, so I’m going to keep scrolling through Twitter.”
But this 1,000x yearly improvement is a prediction based on real economic models created by today’s guest Tom Davidson, Senior Research Analyst at Open Philanthropy. By the end of the episode, you’ll either be able to point out specific flaws in his step-by-step reasoning, or have to at least consider the idea that the world is about to get — at a minimum — incredibly weird.
As a teaser, consider the following:
Developing artificial general intelligence (AGI) — AI that can do 100% of cognitive tasks at least as well as the best humans can — could very easily lead us to an unrecognisable world.
You might think having to train AI systems individually to do every conceivable cognitive task — one for diagnosing diseases, one for doing your taxes, one for teaching your kids, etc. — sounds implausible, or at least like it’ll take decades.
But Tom thinks we might not need to train AI to do every single job — we might just need to train it to do one: AI research.
And building AI capable of doing research and development might be a much easier task — especially given that the researchers training the AI are AI researchers themselves.
And once an AI system is as good at accelerating future AI progress as the best humans are today — and we can run billions of copies of it round the clock — it’s hard to make the case that we won’t achieve AGI very quickly.
To give you some perspective: 17 years ago we saw the launch of Twitter, the release of Al Gore’s An Inconvenient Truth, and your first chance to play the Nintendo Wii.
Tom thinks that if we have AI that significantly accelerates AI R&D, then it’s hard to imagine not having AGI 17 years from now.
Wild.
Host Luisa Rodriguez gets Tom to walk us through his careful reports on the topic, and how he came up with these numbers, across a terrifying but fascinating three hours.
Luisa and Tom also discuss:
How we might go from GPT-4 to AI disaster
Tom’s journey from finding AI risk to be kind of scary to really scary
Whether international cooperation or an anti-AI social movement can slow AI progress down
Why it might take just a few years to go from pretty good AI to superhuman AI
How quickly the number and quality of computer chips we’ve been using for AI have been increasing
The pace of algorithmic progress
What ants can teach us about AI
And much more
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris Audio mastering: Simon Monsour and Ben Cordell Transcriptions: Katy Moore
Blog post by Benjamin Todd · Published May 5th, 2023
Here’s one of the deepest tensions in doing good:
How much should you do what seems right to you, even if it seems extreme or controversial, vs how much should you moderate your views and actions based on other perspectives?
If you moderate too much, you won’t be doing anything novel or ambitious, which really reduces how much impact you might have. The people who have had the biggest impact historically often spoke out about entrenched views and were met with hostility — think of the civil rights movement or Galileo.
Moreover, simply following ethical ‘common sense’ has a horrible track record. It used to be common sense to think that homosexuality was evil, slavery was the natural order, and that the environment was there for us to exploit.
And there is still so much wrong with the world. Millions of people die of easily preventable diseases, society is deeply unfair, billions of animals are tortured in factory farms, and we’re gambling our entire future by failing to mitigate threats like climate change. These huge problems deserve radical action — while conventional wisdom appears to accept doing little about them.
On a very basic level, doing more good is better than doing less. But this is a potentially endless and demanding principle, and most people don’t give it much attention or pursue it very systematically. So it wouldn’t be surprising if a concern for doing good led you to positions that seem radical or unusual to the rest of society.
Blog post by Cody Fenwick · Published April 28th, 2023
Information security could be a top option for people looking to have a high-impact career.
This might be a surprising claim — information security is a relatively niche field, and it doesn’t typically appear on canonical lists of do-gooder careers.
But we think there’s an unusually strong case that information security skills (which allow you to protect against unauthorised use, hacking, leaks, and tampering) will be key to addressing problems that are extremely important, neglected, and tractable. We now rank this career among the highest-impact paths we’ve researched.
In the introduction to our recently updated career review of information security, we discuss how poor information security decisions may have played a decisive role in the 2016 US presidential campaign. If an organisation is big and influential, it needs good information security to ensure that it functions as intended. This is true whether it’s a political campaign, a major corporation, a biolab, or an AI company.
That’s because hackers and cyberattacks — from a range of actors with varying motives — could try to steal crucial information, such as instructions for making a super-virus or the details of an extremely powerful AI model.
In this episode of 80k After Hours, Luisa Rodriguez and Keiran Harris chat about the consequences of letting go of enduring guilt, shame, anger, and pride.
They cover:
Keiran’s views on free will, and how he came to hold them
What it’s like not experiencing sustained guilt, shame, and anger
Whether Luisa would become a worse person if she felt less guilt and shame, specifically whether she’d work fewer hours, or donate less money, or become a worse friend
Whether giving up guilt and shame also means giving up pride
The implications for love
The neurological condition ‘Jerk Syndrome’
And some practical advice on feeling less guilt, shame, and anger
Who this episode is for:
People sympathetic to the idea that free will is an illusion
People who experience tons of guilt, shame, or anger
People worried about what would happen if they stopped feeling tons of guilt, shame, or anger
Who this episode isn’t for:
People strongly in favour of retributive justice
Philosophers who can’t stand random non-philosophers talking about philosophy
Non-philosophers who can’t stand random non-philosophers talking about philosophy
Get this episode by subscribing to our more experimental podcast on the world’s most pressing problems and how to solve them: type ’80k After Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris Audio mastering: Milo McGuire Transcriptions: Katy Moore
Blog post by Cody Fenwick · Published April 21st, 2023
COVID-19 has been devastating for the world. While people debate how the response could’ve been better, it should be easy to agree that we’d all be better off if we can stop any future pandemic before it occurs. But we’re still not taking pandemic prevention very seriously.
A recent report in The Washington Post highlighted one major danger: some research on potential pandemic pathogens may actually increase the risk, rather than reduce it.
Back in 2017, we talked about what we thought were several warning signs that something like COVID might be coming down the line. It’d be a big mistake to ignore these kinds of warning signs again.
It seems unfortunate that so much of the discussion of the risks in this space is backward-looking. The news has been filled with commentary and debates about the chances that COVID accidentally emerged from a biolab or that it crossed over directly from animals to humans.
We’d appreciate a definitive answer to this question as much as anyone, but there’s another question that matters much more but gets asked much less:
What are we doing to reduce the risk that the next dangerous virus — which could come from an animal, a biolab, or even a bioterrorist attack — causes a pandemic even worse than COVID-19?
Blog post by Benjamin Todd · Published April 18th, 2023
In career decisions, we advise that you don’t aim for confidence — aim for a stable best guess.
Career decisions have a big impact on your life, so it’s natural to want to feel confident in them.
Unfortunately, you don’t always get this luxury.
For years, I’ve faced the decision of whether to focus more on writing, organisation building, or something else. And despite giving it a lot of thought, I’ve rarely felt more than 60% confident in one of the options.
How should you handle these kinds of situations?
The right response isn’t just to guess, flip a coin, or “follow your heart.”
It’s still worth identifying your key uncertainties, and doing your research: speak to people, do side projects, learn about each path, etc.
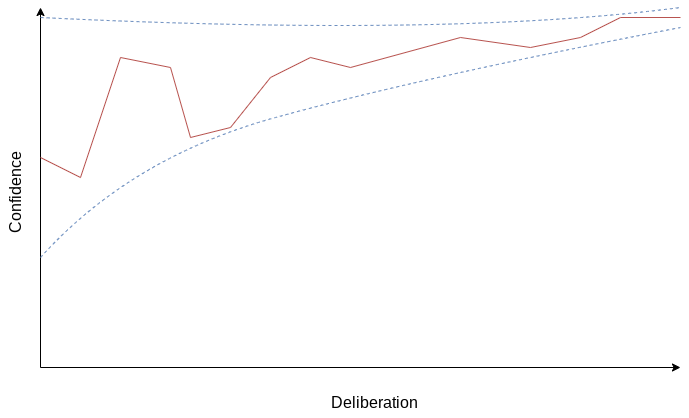
Sometimes you’ll quickly realise one answer is best. If we plot your confidence against how much research you’ve done, it’ll look like this:
But sometimes that doesn’t happen. What then?
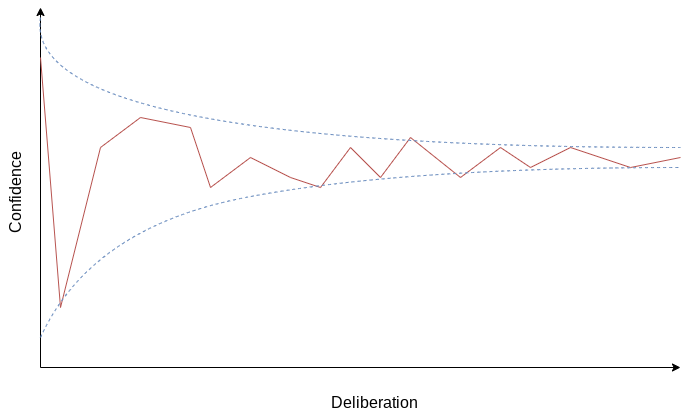
Stop your research when your best guess stops changing.
That might look more like this:
This can be painful. You might only be 51% confident in your best guess, and it really sucks to have to make a decision when you feel so uncertain.
But certainty is not always achievable. You might face questions that both (i) are important but (ii) can’t realistically be resolved — which I think is the situation I faced.
Being a good and successful person is core to your identity. You place great importance on meeting the high moral, professional, or academic standards you set yourself.
But inevitably, something goes wrong and you fail to meet that high bar. Now you feel terrible about yourself, and worry others are judging you for your failure. Feeling low and reflecting constantly on whether you’re doing as much as you think you should makes it hard to focus and get things done. So now you’re performing below a normal level, making you feel even more ashamed of yourself. Rinse and repeat.
This is the disastrous cycle today’s guest, Tim LeBon — registered psychotherapist, accredited CBT therapist, life coach, and author of 365 Ways to Be More Stoic — has observed in many clients with a perfectionist mindset.
Tim has provided therapy to a number of 80,000 Hours readers — people who have found that the very high expectations they had set for themselves were holding them back. Because of our focus on “doing the most good you can,” Tim thinks 80,000 Hours both attracts people with this style of thinking and then exacerbates it.
But Tim, having studied and written on moral philosophy, is sympathetic to the idea of helping others as much as possible, and is excited to help clients pursue that — sustainably — if it’s their goal.
Tim has treated hundreds of clients with all sorts of mental health challenges. But in today’s conversation, he shares the lessons he has learned working with people who take helping others so seriously that it has become burdensome and self-defeating — in particular, how clients can approach this challenge using the treatment he’s most enthusiastic about: cognitive behavioural therapy.
As Tim stresses, perfectionism isn’t the same as being perfect, or simply pursuing excellence. What’s most distinctive about perfectionism is that a person’s standards don’t vary flexibly according to circumstance, meeting those standards without exception is key to their self-image, and they worry something terrible will happen if they fail to meet them.
It’s a mindset most of us have seen in ourselves at some point, or have seen people we love struggle with.
Untreated, perfectionism might not cause problems for many years — it might even seem positive providing a source of motivation to work hard. But it’s hard to feel truly happy and secure, and free to take risks, when we’re just one failure away from our self-worth falling through the floor. And if someone slips into the positive feedback loop of shame described above, the end result can be depression and anxiety that’s hard to shake.
But there’s hope. Tim has seen clients make real progress on their perfectionism by using CBT techniques like exposure therapy. By doing things like experimenting with more flexible standards — for example, sending early drafts to your colleagues, even if it terrifies you — you can learn that things will be okay, even when you’re not perfect.
In today’s extensive conversation, Tim and Rob cover:
How perfectionism is different from the pursuit of excellence, scrupulosity, or an OCD personality
What leads people to adopt a perfectionist mindset
The pros and cons of perfectionism
How 80,000 Hours contributes to perfectionism among some readers and listeners, and what it might change about its advice to address this
What happens in a session of cognitive behavioural therapy for someone struggling with perfectionism, and what factors are key to making progress
Experiments to test whether one’s core beliefs (‘I need to be perfect to be valued’) are true
Using exposure therapy to treat phobias
How low-self esteem and imposter syndrome are related to perfectionism
Stoicism as an approach to life, and why Tim is enthusiastic about it
How the Stoic approach to what we can can’t control can make it far easier to stay calm
What the Stoics do better than utilitarian philosophers and vice versa
What’s good about being guided by virtues as opposed to pursuing good consequences
How to decide which are the best virtues to live by
What the ancient Stoics got right from our point of view, and what they got wrong
And whether Stoicism has a place in modern mental health practice.
Get this episode by subscribing to our podcast on the world’s most pressing problems and how to solve them: type ‘80,000 Hours’ into your podcasting app. Or read the transcript below.
Producer: Keiran Harris Audio mastering: Simon Monsour and Ben Cordell Transcriptions: Katy Moore